Семантический анализ для автоматической обработки естественного языка

Семантический анализ – важная подзадача обработки естественного языка (Natural language processing, NLP), этап в последовательности действий алгоритма автоматического понимания текстов, заключающийся в выделении семантических отношений, формировании семантического представления текстов. В общем случае семантическое представление является графом, семантической сетью, отражающей бинарные отношения между двумя узлами — смысловыми единицами текста.
В ходе анализа текст проходит через несколько этапов обработки: токенизация для идентификации словоформ, морфологический, синтаксический анализ. Последним этапом идет вторичный семантический анализ (первичный анализ в основном происходит параллельно морфологическому), в ходе которого устанавливаются взаимосвязи между сущностями, происходит извлечение мнений и анализ тональности текста. Основной целью анализа тональности является не только определение настроений, но также уровень объективности высказывания.
Семантический анализ применяется, например, для создания чат-ботов, поисковых систем и в задачах анализа тональности текста. В ходе семантического анализа с помощью векторного представления слов также может осуществляться поиск смысловых копий как между отдельными предложениями, так и между текстами.
В стеке технологий ИИ анализ текста является одним из наиболее развитых направлений. Высокого уровня точности достигают классификаторы текста (фильтрация контента также может быть причислена к частному случаю классификации), современные модели генерируют текст приближенно к уровню естественного языка. Наиболее сложной является задача анализа тональности, особенно в части определения иронии и сарказма. Неоднозначные или ошибочные результаты работы модели могут быть вызваны необходимостью анализа контекста, а не только конкретного высказывания.
Для автоматизированного анализа текстов используются как довольно простые регрессионные модели, так и последние разработки в сфере нейросетей.
Крупные компании во всем мире создают собственные сервисы анализа текста, развивают собственные экосистемы. Среди опубликованных российских проектов следует отметить языковую модель RuBERT от DeepPavlov, которую использует большинство российских разработчиков, и проект RussianSuperGlue, предназначенный для тестирования русскоязычных моделей NLP. Также существуют закрытые решения от Яндекс, МРГ и других крупных игроков.
Оглавление
Автоматическая обработка текста
Архитектуры нейронных сетей для решения задач NLP
Приложения и модели для обработки текста
IBM Watson Natural Language Understanding
Microsoft Azure Text Analytics
MeaningCloud Sentiment Analysis API
Twinword Sentiment Analysis API
Проблемы обработки естественного языка
Открытость данных исследований
Определение тональности, иронии и сарказма
Термины и определения
|
Дискурсивный анализ текста |
Разрешение анафорических ссылок (нахождение правильного антецедента для анафорического местоимения), установление кореферентных последовательностей, а также восстановление эллиптических конструкций. |
|
Имплицитная информация |
Информация, не составляющая непосредственного значения компонентов текста (слов, граммем и т.д.). Имплицитная информация служит для выражения неявного смысла текста или высказывания, отличительным признаком которой, выступает необязательность ее получения при понимании, неполное ее восстановление слушающим. |
|
Клауза |
В синтаксисе: составляющая, вершиной которой является глагол либо, в случае отсутствия глагола, связка или элемент, играющий её роль. |
|
Кореферентность |
Отношение между именами — компонентами высказывания, в котором имена ссылаются на один и тот же объект (ситуацию) внеязыковой действительности |
|
Корпус |
Подобранная и обработанная по определённым правилам совокупность текстов, используемых в качестве базы для исследования языка. |
|
Корпусная лингвистика |
Раздел языкознания, занимающийся разработкой, созданием и использованием текстовых корпусов. |
|
Лемма |
Словарная форма слова |
|
Несвободные словосочетания |
Состоят из лексически несамостоятельных слов, т.е. из слов с ослабленным или утраченным лексическим значением. Такие словосочетания по своей семантике и функции особенно близки отдельному слову. |
|
Онтология предметной области |
Множество концептов предметной области, множество отношений между концептами, функции интерпретации, заданные на сущностях и/или отношениях онтологии. Структура предметной онтологии должна отражать структуру предметной области. |
|
Семантика текста |
Направление, рассматривающее содержательную сторону текста, структурирование смыслов, выраженных эксплицитно и имплицитно |
|
Стемминг |
Процесс нахождения основы слова для заданного исходного слова, не обязательно совпадает с морфологическим корнем слова. |
|
Токенизация |
Разбиение текста на слова и не-слова, т.е. знаки препинания, границы абзацев и т.п. |
|
Эксплицитная информация |
Информация, выведенная из значения слов в тексте или высказывании, которые представлены в словаре и поэтому понятны реципиенту. Эксплицитная информация в тексте может быть представлена в форме эксплицитных утверждений, под которыми понимаются утверждения, которые несут информацию, непосредственно вытекающую из словарных значений употребленных в высказывании слов, то есть такие, содержание которых можно установить из поверхностной формы высказывания, непосредственно не проводя дополнительных смысловых преобразований. |
|
Эллиптические конструкции |
Конструкции (предложения), в которых формально недостающий член не восстанавливается из внешнего контекста или ситуации, а подсказывается внутренним контекстом, то есть наличными членами предложения. |
|
Эмбеддинг |
Сопоставление произвольной сущности (например, слов или других языковых сущностей) некоторому вектору. |
Семантические системы
Простейшие программы, работающие с текстом, звуком или изображением обрабатывают данные, игнорируя их содержание. Их алгоритмы не ориентируются на содержание обрабатываемых файлов. Редактор работает единым образом вне зависимости от того, загружен ли в него бизнес-договор, научная статья или домашнее задание школьника.
Более сложные IT-системы чувствительны к семантике, то есть так или иначе реагируют на содержание данных. Такие системы хранят данные в виде структурированных массивов с разбиением на типы и значения. Именно структура данных прямо ассоциируется с семантикой.
Существует два способа задания семантики данных: посредством архитектуры системы, например, с помощью структуры таблиц базы данных или конфигурированием самих данных. То есть семантика данных либо жестко определяется структурой приложения, либо может быть независимой от приложения, вшитой в сами данные. Второй способ структурирования данных, когда модель данных определяется самими данными, называется семантическим.
Основной отличительной чертой семантических систем является то, что алгоритмы обработки данных задаются не архитектурой приложения (структурой БД или программным кодом), а самими данными: значения данных, их типизация и логические отношения записываются в виде массива унифицированных по формату утверждений. То есть, с одной стороны, есть формат, с помощью которого данные описывают сами себя, свою семантику, а с другой, — универсальные приложения, которые обрабатывают данные произвольной семантики при условии, что они соответствуют формату.
Семантическая разметка пока позволяет фиксировать только статическую структуру данных: описывать сущности, свойства, значения свойств сущностей, устанавливать отношения между сущностями, а также задавать правила вывода новых утверждений. То есть современная семантическая система — это универсальное хранилище данных с возможностью реализации сложного поиска и генерации новых данных, согласно содержащимся в самих данных аксиомам и правилам. Причем хранилище может быть, как распределенным (сетевым), так и локальным.
Для работы с различными моделями данных в работающее приложение не требуется вносить какие-либо изменения, необходимо только с помощью специальных языков описать структуру предметной области, то есть создать ее онтологию, и загрузить онтологию вместе с фактическими данными в приложение. Причем структура данных в любой момент может свободно модифицироваться, дополняться новыми концептами, отношениями, правилами.
Благодаря универсальному формату описания данных появляется возможность свободного взаимодействия независимых приложений. Для полноценной реализации этой возможности необходимо соблюсти два условия: использование приложениями единых словарей, содержащих определения сущностей, и поддержка приложениями уникальной идентификации сущностей, предотвращающей коллизии. Словари должны быть составлены в формате семантических данных, и их элементы также должны иметь уникальные идентификаторы. В результате появляется возможность коллективного использования онтологий и свободного (без API) обмена данными.
Автоматическая обработка текста
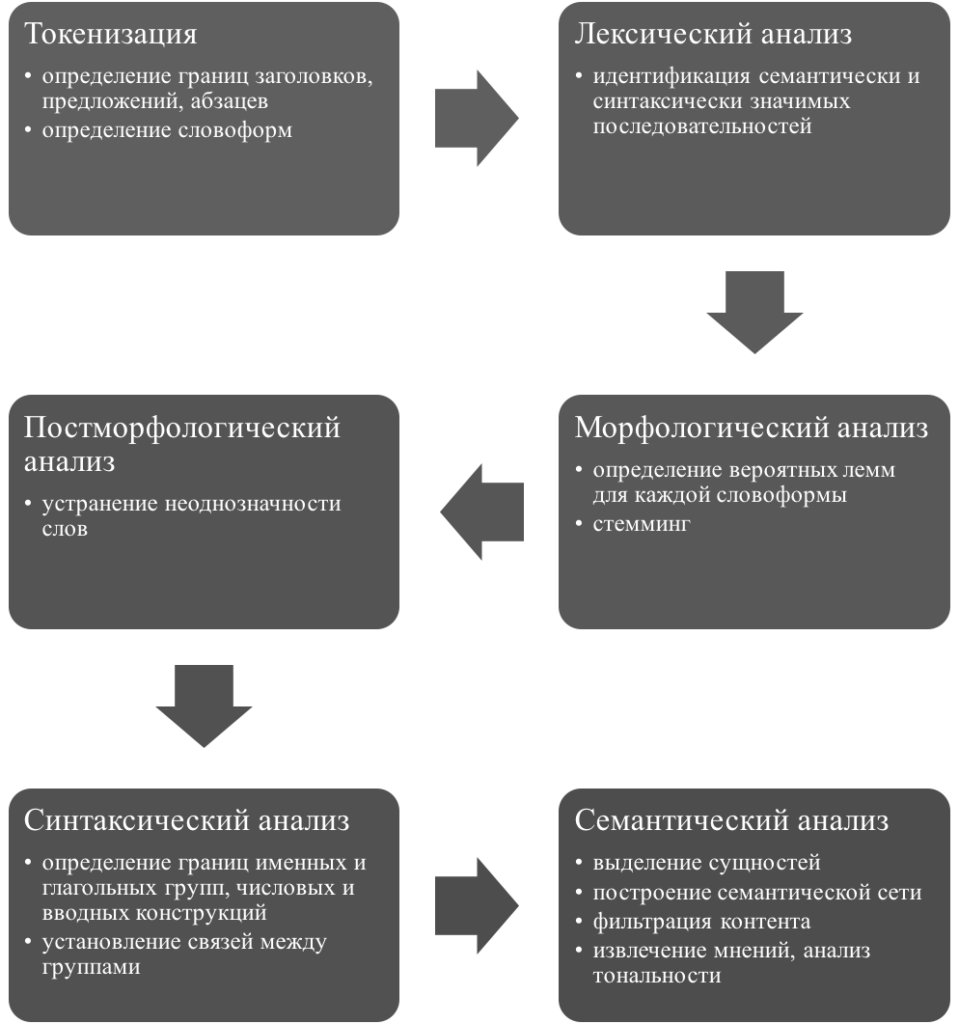
К базовым методам автоматической обработки входного текста относятся: токенизация (графематический анализ), морфологический анализ, поверхностный синтаксический анализ и локальный семантический анализ. Методы лингвистического анализа текстов можно разделить на поверхностные и глубинные. Поверхностные методы лингвистического анализа текста включают в себя предварительную обработку текста (токенизацию, морфологический анализ, постморфологический анализ) и модуль извлечения первичной семантической информации. Глубинные методы лингвистического анализа текста — это синтаксический (поверхностный и глубинный) и вторичный семантический анализ. Дискурсивный анализ текста не является обязательным на современном этапе развития компьютерной лингвистики, особенно при работе с текстами на русском языке. Он заключается в разрешении анафорических ссылок, установлении кореферентных последовательностей, а также восстановлении эллиптических конструкций, оставшихся после синтаксического анализа.
На этапе токенизации (графематического анализа) проводится первичный анализ текста исходного документа: определяются границы заголовков, абзацев и отдельных предложений. Из предложений выделяются отдельные слова — словоформы. При этом должна учитываться возможность использования разделителей в аббревиатурах и названиях.
Ключевую роль графематический анализ играет при обработке блогосферы и текстов социальных сетей, где традиционные методы, ориентированные на наличие знаков препинания, не помогают точно определять границы предложений. Наряду с графематическим анализом на этапе первичной лингвистической обработки текста проводится лексический анализ, направленный на идентификацию семантически или синтаксически значимых последовательностей. К этим последовательностям относятся, в первую очередь, адреса электронной почты (e-mail), адреса веб-сайтов (URL, URI), границы прямой речи, а также фразеологические единицы.
При морфологическом анализе для каждой словоформы строится множество вероятных лемм с морфологическими атрибутами (к морфологическим атрибутам сущности относятся: падеж, число, род, одушевленность). Каждая лемма представляет собой нормальную форму слова (именительный падеж, единственное число). В случае отсутствия формы единственного числа (грамматический класс Pluralia tantum, к которому относятся, например, названия некоторых государств (Соединенные Штаты Америки, Багамские острова)) нормальной формой является именительный падеж множественного числа. Определение нормальной формы словоформы проводится, чаще всего, на основе заранее подготовленного морфологического словаря.
Для русского языка наиболее продуктивным считается использование словаря основ, формат которого представляет собой набор лексических входов (каждый лексический вход обозначает один словоизменительный тип), состоящий из основы (или квазиосновы) слова и списка окончаний с набором грамматических атрибутов.
В случае отсутствия словоформы в словаре (в случае со словарем основ — отсутствие подходящего сочетания основы слова и окончания), либо отсутствия самого словаря, для определения постоянной части слова используется стемминг.
При наличии словаря основ задача стемминга сводится к нахождению окончания слова и приписыванию словоформе набора характеристик наиболее вероятного словоизменительного типа. Для этого, по правилам, определённым для данного языка, определяется изменяемая часть слова и заменяется усечением, допускающим любые символы.
Преимуществом стемминга является отсутствие необходимости в полном морфологическом словаре, простота реализации и скорость работы, недостатком — невысокая точность. Все результаты морфологического анализа могут быть представлены в виде XML-разметки исходного текста.
Для нужд информационно-поисковых систем целесообразно иметь минимальный набор исходных частей речи. Это обусловлено требованием полноты выдачи на поисковый запрос, который автоматически расширяется формами слов из запроса. В некоторых случаях это приводит к появлению 188 форм у глагола в русском языке. Для задач автоматического извлечения мнений, напротив, требуется более дробная классификация, при которой видовые пары глаголов являются различными леммами, наряду с причастиями и деепричастиями. В качестве причин подобного разделения можно назвать различное поведение глаголов и причастий в тексте.
На этапе постморфологического анализа снимается межчастеречная омонимия (например, словоформа «мыла» может разбираться как глагол прошедшего времени женского рода или как существительное в родительном падеже единственного числа или именительном, или винительном падежах множественного числа), а также приписывается лексико-семантическая информация (при наличии в системе автоматической обработки текста словаря семантической информации).
Устранение неоднозначности слов — автоматизированный процесс определения значения слова в соответствии с его контекстом. Очень часто для решения данной задачи используется синтаксический анализ линейной последовательности слов (анализ структуры предложения и отношения его компонентов с построением дерева зависимостей или дерева составляющих). В основе семантического анализа зависимости слова или фразы от общего контекста лежат разного рода языковые корпусы, созданные для задач корпусной лингвистики. Отдельно следует упомянуть исследования в области ассоциативной семантики, такие как теория неоднородных семантических сетей, в основе которой лежат лексические единицы, объединяемые по значениям (семантический принцип) или по выполняемым функциям (функциональный принцип). Методология ассоциативной семантики нужна для сокращения семантической многозначности путем формирования семантической модели, позволяющей восстановить общий смысл текста в условиях многозначности его фрагментов, а также вычислить и оценить степень адекватности цели, с которой был текст написан.
Прагматический анализ смысла текста требуется для учета иносказательностей, «ошибок перевода», связанных с разными культурологическими ассоциациями, понятиями и принятыми устойчивыми выражениями в контексте среды автора текста. Эта область сегодня наименее формализована, а «корпусы» практически отсутствуют. Одним из перспективных направлений работ было бы создание корпусов ассоциативных полей с временными и территориальными границами культур. Примером таких различий может быть разница в понимании символики цвета в разных культурах. Построение такого рода полей является естественным развитием ассоциативной семантики, но в случае семантического подхода ассоциации строятся главным образом на анализе баз ассоциаций лингвистических единиц или экспонентов, а в случае прагматического — на основе баз ассоциаций знаков (слов или фраз), сигнификатов (совокупность признаков предмета или явления, которые существенны для его правильного наименования данным словом в системе данного языка) и денотатов (множество объектов внеязыковой действительности. Примером может послужить цепочка: «котелок» (знак) — «емкость для приготовления пищи на огне» (описательные характеристики — сигнификат) — сам предмет или совокупность предметов (абстракций), которые могут быть названы «котелком»).
Целью синтаксического анализа текста является обнаружение синтаксической структуры текста. В большинстве задач современной компьютерной лингвистики синтаксический анализ состоит из двух этапов — поверхностного, направленного на определение границ именных и глагольных групп, и глубинного, ориентированного на установление связей между именными группами.
Одной из наиболее простых процедур поверхностного синтаксического анализа, также называемого чанкингом (от chunking — сегментирование), считается определение предложных групп. В совокупности с результатами семантического анализа анализ предложных групп способствует сокращению числа потенциальных объектов, подлежащих дальнейшему анализу.
К этапу поверхностного синтаксического анализа относятся также процедуры определения числовых конструкций (например, 10 лет) и вводных конструкций. В большинстве случаев результатов поверхностного синтаксического анализа достаточно для эффективной работы системы автоматического извлечения мнений. При этом работа глубинно-синтаксического анализа заменяется набором правил, работающих с набором именных и глагольных групп.
Глубинный синтаксический анализ направлен на выявление связей между именными и глагольными группами, а также между клаузами и несвободными оборотами. Для русского языка наибольшее распространение получило представление результатов синтаксического анализа в виде деревьев зависимостей.
Ключевым компонентом автоматического синтаксического анализа является словарь моделей управления. Традиционно подобный словарь создается для глаголов. На практике возникает необходимость также и в словаре управления для отглагольных имен, а также правила преобразования моделей управления для причастий.
Для автоматического извлечения мнений важным является не только идентификация зависимости элементов друг от друга, но и их семантическое наполнение. Учитывая текущее состояние синтаксического анализа текста на русском языке, восходящий синтаксический анализ лучше подходит для работы с нестандартными орфографическими и грамматическими вариантами. Несмотря на более низкую точность работы, восходящий анализ обеспечивает существенно большее покрытие синтаксических конструкций за счет связывания минимальных единиц.
Семантический (смысловой) анализ текста — этап в последовательности действий алгоритма автоматического понимания текстов, заключающийся в выделении семантических отношений, формировании семантического представления текстов.
Семантический анализ используется для выделения в тексте семантических единиц, т.н. сущностей. Сущности подразделяются на именованные и неименованные. Неименованными сущностями являются слова-идентификаторы классов.
К именованным сущностям относятся имена собственные, которые могут включать в себя слова-идентификаторы класса. Неименованные сущности присваиваются леммам на основе информации из семантических словарей систем автоматической обработки текста.
Для идентификации именованных сущностей применяется ряд методов, наиболее распространенными среди которых следует признать машинное обучение с учителем, онтологии и шаблоны.
Первичный семантический анализ проводится при помощи семантического словаря и, реже, онтологий. Он проводится параллельно с морфологическим анализом. Его результат используется при вторичном семантическом анализе, который учитывает синтаксическую структуру предложения.
Вторичный семантический анализ проводится с целью идентификации в тексте комплексных именованных сущностей. К комплексным сущностям относятся именованные сущности, обозначающие названия законов, предметов интеллектуальной собственности (например, книги и фильмы), названия некоторых событий (например, выставки, конференции и форумы) и ряд других.
Результатом семантического анализа текста чаще всего является семантическая сеть. Для задач автоматического извлечения мнений достаточным является идентификация сущностей верхнего уровня (которые могут иметь вложенные сущности).
Фильтрация контента не является обязательным компонентом в любой системе автоматической обработки текста. Целью этого этапа обработки текста считается сокращение ложных срабатываний системы за счет исключения из дальнейшего анализа некоторых типов данных. Компонент фильтрации html-контента относится к этапу предобработки текста. Логическим продолжением данного модуля является вторичная фильтрация контента с целью сокращения количества потенциальных объектов последующего анализа. Данный компонент фильтрации не является итоговым. В рамках определения субъектов высказывания также проводится сокращение количества объектов оценки. В данном разделе под «контентом» подразумевается лингвистическое наполнение документа, а не метаданные, которые к моменту начала работы рассматриваемого компонента уже преобразованы.
Объектная модель анализа является наиболее лингвистически обоснованной. В случаях, когда объект анализа имеет сложную структуру, необходимо использовать объект-аспектную модель. Для получения наиболее полной информации об объекте и его свойствах целесообразно анализировать объекты не изолированно, а учитывая их кореферентные отношения.
Ключевым понятием в автоматическом извлечении мнений является модель мнения. Данная модель должна наиболее полно моделировать коммуникативную ситуацию, которая подвергается анализу. По этой причине необходимо разделять отношения между объектом мнения и субъектом (носителем) мнения. При этом субъекты должны различаться от канала передачи мнения. Кроме того, полезно разделять непосредственно оценочные контексты от причинно-следственных.
Ключевым компонентом в системе извлечения мнений является словарь оценочной лексики. Данный компонент представляет собой сложный программный продукт, состоящий из нескольких баз данных, а также набора лексикализованных правил. Для различных вариантов систем автоматического извлечения мнений необходима различная организация словарного компонента.
Системы автоматической идентификации противоправного контента обладают наиболее сложной организацией как словарного компонента, так и правил отнесения контента к противоправному. Являясь частным случаем экспертных систем, системы указанного типа выступают, как правило, в виде автоматизированного рабочего места эксперта-(лингво)криминалиста.
В современных системах автоматического извлечения мнений из текстов на русском языке применяются, преимущественно, статистические методы, а задача извлечения мнений рассматривается как частный случай классификации текстов.
Общая схема обработки текста
Анализ тональности
Целью анализа тональности является определение отношения говорящего, пишущего или другого субъекта к какой-либо теме, либо общей контекстуальной полярности или эмоциональной реакции на документ, действие или событие.
Полярность является основной метрикой анализа тональности. Большинство сервисов представляют ее с помощью числа из некоторого диапазона (обычно [-1,1] или [0,1]), соответствующего диапазону между негативной и позитивной тональностью. Альтернативный подход заключается в присвоении тексту меток возможных тональностей с оценкой уверенности в каждой метке. Различные сервисы предоставляют метки различной степени детальности: тональность может быть просто «позитивной» или «негативной», или же принимать промежуточные значения, например, «слегка негативная».
Особую важность для присвоения значения тональности, означающей мнение, имеют используемые в предложении прилагательные. Отрицатели и усилители в данном контексте не менее важны.
Одним из важных различий между сервисами оценки тональности является способность определять смешанную полярность, что в случае подхода с присвоением тексту меток возможных тональностей с оценкой уверенности в них использует отдельную метку (например, «mixed»), но обычно не может быть выражено с помощью подхода с числами.
Аспектный анализ тональности (aspect-based sentiment analysis) — это подвид анализа тональности, чья задача заключается в определении отношения к конкретному аспекту основного предмета обсуждения. Все подходы к анализу тональности можно разделить на три группы.
Первая — подходы на основе правил (rule-based). Чаще всего в них используются вручную заданные правила классификации и эмоционально размеченные словари. Эти правила обычно на основе эмоциональности ключевых слов и их совместного использования с другими ключевыми словами рассчитывают класс текста. Несмотря на высокую эффективность в текстах из какой-то определенной тематики, методы на основе правил плохо обобщают. Кроме того, они крайне трудоёмки в создании, особенно когда нет доступа к подходящему словарю настроений. Последнее особенно характерно для русского языка, потому что на нем не так много источников, как на английском, особенно в сфере анализа тональности. Крупнейшие русскоязычные словари настроений — RuSentiment и LINIS Crowd. Но в них есть только информация о тональности от позитивной до негативной, без характеристик эмоций. Таким образом, не существует альтернатив таким мощным англоязычным подборкам с обширными эмоциональными характеристиками, как SenticNet, SentiWordNet и SentiWords.
Вторая группа — подходы на основе машинного обучения. Они используют автоматическое извлечение признаков из текста и применение алгоритмов машинного обучения. Классическими алгоритмами классификации полярности являются наивный байесовский классификатор, дерево решений, логистическая регрессия и метод опорных векторов. В последние годы внимание исследователей привлекают методы глубокого обучения, которые значительно превосходят традиционные методы в анализе тональности. Это подтверждается и хронологией соревнования SemEval1SemEval — один из самых авторитетных семинаров в области языкового анализа. Мероприятие спонсируется группой лексических исследований SIGLEX в рамках Ассоциации компьютерной лингвистики, одной из самых влиятельных и динамичных международных организаций в этой сфере, в ходе которого лидирующие решения успешно использовали сверточные и рекуррентные нейросети, а также методы переноса обучения (transfer learning)2Перенос обучения (трансферное обучение) предполагает использование знаний определенной обученной модели для решения схожих задач для другой модели. Одна из главных особенностей систем на основе машинного обучения — автоматическое извлечение признаков из текста.
В простых подходах для представления текста в векторном пространстве обычно используется модель «мешок слов» (bag of words). В более сложных системах для генерирования эмбеддингов слов применяются модели дистрибутивной семантики, например, Word2Vec, GloVe или FastText. Также есть алгоритмы генерирования эмбеддингов на уровне предложений или параграфов, которые предназначены для переноса обучения в разных задачах обработки естественного языка. К таким алгоритмам относятся ELMo, Universal Sentence Encoder, BERT, ERNIE и XLNet. Одним из их главных недостатков с точки зрения генерирования эмбеддингов является потребность в больших массивах текстов для обучения. Это справедливо для всех методов машинного обучения, потому что всем алгоритмам обучения с учителем нужны для обучения размеченные наборы данных.
Третья группа — гибридные подходы. Они объединяют в себе подходы двух предыдущих видов. Например, гибридный фреймворк для анализа тональности персидского языка, в котором сочетаются лингвистические правила, а также модули свёрточных нейросетей и LSTM для классификации настроений. В гибридной модели аспектного анализа ALDONAr сочетаются онтология настроений для захвата информации о настроениях, BERT для получения эмбеддингов слов и два слоя CNN для расширенной классификации тональности. Модель показала точность в 83,8% на датасете SemEval 2015 Task 12 и 87,1% на датасете SemEval 2016 Task 5.
Языковые модели часто применяются в гибридных алгоритмах, как и решения на основе правил. С одной стороны, комбинация методов на основе правил и машинного обучения обычно позволяет добиться более точных результатов. А с другой — гибридные подходы наследуют трудности и ограничения составляющих их алгоритмов.
Русскоязычные датасеты для анализа тональности
|
Датасет |
Описание |
Аннотирование |
Классы |
|---|---|---|---|
|
Набор с примерами настроений из обзоров товаров категории «Женская одежда и аксессуары» в крупном российском интернет-магазине. |
Автоматическое |
3 | |
|
Открытый набор с примерами настроений из публикаций в соцсети ВКонтакте. |
Ручное |
5 | |
|
Аспектный набор с примерами настроений из 50 329 русскоязычных обзоров отелей. |
Автоматическое |
5 | |
|
Набор с аналитическими статьями с сайта ИноСМИ, в которых представлено авторское мнение об освещаемой теме и многочисленные ссылки, упоминаемые участниками описанных ситуаций. |
Ручное |
2 | |
|
Открытый набор с примерами настроений, собранный из социальных и политических статей на сайтах различных СМИ. |
Ручное |
5 | |
|
Набор с примерами настроений, содержащий больше 1,6 млн Twitter-сообщений (их ID) на 15 языках, в том числе русском. |
Ручное |
3 | |
|
Открытый аспектный набор с примерами настроений, содержащий тексты, относящиеся к ресторанному бизнесу. Основан на SentiRuEval-2015. |
Ручное |
3 | |
|
Открытый аспектный набор с примерами настроений, содержащий результаты анализа тональности русскоязычных Twitter-сообщений о телекоммуникационных компаниях и банках. |
Ручное |
3 | |
|
Открытый аспектный набор с примерами настроений, содержащий результаты анализа пользовательских обзоров ресторанов и автомобилей. |
Ручное |
4 | |
|
Крупнейший, автоматически аннотируемый, открытый корпус текстов с небольшим ручным фильтрованием. Собран автоматически из русскоязычного Twitter с помощью стратегии. |
Автоматическое |
3 | |
|
Открытый набор с примерами настроений из российских новостей. |
Не указано |
3 | |
|
Набор с примерами настроений из российских новостей. |
Не указано |
3 | |
|
Набор с примерами настроений, опубликованный Alem Research. |
Не указано |
3 | |
|
Набор с примерами настроений из русскоязычных Twitter-сообщений. |
Не указано |
2 |
Архитектуры нейронных сетей для решения задач NLP
- Многослойный персептрон
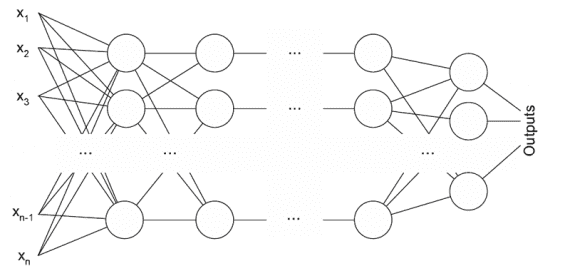
Схема работы многослойного персептрона
Многослойный персептрон состоит из 3 или более слоев. Он использует нелинейную функцию активации, часто тангенциальную или логистическую, которая позволяет классифицировать линейно неразделимые данные. Каждый узел в слое соединен с каждым узлом в последующем слое, что делает сеть полностью связанной. Такая архитектура находит применение в задачах распознавания речи и машинном переводе.
- Сверточная нейронная сеть
Сверточная нейронная сеть (Convolutional neural network, CNN) содержит один или более объединенных или соединенных сверточных слоев. CNN использует вариацию многослойного персептрона. Сверточные слои используют операцию свертки для входных данных и передают результат в следующий слой. Эта операция позволяет сети быть глубже с меньшим количеством параметров.
Сверточные сети показывают выдающиеся результаты в приложениях к картинкам и речи. В статье Convolutional Neural Networks for Sentence Classification автор описывает процесс и результаты задач классификации текста с помощью CNN. В работе представлена модель на основе word2vec, которая проводит эксперименты, тестируется на нескольких бенчмарках и демонстрирует блестящие результаты.
В работе Text Understanding from Scratch авторы показывают, что сверточная сеть достигает выдающихся результатов даже без знания слов, фраз предложений и любых других синтаксических или семантических структур присущих человеческому языку. Семантический разбор, поиск парафраз, распознавание речи — тоже приложения CNN.
- Рекурсивная нейронная сеть
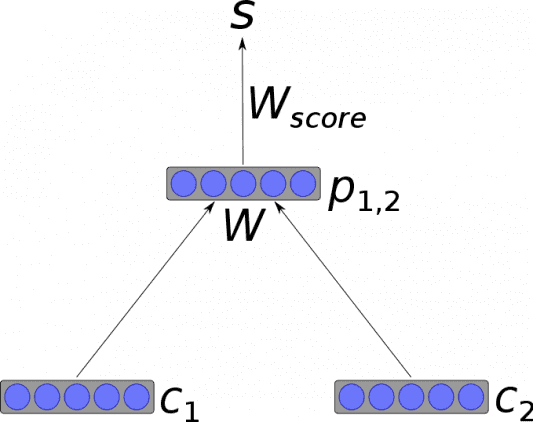
Схема работы рекурсивной нейронной сети
Рекурсивная нейронная сеть — тип глубокой нейронной сети, сформированный при применении одних и тех же наборов весов рекурсивно над структурой, чтобы сделать скалярное или структурированное предсказание над входной структурой переменного размера через активацию структуры в топологическом порядке. В простейшей архитектуре нелинейность, такая как тангенциальная функция активации, и матрица весов, разделяемая всей сетью, используются для объединения узлов в родительские объекты.
- Рекуррентная нейронная сеть
Рекуррентная нейронная сеть, в отличие от прямой нейронной сети, является вариантом рекурсивной искусственной нейронной сети, в которой связи между нейронами — направленные циклы. Последнее означает, что выходная информация зависит не только от текущего входа, но также от состояний нейрона на предыдущем шаге. Такая память позволяет пользователям решать задачи NLP: распознание рукописного текста или речи. В статье Natural Language Generation, Paraphrasing and Summarization of User Reviews with Recurrent Neural Networks авторы показывают модель рекуррентной сети, которая генерирует новые предложения и краткое содержание текстового документа.
В работе Recurrent Convolutional Neural Networks for Text Classification авторы создали рекуррентную сверточную нейросеть для классификации текста без рукотворных признаков. Модель сравнивается с существующими методами классификации текста — Bag of Words, Bigrams + LR, SVM, LDA, Tree Kernels, рекурсивными и сверточными сетями. Описанная модель превосходит по качеству традиционные методы для всех используемых датасетов.
- LSTM
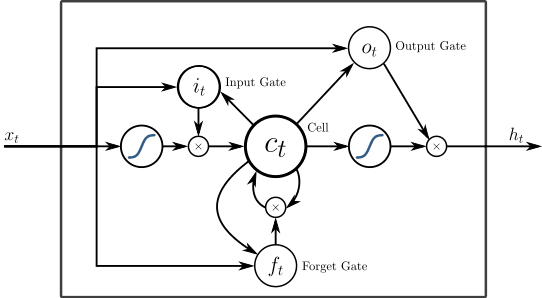
Схема работы LSTM
Сеть долгой краткосрочной памяти (Long Short-Term Memory, LSTM) — разновидность архитектуры рекуррентной нейросети, созданная для более точного моделирования временных последовательностей и их долгосрочных зависимостей, чем традиционная рекуррентная сеть. LSTM-сеть не использует функцию активации в рекуррентных компонентах, сохраненные значения не модифицируются, а градиент не стремится исчезнуть во время тренировки. Часто LSTM применяется в блоках по несколько элементов. Эти блоки состоят из 3 или 4 затворов (например, входного, выходного и гейта забывания), которые контролируют построение информационного потока по логистической функции.
В Long Short-Term Memory Recurrent Neural Network Architectures for Large Scale Acoustic Modeling авторы показывают архитектуру глубокой LSTM рекуррентной сети, которая достигает хороших результатов для крупномасштабного акустического моделирования.
В работе Part-of-Speech Tagging with Bidirectional Long Short-Term Memory Recurrent Neural Network представлена модель для автоматической морфологической разметки. Модель показывает точность 97,4 % в задаче разметки. Apple, Amazon, Google, Microsoft и другие компании внедрили в продукты LSTM-сети как фундаментальный элемент.
- Sequence-to-sequence модель
Часто Sequence-to-sequence модели состоят из двух рекуррентных сетей: кодировщика, который обрабатывает входные данные, и декодера, который осуществляет вывод.
Sequence-to-Sequence модели часто используются в вопросно-ответных системах, чат-ботах и машинном переводе. Такие многослойные ячейки успешно использовались в sequence-to-sequence моделях для перевода в статье Sequence to Sequence Learning with Neural Networks study.
В Paraphrase Detection Using Recursive Autoencoder представлена новая рекурсивная архитектура автокодировщика, в которой представления — вектора в n-мерном семантическом пространстве, где фразы с похожими значением близки друг к другу.
- Неглубокие (shallow) нейронные сети
Неглубокие модели, как и глубокие нейронные сети, тоже популярные и полезные инструменты. Например, word2vec — группа неглубоких двухслойных моделей, которая используется для создания векторных представлений слов (word embeddings). Представленная в Efficient Estimation of Word Representations in Vector Space, word2vec принимает на входе большой корпус текста и создает векторное пространство. Каждому слову в этом корпусе приписывается соответствующий вектор в этом пространстве. Отличительное свойство — слова из общих текстов в корпусе расположены близко друг к другу в векторном пространстве.
Приложения и модели для обработки текста
IBM Watson Natural Language Understanding
IBM Watson Natural Language Understanding предоставляет полный комплект функций расширенного анализа текста для извлечения сущностей, взаимосвязей, ключевых слов, семантических ролей и т. д.
Настройка предметной области: применение к данным знаний об уникальных сущностях и отношениях в отдельно взятой отрасли или организации.
Функции:
- Распределение материалов по категориям с помощью пятиуровневой иерархии классификации.
- Выявление общих концепций, которые не затрагиваются в тексте напрямую.
- Анализ эмоциональной окраски конкретных целевых фраз или всего документа.
- Определение людей, мест, событий и других типов сущностей, упоминаемых в материалах.
- Поиск ключевых слов в материалах.
- Анализ тональности, в частности, отношения к конкретным целевым фразам и к документу в целом.
- Определение пользовательских сущностей и взаимосвязей, относящихся только к конкретной предметной области, с помощью Watson Knowledge Studio.
Примеры использования:
- При помощи Node.js и Watson возможно создание когнитивного банковского чатбота для определения эмоциональной окраски, выявления сущностей и поиска ответов.
- Анализ идентификаторов и хештегов Twitter для оценки настроения и содержимого. Создание диаграмм и графиков, отражающих настроение, эмоциональный тон и ключевые слова идентификаторов и хештегов Twitter.
Серверное приложение подписывается на канал Twitter, настроенный пользователем. Каждый полученный твит анализируется на предмет эмоциональной окраски и тональности (Watson Tone Analyzer Service). Watson Natural Language Understanding Service извлекает ключевые слова и единицы. Цель твита определяется службой Watson Assistant. Все данные хранятся в базе данных Cloudant, с возможностью также хранить исторические данные. Информация представлена в веб-интерфейсе в виде серии графиков и диаграмм.
Для анализа тональности используется метод опорных векторов (SVM, support vector machine) — набор алгоритмов обучения с учителем, использующихся для задач классификации и регрессионного анализа. Принадлежит семейству линейных классификаторов. Особым свойством метода опорных векторов является непрерывное уменьшение эмпирической ошибки классификации и увеличение зазора, поэтому метод также известен как метод классификатора с максимальным зазором.
Основная идея метода — перевод исходных векторов в пространство более высокой размерности и поиск разделяющей гиперплоскости с максимальным зазором в этом пространстве. Две параллельных гиперплоскости строятся по обеим сторонам гиперплоскости, разделяющей классы. Разделяющей гиперплоскостью будет гиперплоскость, максимизирующая расстояние до двух параллельных гиперплоскостей. Алгоритм работает в предположении, что чем больше разница или расстояние между этими параллельными гиперплоскостями, тем меньше будет средняя ошибка классификатора.
Для каждого из тонов модель обучается независимо с использованием парадигмы One-Vs-Rest. Во время прогнозирования определяются тона, которые были предсказаны с вероятностью не менее 0,5 в качестве итоговых. Для решения проблемы несбалансированности тонов вычисляется оптимальное значение веса функции стоимости для каждого из этих тонов во время обучения.
- Анализ SMS с помощью Watson Knowledge Studio. Создание пользовательской модели, помогающей оптимизировать распределение по категориям содержимого сообщений SMS с помощью Watson Knowledge Studio и Watson Natural Language Understanding.
- Когнитивный анализ данных с помощью Jupyter Notebook и PixieDust для обнаружения скрытой ценной информации об использовании Facebook. Источник данных — Facebook Analytics. Затем происходит извлечение ключевых слов, именованных сущностей, выявление тональности.
- Используя Watson Natural Language Understanding и Watson Knowledge Studio, можно создать модель извлечения персональных данных из неструктурированного текста.
- Быстрое определение актуальных тенденций в сфере технологий на основе материалов сайта Hacker News с помощью когнитивных API. Предоставляет информацию о концепциях, сущностях, категориях, ключевых словах, настроениях, эмоциях и т. д., упоминаемых в новостной статье на сайте.
Amazon Comprehend
Amazon Comprehend — сервис обработки естественного языка, в котором для поиска закономерностей и взаимосвязей в тексте применяются технологии машинного обучения. Для использования не требуется опыт в сфере машинного обучения.
Сервис определяет язык текста, извлекает ключевые фразы, распознает людей, места, бренды или события, определяет тональность текста (положительная, отрицательная, нейтральная или смешанная), анализирует текст с помощью токенизации и определения частей речи и в результате автоматически группирует набор текстовых файлов по темам. Можно использовать возможности AutoML в Amazon Comprehend для создания пользовательского набора сущностей или моделей классификации текста, адаптированных к уникальным потребностям конкретной организации.
Для извлечения сложных медицинских данных из неструктурированного текста можно использовать Amazon Comprehend Medical. Сервис может идентифицировать такие медицинские данные, как диагнозы, названия препаратов, дозировки, эффективность воздействия и частоту приема, используя различные источники, например, заметки врача, отчеты о клинических испытаниях и истории болезни пациентов. Amazon Comprehend Medical также идентифицирует взаимосвязь между извлеченными препаратами и данными обследований, терапии и процедур для облегчения процесса анализа. Например, сервис использует неструктурированные клинические заметки для идентификации конкретной дозировки, эффективности воздействия и частоты приема, связанных с конкретным препаратом.
Пользовательские сущности позволяют настроить Amazon Comprehend для выявления терминов, относящихся к домену клиента. Используя AutoML, сервис Comprehend пройдет «обучение» на основе небольшого закрытого набора примеров, а затем «научит» закрытую пользовательскую модель распознавать эти термины в любом другом текстовом блоке. Для этого не нужно управлять никакими серверами и осваивать никакие алгоритмы.
Microsoft Azure Text Analytics
Microsoft Azure Text Analytics – служба ИИ, которая извлекает аналитические данные, такие как тональность, сущности, отношения и ключевые фразы, в неструктурированном тексте.
Сервис «Анализ текста» может быть запущен в облаке, локально или в контейнерах на периферии.
Для анализа тональности возможно два варианта использования сервиса: запрос на определение тональности с возвратом оценки (негативная, нейтральная, позитивная) и указанием коэффициента уверенности в поставленной оценке; или «запрос мнений», в результате которого клиент получает детальную информацию о мнениях, связанных со словами (такими как атрибуты продуктов или услуг) в тексте.
Анализ тональности в последней версии применяет к тексту метки тональности, которые возвращаются на уровне предложения и документа с оценкой достоверности для каждого.
Оценки бывают положительными, отрицательными и нейтральными. На уровне документа также может быть возвращена метка смешанного тона. Тональность документа определяется следующим образом:
| Тональность предложения | Оценка документа |
| Минимум одно предложение в документе несет позитивную окраску, остальные предложения нейтральны. | Позитивная |
| Минимум одно предложение в документе несет негативную окраску, остальные предложения нейтральны. | Негативная |
| Минимум одно предложение несет негативную окраску, минимум одно – позитивную. | Смешанная |
| Все предложения в документе нейтральны | Нейтральная |
Оценки достоверности варьируются от 1 до 0. Баллы, близкие к 1, указывают на более высокую уверенность в классификации лейбла, в то время как более низкие оценки указывают на меньшую уверенность. Для каждого документа или каждого предложения прогнозируемые оценки, связанные с ярлыками (положительный, отрицательный и нейтральный), составляют в
сумме 1.
В отличие от оценки тональности, запрос мнений позволяет вычленить из текста отдельные аспекты и сущности с присвоенными им атрибутами, оценками и тональностью.
Для более точных результатов рекомендуется использовать небольшие объемы текста (менее 5120 символов).
Google Cloud Natural Language
Natural Language API поддерживает три основных вида анализа:
Анализ тональности позволяет оценить, насколько текст положительный, нейтральный или отрицательный. AnalyzeSentiment Choreo возвращает оценку тональности входящего текста по шкале от -1,0 до 1,0, где оценка -1,0 — очень отрицательная, 0,0 — нейтральная, а 1,0 — очень положительная. Также по шкале от 0 до бесконечности оценивается интенсивность выраженной эмоции. Оценки тональности возвращаются для отдельных предложений в тексте, а также для документа в целом.
Анализ сущностей: AnalyzeEntities Choreo идентифицирует существительные в тексте. Каждой сущности присваивается оценка значимости по шкале от 0,0 до 1,0, которая указывает значимость этой сущности для текста и помогает определить тематику текста.
Сущность может быть отдельно определена как имя собственное, далее все сущности классифицируются по типу: человек, произведение искусства, место и организация. Полный список типов сущностей, определенных Google, можно найти в документации Natural Language API.
Дополнительные метаданные, представленные в ответе API, включают ссылку на статью в Википедии и машинно-сгенерированный идентификатор Google Knowledge Graph, если таковой существует.
Синтаксический анализ: AnalyzeSyntax Choreo анализирует предложения в тексте. Он возвращает каждое отдельное предложение, найденное в тексте, описание морфологических свойств каждого слова в каждом предложении и дерево зависимостей для каждого предложения, описывающее грамматические отношения между словами в нем.
Этот API предназначен для возврата грамматических данных для нескольких языков, поэтому некоторые из потенциальных морфологических свойств, которые учитывает API, могут не иметь отношения к языку, который анализирует конкретное приложение.
Для проведения на одном тексте одновременно всех трех видов анализа следует воспользоваться AnnotateText Choreo.
Lexalytics
Для анализа текстов в Lexalytics используют гибридный подход: обучение по правилам и машинное обучение.
Написание кода начинается с паттернов и правил языка. После этого на основании моделей машинного обучения (Machine learning, ML) с подкреплением и без него, выучивших данные правила, формируются классификаторы. Условно функции разделяются на низший, средний и высокий уровень.
Низшему уровню функций соответствует первичное структурирование текста для преобразования его в структурированные данные для последующей обработки на среднем уровне, на котором происходит извлечение содержимого документа или текста (определение автора, содержания и тематики текста). Последней ступенью анализа текста является анализ настроений, определяющий более тонкое определение настроения автора, тематики и уровня документа.
|
Уровень |
Действие |
Инструмент |
|
Низший |
Токенизация: разбивка текста на машинопонятные единицы, например, слова |
ML+Rules |
|
Определение части речи каждого токена и соответствующее тегирование |
ML |
|
|
Разбивка предложения на составляющие его фразы (словосочетания с существительными, словосочетания с глаголами и т. д.). |
Rules |
|
|
Границы предложения, связь между предложениями |
ML+Rules |
|
|
Синтаксический анализ (особенно важен для анализа настроений) |
ML+Rules |
|
|
Средний |
Определение именованных сущностей |
ML+Rules для ответа на вопросы «Кто? Что? Где?» |
|
Тема |
Rules «Что происходит?» |
|
|
Тематический раздел |
ML+Rules «О чем?» |
|
|
Саммари |
Rules «Сократить» |
|
|
Определение намерений: кто совершает действие, объект действия и намерение |
ML (определение типа намерения)+Rules («черные» и «белые» списки слов) |
|
|
Высокий |
Анализ настроений, определение эмоций |
ML+Rules |
TexSmart
TexSmart — это система распознавания текста, созданная командой NLP в Tencent AI Lab, которая используется для анализа морфологии, синтаксиса и семантики текста на китайском и английском языках.
Помимо поддержки общих функций, таких как сегментация слов, теги частей речи, распознавание именованных сущностей, синтаксический анализ, маркировка семантических ролей, классификация текста, сопоставление текста, нормализация текста (восстановление регистра для английского языка), TexSmart также предоставляет специальные функции, такие как детализированное распознавание именованных сущностей (1000 типов сущностей), семантическое расширение, глубокий семантический анализ и так далее. Технологии понимания текста, которые используются для структурного анализа и обработки естественного языка, широко применяются в поисковых системах, системах персонализированных рекомендаций, подбора рекламы, интеллектуальных диалоговых системах и не только.
Семантическое расширение предлагает функцию, в результате которой на выходе пользователь получает список сущностей, которые могут быть связаны с изначальной сущностью в тексте.
Для особых типов сущностей, таких как время и количество, может применяться глубокий семантический анализ для вывода конкретных семантических значений. Например, перевод абстрактной фразы «14 месяцев назад» в конкретную дату.
MeaningCloud Sentiment Analysis API
MeaningCloud Sentiment Analysis API работает с неструктурированными текстами для определения тональности. API идентифицирует тональность локально для отдельных фраз, устанавливает между ними связь для определения общей тональности текста.
Решает такие задачи, как определение иронии в предложении, определяет, является ли предложение субъективным мнением или объективным фактом, различает противоположные или неоднозначные точки зрения. Анализ тональности может происходить как на уровне целого документа, так и на отдельных его аспектах на любом из десяти поддерживаемых языков.
Twinword Sentiment Analysis API
Twinword Sentiment Analysis API для каждого анализируемого текста возвращает значение, которое определяет тональность предложения или параграфа текста как положительную (значения выше 0,05), негативную (значения ниже -0,05) или нейтральную (любые значения между указанными ранее). Возможна настройка алгоритма на собственные значения тональности, например, -0,75 в качестве негативной оценки и выше 0,95 как позитивной.
Компания также предлагает инструменты для анализа эмоций, классификации текстов, определения схожести текстов.
Приложение легко настраивается для решения конкретных задач заказчика.
Intellexer Sentiment Analyzer
Intellexer Sentiment Analyzer – набор инструментов для разработчиков для интеграции возможностей анализа текстов в другие приложения.
Intellexer Sentiment Analyzer использует технологию, объединяющую лингвистический и статистический анализ в сочетании с набором сложных семантических правил. API может эффективно анализировать различные типы выражений, например, зависящие от контекста мнения, зависящие от предметной области мнения и фразы, не связанные с мнением. Другие задачи, решаемые API: сравнение документов, выделение сущностей, создание краткого содержания текста, проверка правописания и лингвистическая обработка документа.
AYLIEN Text Analysis API
AYLIEN Text Analysis API выполняет анализ тональности на уровне документа, на основе аспектов и на уровне сущности для понимания текстового контента, созданного человеком. API обладает обширными функциями, помогающими разработчикам извлекать полезную ценность из текстовых данных, включая тональность, субъективность оценки, саммари и извлечение сущностей. AYLIEN также имеет News API для анализа тысяч потоков новостного контента. Возможно быстрое создание настраиваемых моделей обработки естественного языка. Поддерживает семь разных языков.
ERNIE 2.0
ERNIE 2.0 — фреймворк от Baidu для понимания естественного языка, работает на английском и китайском языках, поддерживает логический вывод, определение семантического сходства, распознавание именованных сущностей, анализ тональности и сопоставление вопросов и ответов.
То, что его отличает от других моделей — это концепции многозадачного обучения (Multi-task learning) и непрерывного обучения (Continual learning).
Архитектура непрерывного предварительного обучения содержит ряд общих слоев кодирования текста для кодирования контекстной информации, которые могут быть настроены с помощью периодических нейронных сетей или глубокого трансформатора, состоящего из сложенных слоев самоконтроля. Параметры энкодера могут быть обновлены во всех заданиях перед тренировкой.
Эти задачи имеют, как и у других моделей, самообучаемые цели. Примеры таких задач:
- Восстановление правильного порядка слов в предложении.
- Определение слов, начинающихся с заглавной буквы.
- Определение маскированных слов.
На этих задачах модель обучается последовательно, возвращаясь и к задачам, на которых обучалась ранее.
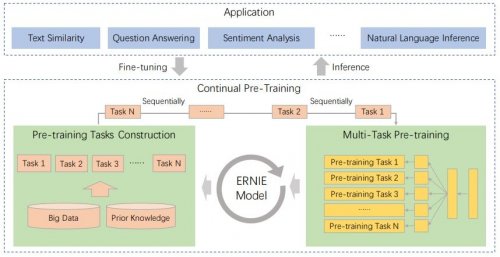
Команда Baidu сравнила производительность ERNIE 2.0 с другими NLP-моделями для английского языка на наборе данных GLUE и отдельно на 9 популярных наборах для китайского языка. Результаты показывают, что
ERNIE 2.0 превосходит BERT и XLNet в 7 задачах на понимание английского языка и превосходит BERT по всем 9 задачам, когда дело касается китайского, таких как машинное чтение с использованием набора данных DuReader, семантический анализ и ответы на вопросы.
XLNET
XLNet — это обобщенный авторегрессивный метод, который интегрирует в себе частично свойства авторегрессивных языковых моделей и автокодировщиков. На выходе выдает вероятность совместной встречаемости последовательности токенов на основе архитектуры рекуррентного Трансформера, который позволяет текущей последовательности видеть информацию из предыдущих последовательностей. Задачей обучения модели является подсчет вероятности для заданного слова (токена), при условии наличия всех других слов в предложении (а не только слов слева или справа от заданного).
Во-первых, нейросеть не использует фиксированные прямо направленный и обратно направленный порядки факторизации, как в стандартных авторегрессивных моделях. Вместо этого, XLNet максимизирует ожидаемый логарифм вероятности последовательности слов с учетом всех перестановок порядков слов. Благодаря шагу с перестановками, контекст для каждой позиции в последовательности может состоять из слов с правой и левой сторон. Получается, что слово на каждой позиции в последовательности учится использовать контекстную информацию со всех остальных позиций (bidirectional context).
Во-вторых, как и в авторегрессивной модели, XLNet не маскирует слова в последовательности. Из-за этого модель не страдает от проблемы несоответствия модели на предобучении и на тюнинге для отдельной задачи. Эта проблема свойственна BERT.
В-третьих, в XLNet используется новая целевая функция, дающая категориальное распределение вероятностей для следующего токена.
BERT
BERT – это модель, побившая несколько рекордов по успешности решения ряда NLP-задач. Вскоре после выхода статьи, описывающей модель, команда разработчиков выложила в открытый доступ код модели и сделала возможным скачивание различных версий BERT, которые уже были предобучены на больших наборах данных для использования сообществом в своих разработках.
BERT построен на целом ряде недавних разработок, предложенных NLP-сообществом, включая, но не ограничиваясь: Semi-supervised Sequence learning, ELMo, ULMFiT, OpenAI Transformer.
Примеры использования BERT:
- Классификация текста
- Анализ тональности
- Проверка фактов:
- Вход: предложение. Выход: «утверждение» (Claim) или «не утверждение» (Not Claim).
- Вход: предложение с утверждением (Claim sentence). Выход: «Правда» или «Ложь». Такой разработкой занимается организация Full Fact. В частности, создан классификатор, который читает новостные статьи и распознает сомнительные факты, которые затем могут быть проверены (пока человеком, позже, возможно, с помощью машинного обучения).
Модель имеет российскую языковую модель – RuBERT, созданную проектом DeepPavlov.
Проект DeepPavlov
Изначально DeepPavlov– открытая программная библиотека разговорного AI для создания виртуальных диалоговых ассистентов и анализа текста. На данный момент создатели позиционируют DeepPavlov как экосистему продуктов и проектов.
DeepPavlov Library поставляется с несколькими предобученными компонентами для решения проблем, связанных с обработкой естественного языка (NLP). DeepPavlov решает проблемы такие как: классификация текста, исправление опечаток, распознавание именованных сущностей, ответы на вопросы по базе знаний и многие другие.
Команда DeepPavlov интегрировала BERT в три последующие задачи: классификация текста, распознавание именованных сущностей и ответы на вопросы.
Модель классификации текста на основе BERT DeepPavlov служит, например, для решения проблемы обнаружения оскорблений. Модель включает в себя прогнозирование того, считается ли комментарий, опубликованный в ходе публичного обсуждения, оскорбительным для одного из участников. Для этого случая классификация осуществляется только по двум классам: оскорбление и не оскорбление.
Любая предварительно обученная модель может быть использована для вывода как через интерфейс командной строки (CLI), так и через Python.
DeepPavlov содержит модель на основе BERT для распознавания именованных сущностей (NER). NER может использоваться для идентификации соответствующих объектов в запросах клиентов, таких как спецификации продуктов, названия компаний или данные о филиалах компании.
Команда DeepPavlov обучила модель NER на англоязычном корпусе OntoNotes, который имеет 19 типов разметки, включая PER (человек), LOC (местоположение), ORG (организация) и многие другие.
Одним из основных переломных моментов в области ответов на вопрсоы из контекста стал выпуск Стэнфордского набора данных для ответов на вопросы (SQuAD). Набор данных SQuAD привел к появлению бесчисленных подходов к решению задачи вопросно-ответных систем. Одной из наиболее успешных является модель DeepPavlov BERT. Она превосходит все остальные и в настоящее время дает результаты, граничащие с человеческими характеристиками.
В 2020 году в DeepPavlov Library также появились следующие модели: Speech recognition and synthesis (распознавание речи и генерация текста); Knowledge Base Question Answering model for WikiData (основанная на знаниях вопросно-ответная система для WikiData); Entity Linking (установление связей между сущностями); Intent Catcher (анализ намерений).
DeepPavlov Agent — платформа для создания многозадачных чат-ботов. DeepPavlov Agent представляет собой многофункциональный оркестратор, использующий декларативный подход для формирования конвейеров и построения диалогового ИИ в виде модульной системы.
DeepPavlov Cloud позволяет анализировать текст, а также хранить документы в облачном хранилище. Для использования моделей необходимо зарегистрироваться в сервисе и получить токен в разделе Tokens личного кабинета. На данный момент сервис поддерживает несколько предобученных NLP моделей на русском языке и находится в стадии тестирования системы.
Открытая платформа DeepPavlov Dream может быть использована для разработки масштабируемых и многофункциональных виртуальных помощников, и опирающейся на технологии DP Library и Agent.
В 2020 DeepPavlov стал партнёром программы NVIDIA GPU Cloud (NGC) – контейнерного реестра для работы с искусственным интеллектом, машинным обучением, нейронными сетями и высокопроизводительными вычислениями. Теперь контейнеры библиотеки DeepPavlov доступны в облаке NGC.
Контейнеры DeepPavlov состоят из предварительно обученных моделей, которые используют современные модели глубокого обучения типа BERT для задач классификации, распознавания именованных сущностей, вопросов-ответов и других задач области NLP. Использование GPU позволяет ускорить работу библиотеки DeepPavlov до 20 раз (для примера был взят запуск конвейеров модуля ASR/TTS на V100 GPU в сравнении с CPU).
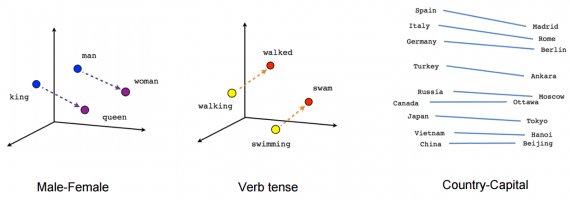
Word2Vec
Word2vec принимает большой корпус текста, в котором каждое слово в фиксированном словаре представлено в виде вектора. Далее алгоритм пробегает по каждой позиции t в тексте, которая представляет собой центральное слово c и контекстное слово o. Далее используется схожесть векторов слов для c и o, чтобы рассчитать вероятность o при заданном с (или наоборот), и продолжается регулировка векторов слов для максимизации этой вероятности.
Для достижения лучшего результата Word2vec из датасета удаляются бесполезные слова (или слова с большой частотой появления, в английском языке — a, the, of, then). Это поможет улучшить точность модели и сократить время на тренировку. Кроме того, используется отрицательная выборка (negative sampling) для каждого входа, обновляя веса для всех правильных меток, но только на небольшом числе некорректных меток.
Word2vec представлен в 2 вариациях моделей:

Skip-Gram: рассматривается контекстное окно, содержащее k последовательных слов. Далее пропускается одно слово и обучается нейронная сеть, содержащая все слова, кроме пропущенного, которое алгоритм пытается предсказать. Следовательно, если 2 слова периодически делят cхожий контекст в корпусе, эти слова будут иметь близкие векторы.
Continuous Bag of Words: берется много предложений в корпусе. Каждый раз, когда алгоритм видим слово, берется соседнее слово. Далее на вход нейросети подается контекстные слова и предсказываем слово в центре этого контекста. В случае тысяч таких контекстных слов и центрального слова, получаем один экземпляр датасета для нашей нейросети. Нейросеть тренируется и, наконец, выход закодированного скрытого слоя представляет вложение (embedding) для определенного слова. То же происходит, если нейросеть тренируется на большом числе предложений и словам в схожем контексте приписываются схожие вектора.
Единственная жалоба на Skip-Gram и CBOW — принадлежность к классу window-based моделей, для которых характерна низкая эффективность использования статистики совпадений в корпусе, что приводит к неоптимальным результатам.
Проект Russian SuperGlue
Проект Russian SuperGLUE — рейтинг русскоязычных NLP-моделей.
Russian SuperGLUE, который создали специалисты Сбера, лаборатория Noah’s Ark Huawei и факультет компьютерных наук ВШЭ, помогает оценивать русскоязычные модели по объективным метрикам (лидерборд с результатами оценки), выбирать оптимальную для решения конкретной задачи и использовать ее.
Большая часть NLP-моделей не подходит для работы с текстами на русском языке — даже мультиязычные модели дают не лучшие результаты. Например, почти сразу после появления BERT вышла его мультиязычная версия, обученная на 104 языках (в том числе на русском), которая тем не менее плохо справлялась с текстами на русском языке.
SuperGLUE, разработанный DeepMind, подходит для ранжирования англоязычных моделей, но оценить качество русскоязычной или мультиязычной модели с его помощью нельзя.
Проект Russian SuperGLUE состоит из четырех компонентов: тестирование навыков моделей (здравый смысл, целеполагание, логика), тестирование уровня человека для сравнения, оценка существующих моделей и помощь в оценке собственной модели для дата-сайентистов.
Для каждой модели доступна общая оценка и балл за каждый из девяти наборов заданий:
- LiDiRus (Linguistic Diagnostic for Russian) или просто общая диагностика — адаптирована с английского варианта.
- DaNetQA — набор вопросов на здравый смысл и знание, с ответом да или нет (собрана с нуля).
- RCB (Russian Commitment Bank) — классификация наличия причинно-следственных связей между текстом и гипотезой из него (собрана с нуля по новостям и художественной литературе).
- PARus (Plausible Alternatives for Russian) — целеполагание, выбор из альтернативных вариантов на основе здравого смысла (собрали с нуля по новостям и художественной литературе из корпуса Тайга).
- MuSeRC (Multi-Sentence Reading Comprehension) — машинное чтение. Задания содержат текст и вопрос к нему, но такой, на который можно ответить, сделав вывод из текста (найти ответ поиском нельзя).
- RuCoS (Russian reading comprehension with Commonsense) — машинное чтение. Модели даётся новостной текст, а также его краткое содержание, в котором стоит пропуск — пропуск нужно восстановить, выбрав из вариантов. (новостные сайты)
- TERRa (Textual Entailment Recognition for Russian) — классификация наличия причинно-следственных связей между предложениями (собрана с нуля по новостям и художественной литературе).
- RUSSE (Russian Semantic Evaluation) — задача распознавания смысла слова в контексте (готовый датасет).
- RWSD (Russian Winograd Schema Dataset) — задания на логику, с добавленными неоднозначностями («Если бы у Ивана был осёл, он бы его бил»). Создан по аналогии с классической Winograd Schema (адаптирована с английского варианта).
Чтобы получить возможность сравнивать результаты моделей с результатами человека, были подготовлены инструкции и отправлены задания на «Яндекс.Толоку», где их решали люди. Все датасеты взвешены, случайное угадывание даёт результат около 50 %.
По метрике общей оценки, модели пока отстают от человека: люди справляются с заданиями на 80,2%, а лучшая нейросеть — на 67,9%. С некоторыми заданиями (например, RUSSE — смысл слова в контексте) машина справляется на 10-15% лучше человека.
Проблемы обработки естественного языка
Доступ к данным
Исторические данные — например, публикации и обзоры, — собранные с помощью API источников или агрегирующих платформ, часто используются и анализируются в исследованиях тональности. Иногда разработчики API предоставляют только частичный доступ к опубликованным данным. Агрегирующие платформы заявляют, что у них есть полный доступ к данным конкретного источника, но проверить это невозможно. Есть два способа убедиться в репрезентативности данных для исследования:
- Тщательно изучить описание API и выбрать опции, дающие полный доступ к историческим данным. В случае с агрегирующими платформами нужно убедиться, что они используют опции API для полного доступа к историческим данным.
- Запросить прямой доступ к историческим данным выбранного источника. Например, через OK Data Science Lab можно запросить доступ к историческим данным Одноклассников.
Открытость данных исследований
Кроме исторических данных, в русскоязычных источниках не хватает также наборов обучающих и тестовых выборок, особенно в сфере анализа тональности.
Мировые компании лидеры в области ИИ активно публикуются. Исследователи, аффилированные с ними, публикуют свои результаты, обмениваются результатами на конференциях.
Это создает активный обмен информацией и способствует росту каждого исследователя. Как результат – и сами компании активно развиваются и укрепляют свои лидерские позиции.
Несмотря на значительное количество исследований, российские авторы очень редко выкладывают свои наборы данных в открытый доступ. Поэтому исследователям зачастую приходится размечать данные для исследований самостоятельно. Российские компании лидеры в области ИИ практически не публикуются. Исследователи, аффилированные с ними, не публикуют результаты своих работ и практически не выступают с ними на конференциях.
Это ведет к ухудшению обмена информацией, ведущие российские специалисты не участвуют в мировой исследовательской повестке, что неизбежно ведет к отставанию.
Определение тональности, иронии и сарказма
Большое влияние на особенности анализа тональности текстов оказывает также длина анализируемого текста. Короткие тексты, например, сообщения Твиттера, краткие комментарии, требуют очень точного анализа.
В текстах большей длины высказываемое мнение может быть повторено несколько раз в разных вариантах, что облегчает анализ. Однако в длинных текстах нарастает разнообразие объектов, которые подвергаются оценке. Длинные тексты могут включать мнения других людей. Если задача состоит в том, чтобы найти оценку по отношению к упоминаемым сущностям, то возникает проблема определения сферы действия оценок.
Например, часто оценку связывают с сущностью, упоминаемой в том же предложении. Но автор может сослаться на объект с помощью средств референции, например, местоимений. Кроме того, если весь текст посвящен обсуждению одной сущности, то она может быть явным образом упомянута достаточно далеко от места расположения оценки.
Анализ оценочных суждений может быть осложнен многозначностью слов, а именно: конкретное слово может менять свою полярность или терять полярность в зависимости от предметной области или текущего контекста. В одном значении слова могут быть нейтральными, а в других значениях негативными или позитивными.
Появление оценочных слов в тексте может сопровождаться словами модификаторами, которые усиливают, снижают или преобразуют в обратную исходную тональность, которая ассоциируется с данным словом. Таким образом, при анализе тональности нужно учитывать такие модификаторы и иметь некоторую численную модель, которая модифицирует исходные полярности слова. Одна из распространенных моделей трактовки модификаторов тональности приписывает им некоторые коэффициенты, которые рассматриваются как множители относительно априорной полярности слов, к которым относятся эти модификаторы.
Другой важной проблемой является определение сферы действия модификатора полярности в конкретном предложении, например, отрицания.
Сравнения усложняют процесс определения тональности, поскольку вводят в текст некоторые дополнительные сущности, и часть упоминаемых оценок относится именно к ним. Такие дополнительные сущности иногда очень трудно выделить самих по себе, а также отделить относящиеся к ним оценки.
Обработка иронии и сарказма являются серьёзными проблемами в работе автоматических систем анализа тональности, поскольку тональность ироничного (саркастичного) высказывания отличается от его буквальной тональности.
Разметка текстовых данных для изучения иронии и сарказма представляет собой сложную задачу. Интересным ресурсом для анализа этих явлений являются сообщения Твиттера, которые пользователь может разметить специализированными хештегами: #ирония, #сарказм и некоторыми другими. Однако последние исследования иронии в Твиттере показывают, что ироничные твиты, отмеченные хэштегами и не отмеченные, имеют разные характеристики.
Тренды 2021
На горизонте 5-10 лет, благодаря получающим все большую популярность методам машинного обучения, исследователи ожидают прорыв в технологиях понимания смысла текста с учетом контекста. Будут улучшены диалоговые и справочные сервисы, на новый уровень выйдет текстовая обработка потоков в СМИ и соцсетях, в автоматический режим будет переведена проверка фактов на достоверность, оценка субъективности сообщений.
Будет расти значение методов машинного обучения, которые эффективно работают в условиях малого количества сырых данных. Для достижения данных целей ожидается более широкое использование генеративно-состязательных сетей для генерации данных с целью обучения моделей.
Кросс-языковой способ обработки и трансферное обучение стали одними из краеугольных камней обработки естественного языка. Центральная идея заключается в том, что между языками есть общие черты, которые можно использовать для построения универсального корпуса. Процесс межъязыкового трансферного обучения относится к переносу ресурсов и моделей из богатого ресурсами источника на малоресурсные языки.
Трансфер модели позволяет перенести модели, обученные на языках с высоким объемом ресурсов, на малоресурсные языки в режиме однократного обучения. Этот подход популярен при машинном переводе.
«Родительская» модель обучается в языковой паре с высокими ресурсами (французский/английский). Затем эта модель повторно используется на «дочерней» модели, которая обучается на языковой паре с низким уровнем ресурсов (турецкий/узбекский).
По мере перехода нейросетевых моделей из лабораторий в коммерческие дата-центры повысятся требования к их энергоэффективности. Ожидается появление новых, более эффективных вычислительных архитектур. Например, разреженные сети, сочетающие лучшие качества распределенных и символьных вычислений, модели, сложность которых адаптируется к количеству обучающих данных.
В крупных компаниях развивается тренд на создание собственных команд исследователей обработки естественного языка, лингвистов и специалистов по большим данным. Количество задач, уходящих на аутсорсинг, будет оставаться крайне низким.
- 1SemEval — один из самых авторитетных семинаров в области языкового анализа. Мероприятие спонсируется группой лексических исследований SIGLEX в рамках Ассоциации компьютерной лингвистики, одной из самых влиятельных и динамичных международных организаций в этой сфере
- 2Перенос обучения (трансферное обучение) предполагает использование знаний определенной обученной модели для решения схожих задач для другой модели
Похожие записи:
 Объяснимый искусственный интеллект
Объяснимый искусственный интеллект
 Искусственный интеллект: технологии и применение
Искусственный интеллект: технологии и применение
 Государственные программы США анализа медиаматериалов Агентства передовых исследований в сфере разведки (IARPA)
Государственные программы США анализа медиаматериалов Агентства передовых исследований в сфере разведки (IARPA)
 Компьютерное зрение: технологии, компании, тренды
Компьютерное зрение: технологии, компании, тренды
 WhatsApp внес изменения в свои Условия использования и Политику приватности
WhatsApp внес изменения в свои Условия использования и Политику приватности