ИИ освоил игру с несовершенной информацией Стратего

В июне 2022 года DeepMind выпустил статью научного коллектива «Освоение игры Стратего с мультиагентным обучением с подкреплением без модели». Стратего относится к играм с несовершенной информацией, которые представляют научный интерес для развития искусственного интеллекта.
Эта настольная игра предполагает наличие двух игроков, где каждый участник пытается захватить флаг противника. В отличие от игр с совершенной информацией, таких как шахматы или Го, правильный ход в Стратего должен учитывать характер и поведение личности, а решения принимаются быстро и инстинктивно, часто на основе отдельных действий без очевидной связи между действием и результатом. Поэтому в игре может быть множество эпизодов с возможностями длинных многоходовых комбинаций, которые не могут быть разбиты на подзадачи, как, например, в покере.
Два основных вызова Стратего для ИИ заключаются в количестве возможных состояний и количестве возможных расстановок в начале игры. Для сравнения, в первом случае в Стратего их 10535, в Го – 10364, в покере – 10164. А начало игры в покере предполагает всего 103 возможных пар карт, в то время как в Стратего количество расстановок насчитывает 10164 .
Основная цель научной статьи состоит в изучении равновесия Нэша посредством игры с самим собой. Равновесие Нэша1Равновесие Нэша – тип решений игры двух и более игроков, в котором ни один участник не может увеличить выигрыш, изменив своё решение в одностороннем порядке, когда другие участники не меняют решения. Такая совокупность стратегий, выбранных участниками и их выигрыши называются равновесием Нэша. Равновесие Нэша соответствует решениям, на которых завершается динамика наилучших результатов. гарантирует, что агент ИИ будет действовать эффективно даже при столкновении с противником в наихудшей позиции.
Авторами представлен автономный агент DeepNash, который работая с несовершенной информацией может развивать человеческий опыт, и, соответственно, навык работы с определением шансов. В основе DeepNash лежит базовая обучающая часть – R-NaD (регулярная динамика Нэша)2Регулярная динамика Нэша ‑ методика обучения с подкреплением без использования моделей. Кроме этого, DeepNash включает тонкую настройку обнаружения и постобработку во время тестирования. DeepNash может эффективно скрывать информацию от других противников, корректируя компромиссные варианты в свою пользу. Агент также может обманывать противников и блефовать, когда это необходимо.
DeepNash достигает равновесия Нэша за счет интеграции R-NaD со структурой глубокой нейронной сети (см Рис.1). R-NaD, базовый алгоритм RLRL3(Reinforcement Learning) – обучение с подкреплением. без модели обучения, реализуется с использованием Deep Neural Network, а затем настраивается для устранения вероятностных ошибок.
Рис. 1. Схема метода DeepNash
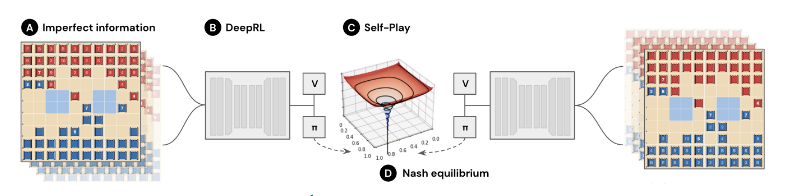
Метод обучения основан на концепции регуляризации для конвергенции4Регуляризация – это техника, которая уменьшает ошибки модели, избегая переоснащения и обучая модель правильному функционированию.. Тонкая настройка осуществляется на протяжении всего обучения путем дополнительной пороговой обработки и дискретного распределения вероятностей действий.
В частности, при физической игре в Стратего двух людей они видят расположение и тип своих фигур и только расположение фигур противника. Тип фигуры можно узнать только если она атакует или подвергается нападению. Движение фигуры также означает, что она не Флаг и не Бомба. Игроки должны это запоминать. DeepNash имеет более обширные наблюдения. Например, определенные перемещения фигуры будут запоминаться как перемещение типа фигуры.
DeepNash также может создать миллиарды непредсказуемых развертываний, обрабатывать ситуации со случайным, негативным или сложным блефом, взвешивать ценность взятия фигуры противника и предоставления информации о своей фигуре и сравнение этой возможности с сокрытием типа фигуры.
Эффективность DeepNash оценивается на платформе Gravon и в состязании с восьмью игровыми ботами. При этом, агент не тренировался против какого-либо из ботов, а обучался самостоятельно. В результате, в начале апреля 2022 года было проведено 50 рейтинговых матчей, в которых DeepNash набрал 42% и занял 3 место среди всех игроков Gravon Stratego и также 3 место среди всех игроков с рейтингом. На платформе Gravon DeepNash имеет минимальный процент побед 97% против других ботов с искусственным интеллектом и общий коэффициент выигрыша 84% против игроков-экспертов. DeepNash может открыть новые возможности для методов обучения с подкреплением в задачах реального мира с несовершенной информацией и неисчислимым количеством состояний.
- 1Равновесие Нэша – тип решений игры двух и более игроков, в котором ни один участник не может увеличить выигрыш, изменив своё решение в одностороннем порядке, когда другие участники не меняют решения. Такая совокупность стратегий, выбранных участниками и их выигрыши называются равновесием Нэша. Равновесие Нэша соответствует решениям, на которых завершается динамика наилучших результатов.
- 2Регулярная динамика Нэша ‑ методика обучения с подкреплением без использования моделей
- 3(Reinforcement Learning) – обучение с подкреплением.
- 4Регуляризация – это техника, которая уменьшает ошибки модели, избегая переоснащения и обучая модель правильному функционированию.
Похожие записи:
 Риски и угрозы, сопутствующие развитию индустрии киберспорта и гейминга
Риски и угрозы, сопутствующие развитию индустрии киберспорта и гейминга
 Подходы к регулированию внутриигровой собственности и обороту игровой валюты в странах мира
Подходы к регулированию внутриигровой собственности и обороту игровой валюты в странах мира
 Объяснимый искусственный интеллект
Объяснимый искусственный интеллект
 Семантический анализ для автоматической обработки естественного языка
Семантический анализ для автоматической обработки естественного языка
 Компьютерное зрение: технологии, компании, тренды
Компьютерное зрение: технологии, компании, тренды