Компьютерное зрение: технологии, компании, тренды

Компьютерное зрение (Computer Vision, CV), в том числе машинное зрение (Machine Vision, MV) – это автоматическая фиксация и обработка изображений неподвижных и движущихся объектов при помощи компьютерных средств.
С развитием облачных технологий, виртуализации вычислений и прикладных областей развитие компьютерного зрения получило новый импульс.
По данным маркетингового отчета американской исследовательской и консалтинговой компании Grand View Research1Computer Vision Market Size, Share & Trends Analysis Report By Component (Hardware, Software), By Product Type (Smart Camera-based, PC-based), By Application, By Vertical, By Region, And Segment Forecasts, 2020 – 2027. Опубликовано: сентябрь 2020 г. grandviewresearch.com/industry-analysis/computer-vision-market, в 2019 году размер мирового рынка компьютерного зрения оценивался в 10,6 млрд долларов США и будет расти со среднегодовым темпом роста в 7,6% с 2020 по 2027 год.
Наиболее часто используемой моделью глубокого обучения является модель искусственной нейронной сети, называемая сверточной нейронной сетью. Наиболее успешными моделями, используемыми для обнаружения, классификации и анализа изображений, являются AlexNet, ResNets, EfficientNets, YOLO, R-CNN, LambdaNetworks, VGG (описания приведены в Приложении 1).
Лидерами по развитию и использованию компьютерного зрения на международном уровне являются Google, Facebook, Microsoft, Amazon, NVIDIA и др. В России ключевые позиции на рынке занимают Яндекс, VisionLabs, Mail.ru Group, NtechLab, ABBYYи др. Информация о проектах в сфере компьютерного зрения указанных и ряда других компаний приведена в Приложении 1.
Одним из растущих трендов развития технологий компьютерного зрения является переход к периферийным вычислениям, которые выигрывают у облачных сервисов в скорости и безопасности. Все больше и больше компаний используют периферийные вычисления в сочетании с облачными сервисами для своих данных из-за их оптимизированного подхода.
Много усилий прикладывается со стороны научного сообщества для развития объяснимости решений ИИ, поскольку, несмотря на достаточно высокую точность детектирования и классификации в задачах компьютерного зрения, в ходе исследований было доказано, что верные решения системой могут быть приняты в ходе неверного распределения весов. Одним из известнейших случаев является задача определения «хаски-волк»2https://arxiv.org/pdf/1602.04938v1.pdf, в которой модель достигла высокой точности, однако, как оказалось при разборе, наибольший вес в расчетах отдавался такому признаку как наличие снега на фоне.
Исследователи возлагают большие надежды на автоматическую разметку данных для обучения нейросетей. Поскольку большой объем хорошо размеченных данных является фундаментом надежной модели, автоматическая разметка заметно сократила бы сроки обучения и ускорила создание конечного приложения компьютерного зрения. Ручная разметка одного изображения (например, из датасета COCO) может занять от 2 до 19 минут, время для разметки всего датасета может достигнуть 53 000 часов. В случае использования автоматической разметки специалисту зачастую необходимо только проверить точность контуров и внести необходимые изменения, что значительно сократит время подготовки датасета. Популярные решения для автоматической разметки изображений: Google’s Vision API, Cloud Annotation Tool (IBM), Computer Vision Annotation Tool (Intel).
Набирают популярность методы ускорения и упрощения моделей для их повсеместного внедрения. Модели становятся всё более универсальными, легко адаптируемыми для конкретных задач, одновременно становясь всё менее ресурсоёмкими. Многие исследователи и компании (в основном это крупные корпорации) выкладывают в общий доступ уже обученные модели, которые далее любая заинтересованная сторона может обучить на собственном датасете под свои конкретные задачи. Такой подход позволяет сэкономить вычислительные мощности, необходимые для обучения моделей.
Аналитики предсказывают наиболее активное развитие и применение технологий компьютерного зрения в автономных транспортных средствах, системах биометрического сканирования и распознавания лиц для повышения безопасности ценных активов, системах контроля качества продукции, автоматизации процессов производства в промышленности.
В прилагаемой аналитической справке кроме описания моделей, алгоритмов и конкретных проектов также приведены примеры и описания наиболее популярных библиотек и инструментов для создания приложений компьютерного зрения, датасеты, используемые для построения моделей компьютерного зрения, а также существующие механизмы поиска подходящего датасета.
Технологии компьютерного зрения могут быть использованы для выявления противоправного контента, однако на современном уровне развития модели требуют дополнительной обработки результатов специалистами в ручном режиме.
Компьютерное зрение: технологии, компании, тренды
Оглавление
Механизмы поиска подходящего датасета
Наиболее популярные датасеты для компьютерного зрения
Введение
Computer vision (CV) – совокупность технологий, методов и алгоритмов, с помощью которых компьютер может обрабатывать изображения и видеопоток. Использование компьютерного зрения позволяет определять, что изображено, классифицировать эти изображения и анализировать их.
Основные сферы применения: видеонаблюдение и безопасность, распознавание лиц, сельское хозяйство, зрение для роботов, контроль качества на производстве, системы обнаружения бокового трафика в автомобилестроении, автономные транспортные средства, обработка медицинских изображений для постановки диагноза, фильтрация нежелательного контента, выявление фейковых фотографий, актуализация и кастомизация рекламы, наложение фильтров на фото и видео.
Разработчики компьютерного зрения чаще всего используют языки Python или С++, а также специализированные библиотеки. Регулярно пополняются датасеты для обучения нейронных сетей, проводятся соревнования для поиска лучших решений.
Компьютерное зрение работает в три основных этапа:
- Получение изображения. Изображения, даже большие, можно получать в режиме реального времени с помощью видео, фотографий или 3D-технологий для анализа.
- Обработка изображения. Модели глубокого обучения автоматизируют большую часть этого процесса, но модели часто обучаются, сначала получая тысячи помеченных или предварительно идентифицированных изображений.
- Понимание изображения. Последний этап – это этап интерпретации, когда объект идентифицируется или классифицируется.
В части понимания изображения современные системы ИИ могут применяться следующим образом:
- Сегментация изображения: разбивает изображение на несколько областей или фрагментов для отдельного исследования.
- Обнаружение объекта: идентифицирует конкретный объект на изображении. Расширенное обнаружение объектов распознает множество объектов в одном изображении: футбольное поле, нападающий, защитник, мяч и так далее. Эти модели используют координаты X, Y, чтобы создать ограничивающую рамку и идентифицировать все внутри нее.
- Распознавание лиц: расширенный тип обнаружения объектов, который не только распознает человеческое лицо на изображении, но и идентифицирует конкретного человека.
- Обнаружение края: метод, используемый для определения внешнего края объекта или ландшафта, чтобы лучше определить, что находится на изображении.
- Распознавание образов: процесс распознавания повторяющихся форм, цветов и других визуальных индикаторов на изображениях.
- Классификация изображений: группирует изображения в разные категории.
- Сопоставление признаков: тип обнаружения шаблонов, который сопоставляет сходства в изображениях, чтобы помочь их классифицировать.
Простые приложения компьютерного зрения используют только один из этих методов, но более сложные, такие как компьютерное зрение для автомобилей с самостоятельным вождением, полагаются на различные методы для достижения своей цели.
Библиотеки и инструменты
Наиболее популярные библиотеки и инструменты для создания приложений компьютерного зрения:
|
Amazon Rekognition |
Платформа, выделяющаяся на фоне аналогов возможностью глубокого анализа попавших в объектив камеры предметов, сооружений и людей. Данный сервис является частью системы с интегрированным механизмом полномасштабного самообучения. Ключевой особенностью сервиса значится «глубокий анализ» – способность не просто уведомить пользователя, что на картинке был обнаружен кот или собака, а с высокой точностью указать даже породу животного. А при использовании Amazon Rekognition для распознавания лица программное обеспечение без труда определит по внешним признакам текущее эмоциональное состояние исследуемой личности. Методика включает в себя сравнение двух изображений на основе миллионов признаков. |
|
BoofCV |
Библиотека Java с открытым исходным кодом для приложений робототехники и компьютерного зрения в реальном времени, которая распространяется под лицензией Apache 2.0 как для обучения, так и для бизнеса. Функциональность охватывает широкий круг вопросов, включая оптимизированные процедуры обработки изображений на низком уровне, выравнивание камеры, обнаружение/отслеживание функций, определение структуры по движению и распознавание. |
|
CUDA |
Продукт NVIDIA для параллельных вычислений, которые просты в программировании, очень эффективны и быстры. Используя мощность графических процессоров, обеспечивает высокую производительность. Набор инструментов включает библиотеку NVIDIA Performance Primitives, содержащую набор функций обработки изображений, сигналов и видео. |
|
GPUImage |
Структура, основанная на OpenGL ES 2.0, которая позволяет применять эффекты и каналы с ускорением на графическом процессоре (GPU) к живому движущемуся видео, изображениям и фильмам. Для запуска пользовательских каналов на GPU требуется много кода для настройки и поддержки. |
|
Keras |
Библиотека Python для глубокого обучения, которая объединяет элементы разных библиотек, например, Tensorflow, Theano и CNTK. Keras занимает выгодное положение по сравнению с конкурентами, например, Scikit-learn и PyTorch, поскольку работает поверх Tensorflow. Также может работать на Microsoft Cognitive Toolkit, Theano или PlaidML. Предназначена для быстрых экспериментов с глубокими нейронными сетями, сосредоточена на удобстве, измеряемом качестве и расширяемости. Keras следует лучшим практикам для снижения когнитивной нагрузки: предлагает стабильные и базовые API-интерфейсы и ограничивает количество действий пользователя, необходимых для обычных случаев использования. |
|
Matlab |
Инструмент для создания приложений для обработки изображений, обычно используется в исследовательских целях, поскольку позволяет быстро создавать прототипы. Код Matlab очень лаконичен по сравнению с C ++, что упрощает детектирование и устранение неисправностей. Проводит предварительную проверку кода перед выполнением, предлагая несколько различных способов ускорить код. |
|
OpenCV |
Самая известная библиотека, многоплатформенная и простая в использовании. Охватывает все основные стратегии и алгоритмы для выполнения некоторых задач обработки изображений и видео, превосходно работает с C ++ и Python. |
|
SimpleCV |
Система для создания приложений компьютерного зрения. Предоставляет доступ к большому количеству инструментов компьютерного зрения, схожих с OpenCV, pygame и т. д. Не требует глубокого погружения в тему. Подходит для быстрого создания прототипов. |
|
Tensorflow |
Бесплатная библиотека с открытым исходным кодом для потоков данных и дифференциального программирования. Это символьная математическая библиотека, которая дополнительно используется для приложений машинного обучения, например, нейронных сетей. Известность быстро возросла и превзошла существующие библиотеки из-за простоты API. |
|
Theano |
Быстрая числовая библиотека Python, которая может работать на CPU или GPU. Она была создана группой LISA (в настоящее время MILA) в Монреальском университете в Канаде. Theano – это улучшенный компилятор для управления и оценки математических выражений, особенно матричных. |
Датасеты
Механизмы поиска подходящего датасета
Датасет изображений или видео является основополагающим элементом для создания эффективно работающей модели компьютерного зрения. Как ответ потребностям сообщества разработчиков появились коллекции датасетов и инструменты поиска подходящего датасета. Ниже представлены некоторые из них:
|
Find Datasets|CMU Libraries |
Коллекция датасетов, предоставленная университетом Карнеги Меллон. |
|
Google Dataset Search |
Позволяет осуществлять поиск по ключевому слову из 25 миллионов открытых датасетов. Наиболее популярным форматом данных являются таблицы – более 6 миллионов в Dataset Search. |
|
Kaggle |
Площадка для соревнований по машинному обучению с множеством интересных датасетов. В списке датасетов можно найти разные нишевые экземпляры. |
|
NAS (Neural Architecture Search) |
Алгоритм выбора архитектуры нейросети и оптимизации ее гиперпараметров под конкретный датасет и задачу (классификация, сегментация и др.). NAS является подмножеством AutoML. Алгоритм NAS находит архитектуру из всех возможных архитектур, следуя стратегии поиска, которая максимизирует производительность. |
|
UCI Machine Learning Repository |
Один из старейших источников датасетов в сети Интернет. Датасеты добавляются пользователями. Данные можно скачивать сразу, без регистрации |
|
VisualData |
Датасеты для компьютерного зрения, разбитые по категориям. Доступен поиск. |
Наиболее популярные датасеты для компьютерного зрения
AViD. Публичный датасет с анонимизированными видеозаписями из разных стран. Датасет предназначен для задачи распознавания действий. AViD состоит из видео, где человек выполняет одно действие (всего – 887).
CelebA-Spoof. Датасет для антиспуфинга, который состоит из 625 537 изображений 10 177 людей. Антиспуфинг лица – это методы борьбы с обманом систем по распознаванию лиц. Датасет включает в себя 43 атрибута: детали лица, освещение, среду и тип обмана. CelebA-Spoof создали на основе датасета CelebA. Изображения из CelebA модифицировали и аннотировали.
CIFAR-10 и CIFAR-100 (Canadian Institute For Advanced Research). Одни из наиболее популярных открытых датасетов, используемых исследователями для обучения алгоритмов машинного зрения. Состоят из 60 000 цветных изображений размером 32×32 (5 обучающих выборок, по 10 000 изображений в каждой и одна тестовая выборка, содержащая 10 000 изображений). При этом, в CIFAR-10 все изображения разделены на 10 классов (по 6000 изображений в каждом классе), а в CIFAR-100 – на 100 классов (по 600 изображений в каждом классе).
CINIC-10. Расширение CIFAR-10, содержит изображения из CIFAR-10 и набор изображений из базы данных ImageNet. Был скомпилирован как «мост» между CIFAR-10 и ImageNet для тестирования приложений машинного обучения. Изображения разделены на три группы: обучающая, проверочная и тестовая выборки (каждая из групп содержит 90 000 изображений).
COIL100. 100 разных объектов, изображённых под каждым углом в круговом обороте.
Google’s Open Images. Коллекция из 9 миллионов URL-адресов к изображениям, «которые были помечены метками, охватывающими более 6000 категорий» под лицензией Creative Commons.
Open Images V4. Одна из версий датасета Open Images. V4 содержит 14,6 миллиона границ объектов для объектов 600 классов.
Open Images V6. В последней версии датасета появились так называемые «локализованные нарративы» для 500 тысяч изображений. Это новый вид мультимодальной разметки, в которой синхронизированы текст аннотации, начитка и движения указателя мыши по описываемым предметам. Значительно расширены типы разметки визуальных взаимосвязей между объектами на изображениях (например, «человек катается на скейтборде», «собака ловит летящий диск»). Также добавлено 2,5 млн разметок человеческих действий («прыгает», «улыбается») и 23,5 млн меток изображений.
Hypersim. Датасет от Apple с фотореалистичными синтетическими изображениями интерьеров. Для каждого изображения доступны попиксельная разметка объектов и геометрия сцены. Датасет состоит из 77,4 тысяч изображений 461 сцены.
ImageNet. Датасет изображений для новых алгоритмов, организованный в соответствии с иерархией WordNet, в которой сотни и тысячи изображений представляют каждый узел иерархии. Состоит из более чем 15 миллионов размеченных высококачественных изображений, разделенных на 22 000 категорий.
ImageNet-A – это датасет с примерами изображений, которые нейросеть не может классифицировать верно. По результатам, модели предсказывали объекты из датасета с точностью в 3%, в то время как для стандартного ImageNet точность предсказаний составляла 97%. ImageNet-A был собран исследователями из University of Berkeley, University of Washington и University of Chicago.
Данные состоят из 7,5 тысяч изображений объектов, которые нейросети сложно классифицировать. Эти объекты – это «естественные состязательные примеры» для нейросетей. Особенность изображений в том, что они содержат естественные оптические иллюзии, которые нейросеть не может распознать.
Indoor Scene Recognition. Датасет для распознавания интерьера зданий. Содержит 15 620 изображений и 67 категорий.
Labelled Faces in the Wild. Набор из 13 000 размеченных изображений лиц людей для использования приложений, которые предполагают использование технологии распознавания лиц.
Labelme. Датасет состоит их 187 240 изображений, 62 197 изображений с аннотациями и 658 992 помеченных объекта. В LabelMe также есть инструмент для удобной аннотации изображения для создания датасетов.
LaSOT. Масштабный датасет для обучения и оценки моделей трекинга объектов. Датасет содержит 1,5 тысяч видеоклипов с объектами 85 разных классов. Всего в датасете более 3,87 миллионов кадров. Каждый клип содержит разметку для одного объекта. Границы объекта на кадрах размечали вручную.
LSUN. Датасет изображений, разбитых по сценам и категориям с частичной разметкой данных, содержит более 9 млн изображений.
MoGaze. Датасет с передвижениями тела и движениями взгляда. Датасет собирали для обучения моделей предсказания действия людей. Такие модели можно использовать в роботизированных системах, тесно взаимодействующих с людьми. Датасет включает в себя 180 минут данных движения с 1 627 действиями поднять-поставить.
MS COCO (Microsoft Common Objects in Context). Набор данных для обнаружения, сегментации, обнаружения ключевых точек и аннотаций. Набор данных состоит из 328 тысяч изображений с более чем 1,5 миллионов объектов на них. Все объекты находятся в их естественном окружении (контексте). Изображения, как правило, содержат объекты разных классов (только 10% имеют единственный класс). Все изображения сопровождаются аннотациями, хранящихся в json формате.
COCO-WholeBody. Первый датасет для оценки позы всего тела. COCO-WholeBody является расширением датасета COCO 2017 с теми же разбивками на тренировочную и валидационную выборки, как в COCO. Для каждого человека доступны 4 типа границ объектов: бокс человека, бокс лица, бокс левой руки и бокс правой руки. Кроме того, 133 ключевые точки: 17 для тела, 6 для ног, 68 для лица и 42 для рук. Датасет доступен исключительно для исследовательских целей. Коммерческое использование запрещено.
Visual Genome. Датасет с ~100 тыс. изображений, каждое из которых имеет в среднем 35 объектов, 26 атрибутов и 21 парную связь между объектами.
xView. Один из самых больших общедоступных наборов воздушных снимков земли. Он содержит изображения различных сцен со всего мира, аннотированных с помощью ограничительных рамок. Состоит из более
1 миллиона экземпляров объектов 60 различных классов.
Алгоритмы и модели
Метод Виолы-Джонса (Viola–Jones object detection) – алгоритм, позволяющий обнаруживать объекты на изображениях в реальном времени. Его предложили Паул Виола и Майкл Джонс в 2001 году.
Основные принципы, на которых основан метод, таковы:
- используются изображения в интегральном представлении, что позволяет быстро вычислять необходимые объекты;
- используются признаки Хаара, с помощью которых происходит поиск нужного объекта (например, лица и его черт);
- используется бустинг (от англ. boost – улучшение, усиление) для выбора наиболее подходящих признаков для искомого объекта на данной части изображения;
- все признаки поступают на вход классификатора, который даёт результат «верно» либо «ложь»;
- используются каскады признаков для быстрого отбрасывания окон, где не найдено лицо.
Обучение классификаторов идет очень медленно, но результаты поиска лица очень быстры, именно поэтому данный метод часто используется для распознавания лиц на изображении.
Гистограмма направленных градиентов (Histogram of Oriented Gradients, HOG) – дескрипторы особых точек, которые используются в компьютерном зрении и обработке изображений с целью распознавания объектов. Данная техника основана на подсчете количества направлений градиента в локальных областях изображения.
Основной идеей алгоритма является допущение, что внешний вид и форма объекта на участке изображения могут быть описаны распределением градиентов интенсивности или направлением краев. Реализация этих дескрипторов может быть произведена путём разделения изображения на маленькие связные области, именуемые ячейками, и расчетом для каждой ячейки гистограммы направлений градиентов или направлений краев для пикселей, находящихся внутри ячейки. Комбинация этих гистограмм и является дескриптором. Для увеличения точности локальные гистограммы подвергаются нормализации по контрасту. С этой целью вычисляется мера интенсивности на большем фрагменте изображения, который называется блоком, и полученное значение используется для нормализации. Нормализованные дескрипторы обладают лучшей инвариантностью по отношению к освещению.
Дескриптор HOG имеет несколько преимуществ над другими дескрипторами. Поскольку HOG работает локально, метод поддерживает инвариантность геометрических и фотометрических преобразований, за исключением ориентации объекта. Подобные изменения появятся только в больших фрагментах изображения. Более того, как обнаружили Далал и Триггс, грубое разбиение пространства, точное вычисление направлений и сильная локальная фотометрическая нормализация позволяют игнорировать движения пешеходов, если они поддерживают вертикальное положение тела. Дескриптор HOG, таким образом, является хорошим средством нахождения людей на изображениях.

Метод опорных векторов (SVM, support vector machine) – набор схожих алгоритмов обучения с учителем, использующихся для задач классификации и регрессионного анализа. Принадлежит семейству линейных классификаторов и может также рассматриваться как частный случай регуляризации по Тихонову. Особым свойством метода опорных векторов является непрерывное уменьшение эмпирической ошибки классификации и увеличение зазора, поэтому метод также известен как метод классификатора с максимальным зазором.
Основная идея метода – перевод исходных векторов в пространство более высокой размерности и поиск разделяющей гиперплоскости с максимальным зазором в этом пространстве. Две параллельных гиперплоскости строятся по обеим сторонам гиперплоскости, разделяющей классы. Разделяющей гиперплоскостью будет гиперплоскость, максимизирующая расстояние до двух параллельных гиперплоскостей. Алгоритм работает в предположении, что чем больше разница или расстояние между этими параллельными гиперплоскостями, тем меньше будет средняя ошибка классификатора.
AlexNet – первая глубокая сверточная нейронная сеть. Разработчики сети выиграли конкурс по классификации изображений LSVRC-2012 на наборе данных ImageNet.
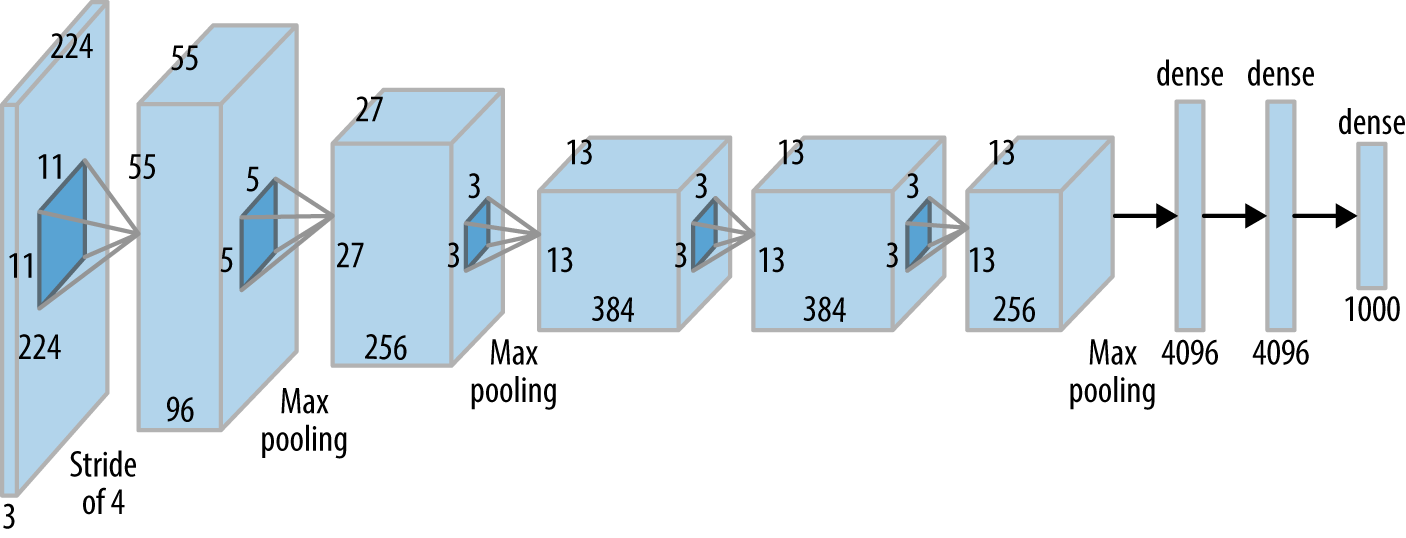
Особенности модели:
- Вход сети – трехканальное изображение 224х224 пикселя.
- В качестве функции активации используется «положительная срезка» (Rectified Linear Unit, ReLUФункция активации, определяемая как положительная часть ее аргумента). За счет этого при одинаковой точности метода скорость становится в 6 раз быстрее.
- Использование дропаута вместо регуляризации решает проблему переобучения. Однако время обучения удваивается с показателем дропаута 0,5.
- Использование слоев пространственного объединения с перекрытиями (overlapping pooling).
- Локальная нормализация выходов (Local Response Normalization, LRN) – нормализация выходных значений по размерности, соответствующей глубине выходной карты признаков.
Сложность модели:
- Сеть содержит 62,3 млн параметров.
- Прямой проход требует выполнения ~1 миллиарда операций.
- Сверточные слои, на которые приходится 6% всех параметров, производят 95% вычислений.
Особенности обучения:
- Высокая скорость обучения за счет использования функции активации ReLU.
- Увеличение количества данных (data augmentation) за счет применения операций сдвига и зеркального отражения.
- Обучение на двух видеокартах.
OverFeat – модель сверточной нейронной сети, которая предназначена для того, чтобы одновременно (т.е. одной сетью) решать три задачи: детектировать объект, классифицировать его и уточнять положение на снимке (detection, recognition, and localization).
Представляет собой многомасштабный алгоритм скользящего окна с использованием сверточных нейронных сетей.
Отличия от модели AlexNet:
- Отсутствие пространственного объединения с перекрытиями (замена размера ядра с 3×3 на 2×2).
- Отсутствие локальной нормализации выходов на первом и третьем слоях.
- Применение многомасштабной классификации изображения (multiscale classification).
- Объекты на изображении разного размера.
- Идея – классифицировать разные масштабы изображения и принимать интегральное решение.
- Используется 6 разных масштабов входного изображения, для которых строятся карты признаков (выход слоя 5).
Полученные карты признаков объединяются и передаются на вход классификатору, который формирует финальное решение о принадлежности изображения классу
VGG16 – модель сверточной нейронной сети, предложенная K. Simonyan и A. Zisserman из Оксфордского университета в статье «Very Deep Convolutional Networks for Large-Scale Image Recognition». Модель достигает точности 92.7% – топ-5, при тестировании на ImageNet в задаче распознавания объектов на изображении. Этот датасет состоит из более чем 14 миллионов изображений, принадлежащих к 1000 классам.
VGG16 – одна из самых знаменитых моделей, отправленных на соревнование ILSVRC-2014. Она является улучшенной версией AlexNet, в которой заменены большие фильтры (размера 11 и 5 в первом и втором сверточном слое, соответственно) на несколько фильтров размера 3х3, следующих один за другим. Сеть VGG16 обучалась на протяжении нескольких недель при использовании видеокарт NVIDIA TITAN BLACK.
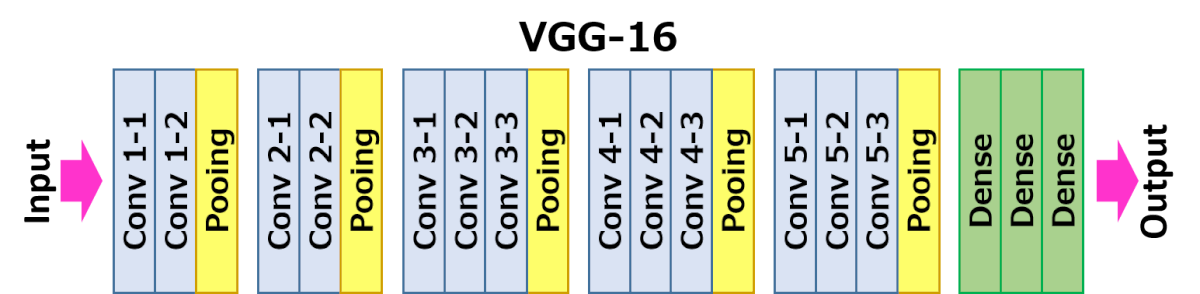
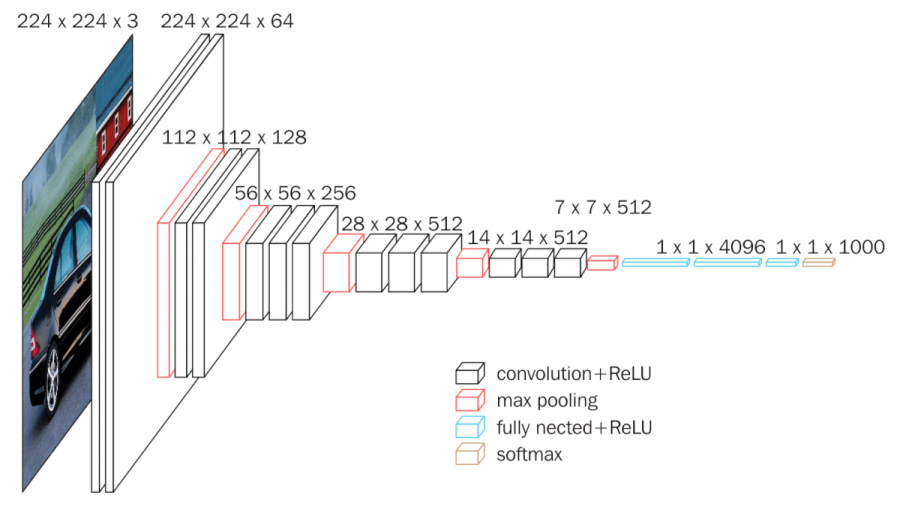
На вход слоя conv1 подаются RGB изображения размера 224х224. Далее изображения проходят через стек сверточных слоев, в которых используются фильтры с очень маленьким рецептивным полем размера 3х3 (который является наименьшим размером для получения представления о том, где находится право/лево, верх/низ, центр).
В одной из конфигураций используется сверточный фильтр размера 1х1, который может быть представлен как линейная трансформация входных каналов (с последующей нелинейностью). Сверточный шаг фиксируется на значении 1 пиксель. Пространственное дополнение входа сверточного слоя выбирается таким образом, чтобы пространственное разрешение сохранялось после свертки, то есть дополнение равно 1 для 3х3 сверточных слоев. Пространственный пулинг осуществляется при помощи пяти max-pooling слоев, которые следуют за одним из сверточных слоев (не все сверточные слои имеют последующие max-pooling). Операция max-pooling выполняется на окне размера 2х2 пикселей с шагом 2.
После стека сверточных слоев (который имеет разную глубину в разных архитектурах) идут три полносвязных слоя: первые два имеют по 4096 каналов, третий – 1000 каналов (так как в соревновании ILSVRC3Проект ILSVRC (ImageNet Large Scale Visual Recognition Challenge, Кампания по широкомасштабному распознаванию образов в ImageNet) различные программные продукты ежегодно соревнуются в классификации и распознавании объектов и сцен в базе данных ImageNet, ведётся c 2010 года. требуется классифицировать объекты по 1000 категорий; следовательно, классу соответствует один канал). Последним идет soft-max слой. Конфигурация полносвязных слоев одна и та же во всех нейросетях.
Все скрытые слои снабжены ReLU. Отметим также, что сети (за исключением одной) не содержат слоя нормализации (Local Response Normalisation), так как нормализация не улучшает результата на датасете ILSVRC, а ведет к увеличению потребления памяти и времени исполнения кода.
Сеть VGG имеет два серьезных недостатка:
- Очень медленная скорость обучения.
- Сама архитектура сети весит слишком много (что создает проблемы с диском и пропускной способностью).
Из-за глубины и количества полносвязных узлов VGG16 весит более 533 МБ. Это осложняет процесс развертывания VGG. Хотя VGG16 и используется для решения многих проблем классификации при помощи нейронных сетей, меньшие архитектуры более предпочтительны (SqueezeNet, GoogLeNet и другие). Несмотря на недостатки, данная архитектура удобна для обучения, так как её легко реализовать.
SEER – это самообучающаяся нейросеть с миллиардом параметров от FAIR для задач компьютерного зрения. Предобученную на снимках из Instagram модель можно дообучать на своих задачах. Разработчики опубликовали библиотеку VISSL для обучения SEER модели.
SEER объединяет в себе архитектуру RegNet и формат онлайн самостоятельного обучения. В качестве алгоритма для онлайн обучения использовали SwAV. RegNet, в свою очередь, – это масштабируемая сверточная нейросеть, которая позволяет обходить ограничения по времени обучения и памяти. Такая комбинация позволяет SEER масштабироваться до миллиардов параметров и обучающих изображений.
После предобучения на миллиарде случайных, неразмеченных изображений из Instagram SEER обошла большинство наиболее прогрессивных самообучаемых моделей. По результатам экспериментов, максимальная точность предсказаний нейросети составила 84,2% на датасете ImageNet.
SEER также обошла наиболее успешные на данный момент подходы обучения с учителем на таких задачах, как low-shot (изучение концепций через малое количество примеров), детектирование объектов, сегментация и классификация изображений.
Если использовать для обучения 10% изображений из ImageNet, максимальная точность SEER составляет 77,9% для всего ImageNet. Если обучать нейросеть на 1% размеченных изображений из ImageNet, точность составит 60,5%.
Результаты SEER показывают, что формат самостоятельного обучения подходит и для задач компьютерного зрения.
NBDT (Neural-Backed Decision Trees, NBDTs) – это нейросетевая архитектура деревьев решений для задач классификации. Модель объединяет в себе интерпретируемость классического алгоритма дерева решений с качеством предсказаний современных нейросетей. Разработчики тестировали модель на задаче классификации изображений.
NBDTs заменяют последний слой нейросети дифференцируемой последовательностью решений с особой функцией потерь. Это позволяет модели выучивать высокоуровневые концепты и снижает нестабильность предсказаний. В отличие от стандартной нейросети, NBDT выдает последовательные решения, которые привели к предсказанию.
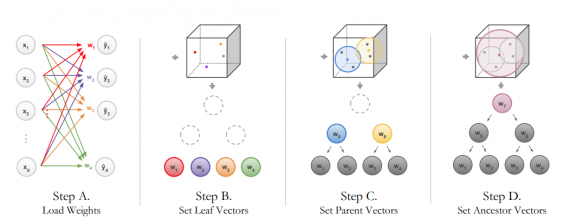
Процесс обучения итогового слоя модели
Модель находится в препринте, публикация планируется в мае 2021, но согласно сравнению разработчиков, результаты работы модели близки к наиболее успешным в настоящий момент подходам на датасетах CIFAR и ImageNet.
YOLO (You Only Look Once) – это семейство моделей, которые стали популярны благодаря легковесности и качеству предсказаний. Такие характеристики позволяю использовать YOLO для задач распознавания объектов в реальном времени и на портативных устройствах.
YOLO – это система обнаружения объектов в реальном времени, созданная Джозефом Редмоном и Али Фархади из Вашингтонского университета. Их алгоритм применяет нейронную сеть ко всему изображению, а нейронная сеть разделяет изображение на сетку и запечатлевает районы с обнаруженными элементами.

Scaled YOLO v4 на датасете Microsoft COCO достигает точности 55,8%, что делает ее одной из самых точных нейронных сетей для обнаружения объектов. Scaled YOLO v4 превосходит по точности нейронные сети: Google; Amazon; Microsoft; Facebook.
Faster R-CNN разработан на основе R-CNN и следующей ее версии Fast R-CNN, где для локализации объекта вместо избирательного поиска используется Region Proposal Networks (сеть позволяет генерировать предлагаемые регионы нахождения объектов на основе последней сверточной карты признаков). Архитектура Faster R-CNN образована следующим образом:
Изображение подается на вход сверточной нейронной сети. Так, формируется карта признаков. Карта признаков обрабатывается слоем RPN. Здесь скользящее окно проходится по карте признаков. Центр скользящего окна связан с центром якорей. Якоря – это области, имеющие разные соотношения сторон и разные размеры. Авторы используют 3 соотношения сторон и 3 размера. На основе метрики IoF (intersection-over-union), степени пересечения якорей и истинных размеченных прямоугольников, выносится решение о текущем регионе – есть объект или нет. Далее используется алгоритм FastCNN: карта признаков с полученными объектами передаются слою RoI с последующей обработкой полносвязных слоев и классификацией, а также с определением смещения регионов потенциальных объектов.
Модель Faster R-CNN справляется немного хуже с локализацией, но работает быстрее Fast R-CNN.
На TensorFlow4Открытая программная библиотека для машинного обучения, поддерживаемая Google. tensorflow.org есть ряд предобученных моделей, использующих данный метод.
ResNet (Residual Network, «остаточная сеть») – модель глубокой нейронной сети для классификации изображений. Создана Microsoft, чтобы преодолеть проблему снижения точности предсказаний с увеличением количества слоев в нейронных сетях.
Microsoft ввела глубокую «остаточную» структуру обучения. Вместо того, чтобы надеяться на то, что каждые несколько упорядоченных слоев непосредственно соответствуют желаемому основному представлению, они явно позволяют этим слоям соответствовать «остаточному». Формулировка F(x) + x может быть реализована с помощью нейронных сетей с соединениями для быстрого доступа.

Идентификационные быстрые соединения F (x {W} + x) могут использоваться непосредственно, когда вход и выход имеют одинаковые размерности (быстрые соединения сплошной линии). Когда размерности увеличиваются (пунктирные линии), он рассматривает два варианта:
- Быстрое соединение выполняет сопоставление идентификаторов с дополнительными нулями, добавленными для увеличения размерности. Эта опция не вводит никаких дополнительных параметров.
- Проекция быстрого соединения в F (x {W} + x) используется для сопоставления размерностей (выполнено с помощью 1×1 сверток).
Соединения быстрого доступа (shortcut connections) пропускают один или несколько слоев и выполняют сопоставление идентификаторов. Их выходы добавляются к выходам упорядоченных слоев. Используя ResNet, можно решить множество проблем, таких как:
- ResNet относительно легко оптимизировать: «простые» сети (которые просто складывают слои) показывают большую ошибку обучения, когда глубина увеличивается.
- ResNet позволяет относительно легко увеличить точность благодаря увеличению глубины, чего с другими сетями добиться сложнее.
EfficientNets – класс моделей, цель разработки которых сохранить высокое качество решения задачи и повысить эффективность модели (уменьшить количество параметров и снизить вычислительную сложность)
При правильном конструировании моделей масштабирование по любому размеру сети (глубина, разрешение входного изображения, ширина – количество каналов в картах признаков) приводит к повышению качества решения задачи
Важно сбалансировать все размеры сети (глубину, разрешение и ширину) во время масштабирования сети для получения высокой точности и эффективности.
Авторы предлагают метод составного масштабирования модели (compound scaling method). Вводится составной коэффициент ? для равномерного масштабирования глубины, ширины и разрешения
EfficientNet-B0 – базовая нейронная сеть, построенная с использованием инвертированных остаточных блоков, которые введены в MobileNetV2.
EfficientNet-B1,…,B7 получены в результате поиска оптимального соотношения параметров глубины, ширины и разрешения с использованием предложенного метода масштабирования.
Meta Pseudo Labels (EfficientNet-L2). Для обучения модели EfficientNet использовался полу-контролируемый метод Meta Pseudo Labels (MPL). Одна сеть EfficientNet-L2 используется в таком случае в качестве учителя, а вторая – ученика. Учителем генерируются псевдо-метки на неразмеченных изображениях из датасета, которые затем смешиваются с правильно размеченными данными для формирования обучающей выборки.
В процессе обучения учитель получает сигналы о том, насколько хорошо ученик выполняет мини-пакет, взятый из помеченного набора данных. После чего может изменять метки с целью лучшего обучения.
Полученная сеть достигает максимальной точности 90,2% по проверочному набору ImageNet ILSVRC 2012, став лучшей сетью для классификации изображений на данном датасете.
U-Net считается одной из стандартных архитектур сверточных нейронных сетей для задач сегментации изображений, когда нужно не только определить класс изображения целиком, но и сегментировать его области по классу, т. е. создать маску, которая будет разделять изображение на несколько классов. Архитектура состоит из стягивающего пути для захвата контекста и симметричного расширяющегося пути, который позволяет осуществить точную локализацию. Сегментация изображения 512×512 занимает менее секунды на современном графическом процессоре.
Для U-Net характерно:
- достижение высоких результатов в различных реальных задачах, особенно для биомедицинских приложений;
- использование небольшого количества данных для достижения хороших результатов.
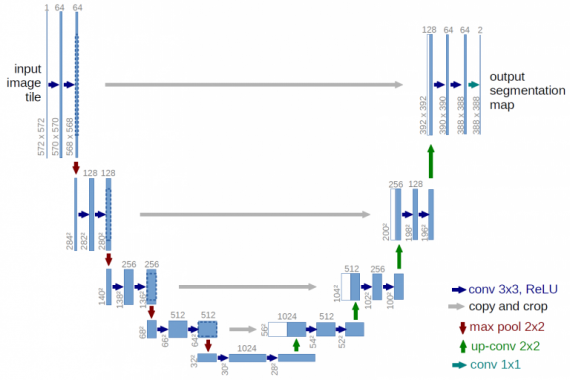
Архитектура U-Net (пример изображения с разрешением 32×32 пикселя – самым низким). Каждый синий квадрат соответствует многоканальной карте свойств. Количество каналов приведено в верхней части квадрата. Размер x-y приведен в нижнем левом краю квадрата. Белые квадраты представляют собой копии карты свойств. Стрелки обозначают различные операции.
Архитектура сети приведена на рисунке. Она состоит из сужающегося пути (слева) и расширяющегося пути (справа). Сужающийся путь – типичная архитектура сверточной нейронной сети. Он состоит из повторного применения двух сверток 3×3, за которыми следуют инит ReLU и операция максимального объединения (2×2 степени 2) для понижения разрешения.
На каждом этапе понижающей дискретизации каналы свойств удваиваются. Каждый шаг в расширяющемся пути состоит из операции повышающей дискретизации карты свойств, за которой следуют:
- свертка 2×2, которая уменьшает количество каналов свойств;
- объединение с соответствующим образом обрезанной картой свойств из стягивающегося пути;
- две 3×3 свертки, за которыми следует ReLU.
Обрезка необходима из-за потери граничных пикселей при каждой свертке.
На последнем слое используется свертка 1×1 для сопоставления каждого 64-компонентного вектора свойств с желаемым количеством классов. Всего сеть содержит 23 сверточных слоя.
Архитектура U-Net достигает выдающейся производительности и точности в самых разных приложениях биомедицинской сегментации. Метод требует лишь нескольких помеченных изображений для тренировки и имеет приемлемое время обучения: всего лишь 10 часов на графическом процессоре NVidia Titan (6 ГБ).
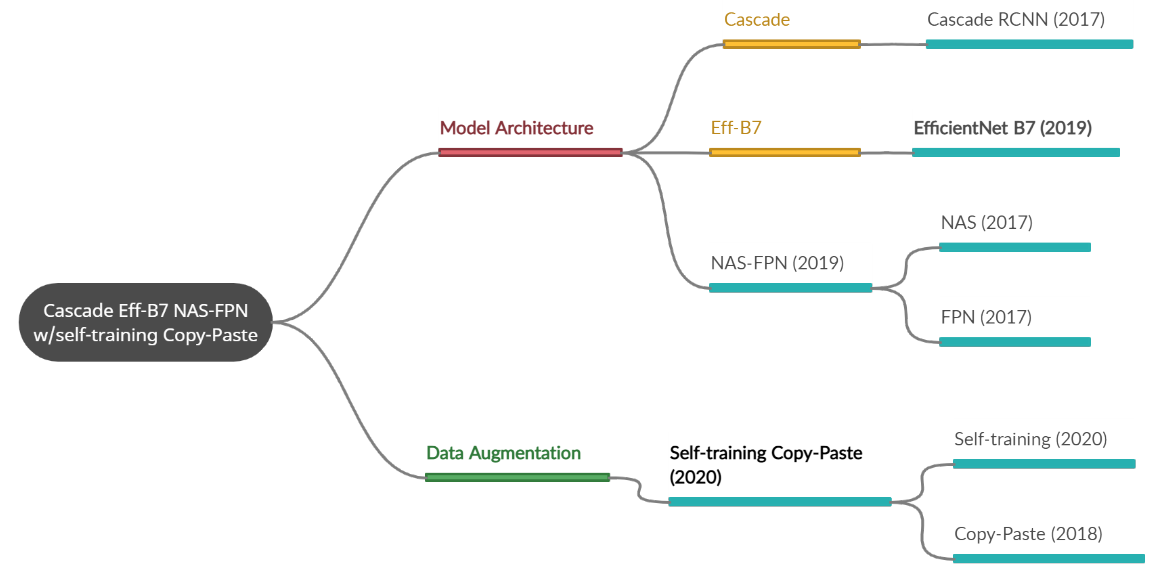
Cascade Eff-B7 NAS-FPN with Self-training and Copy-Paste – модель обнаружения объектов, основанная на нескольких методах сразу. Так, с помощью случайно вставки изображений в исходные данные была улучшена работа базовых моделей нейронных сетей, а использование в дополнение к данному методу псведо-маркировки для обучения модели позволило значительно улучшить выходные предсказания.
Данная модель на датасете Microsoft COCO достигает точности 57%, что делает ее самой точной нейронной сетью для обнаружения объектов (данные – март 2021).
Все использованные методы для создания модели были представлены автором на рисунке и условно разделены на две части: изменения данных и архитектурная модель.
LambdaNetworks – это нейросетевая архитектура, которая способна захватывать длительные зависимости между входными данными и контекстуальной информацией. Например, пиксель, окруженный другими пикселями. Итоговая архитектура LambdaNetwork требует меньше вычислительных ресурсов и является простой в имплементации в сравнении с альтернативными подходами.
Ключевая особенность структуры сети – это лямбда слой, который учитывает такие зависимости с помощью трансформации доступных контекстов в линейные функции (лямбды). Затем лямбды применяются к каждому входному объекту по отдельности. Лямбда слои могут быть имплементированы в модели для глобальных, локальных и маскированных контекстов.
Линейные функции противопоставляются картам внимания, которые повсеместно используются в наиболее прогрессивных нейросетевых архитектурах. Карты внимания являются дорогими для вычисления.
Исследователи проводили эксперименты на трех задачах: классификации изображений на данных ImageNet и распознавание объектов и сегментация сущностей на данных COCO. LambdaNetworks обходят сверточные архитектуры и архитектуры с механизмом внимания. При этом предложенные модели более вычислительно эффективны.
LambdaResNets – это семейство LambdaNetworks моделей, которые адаптированы под задачу классификации изображений. LambdaResNets выдают предсказания, сравнимые с наиболее успешных в настоящее время моделями на ImageNet, при том, что обучаются в 4,5 раза быстрее EfficientNets.
Компании и проекты
Иностранные компании | |
|
| Google Cloud Vision API – платформа для тренировки алгоритмов Computer Vision, в которую входит: Label Detection – классификация изображений. OCR – распознавание текста. Explicit Content Detection – фильтрация негативного контента. Facial Detection – распознавание лиц. Landmark Detection – распознавание геолокации по фото.Logo Detection – детектирование символов. Image Properties – детекция отдельных атрибутов изображения.Perception – технология понимания сенсорных данных, внедряемая во все продукты компании, включающая распознавание изображений в Google Фото, улучшение качества фото с камеры Pixel Phone, интерфейсы рукописного ввода Android, оптическое распознавание символов в Google Drive, понимание видео YouTube, Google Cloud, Google Фото и Nest, а также компьютерное зрение для мобильных приложений, таких как Motion Stills, PhotoScan и Allo. |
|
| Detectron2 – библиотека машинного зрения на основе PyTorch. ResNeXt – простая высокомодульная сетевая архитектура для классификации изображений. Алгоритмы машинного зрения используются в Facebook для фильтрации нежелательного контента, в том числе видеоконтента, выявления фейковых фотографий, актуализации и кастомизации рекламы.Многие возможности Instagram (фильтры, маски, быстрое редактирование фотографий и сториз) обусловлены алгоритмами машинного зрения. |
|
Microsoft | Azure Cognitive Services – облачный сервис предоставляет разработчикам API для доступа к расширенным алгоритмам обработки изображений и возврата данных. Bing image recognition – в поисковике Bing от Microsoft используются алгоритмы компьютерного зрения. InnerEye – проект по созданию инструментов для автоматического количественного анализа трехмерных медицинских изображений. |
|
NVIDIA | NVIDIA Jetson Nano – система для автономного транспорта на базе графических ускорителей NVIDIA. Решение открывает новые возможности для встроенных IoT-приложений, в том числе для видеорегистраторов начального уровня, домашних роботов и интеллектуальных шлюзов с возможностями аналитики. NVIDIA Metropolis – фреймворк для решения задач видеоаналитики. NVIDIA DeepStream – платформа для быстрого анализа видеопотоков в реальном времени. GPU4Vision, OpenVIDIA – библиотеки для высокопроизводительных вычислений. |
|
Amazon | Amazon Rekognition – позволяет просто встраивать в приложения аналитику изображений и видео на базе глубокого обучения. Требуется только предоставить API Rekognition изображение или видео. Сервис умеет распознавать объекты, людей, текст, сцены и действия, а также обнаруживать неприемлемый контент. Кроме того, Amazon Rekognition с высокой точностью анализирует и распознает лица на изображениях и в видеоматериалах клиента. Amazon использует на десятках своих складов камеры, анализирующие поступающую продукцию. Далее без участия рабочих товары автоматически распределяются по покупательским корзинам. Amazon 13 Go – магазины Amazon, в которых покупатели сканируют на входе свои смартфоны, берут с полок товары и выходят из магазина. Покупка оплачивается автоматически, а чек формируется на основе информации, полученной с камер магазина и обработанной алгоритмами компьютерного зрения. Дроны Amazon, предназначенные для доставки товаров.Системы умного дома Amazon – комплексные решения, включающие дверные звонки с камерами. Echo Look – голосовая колонка с камерой от Amazon, управляемая голосом и дающая рекомендации в области моды и стиля. |
|
Megvii Technology Limited | Face++ – основной продукт компании, онлайн-платформа для распознавания лиц. Крупнейшая в мире платформа компьютерного зрения с открытым исходным кодом. Активно используется полицией Китая. Brain++ – платформа для тренировки моделей, основанных на глубоком обучении. |
|
SenseTime | SenseTime предлагает технологии компьютерного зрения для различных применений:
SensePosture – технология оценки поз (pose estimation). Осуществляет высокоскоростной трекинг движений человека по 17 3D-координатам. Применяется в дополненной и виртуальной реальности. Intelligent cockpit – система компьютерного зрения, разработанная для автомобилей. Включает в себя биометрическую идентификацию пользователя, систему распознавания жестов, облегчающую управление транспортом, а также системы обнаружения сонливости водителя, мониторинга внимания за рулем и выявления опасного вождения. |
|
YITU Technology | Dragonfly Eye System – система видеонаблюдения для большого города, построена на одновременном параллельном анализе видеопотока с десятков тысяч камер. Система применяется для анализа дорожной ситуации и безопасности в городе, автоматически реагируя на сотни событий. В 2019 г. компания объявила о сотрудничестве с городом Сямынь над созданием инфраструктуры умного города на основе технологий компьютерного зрения и интеллектуальной обработки больших данных. Анализ медицинских снимков. China Merchants Bank’s Facial Recognition Project – в 2015 г. система распознавания лиц компании YITU, а также биометрическая система VTM identity authentication были внедрены в 1500 банков Китая. |
|
NEC | Bio-IDiom – система биометрической идентификации.Person Re-identification Technology – алгоритм, разработанный компанией для идентификации людей, частично скрытых от камеры. Алгоритм анализирует фигуру человека, а также его одежду, и сравнивает с уже сохраненными в базе изображениями.Мультимодальная технология слияния изображений – значительно улучшает четкость изображений за счет использования искусственного интеллекта (AI) для автоматического объединения видимых изображений, полученных стандартными камерами, с невидимыми изображениями, полученными специализированными устройствами, такими как тепловые или терагерцовые камеры.Simplified Visual Inspection – технология NEC, позволяющая на основе алгоритмов компьютерного зрения осуществлять автоматический мониторинг поверхностей на предмет дефектов на производстве. |
|
Alibaba | Открытая ИИ-платформа для умного города ET City Brain. Реализована в городе Ханчжоу. Благодаря включению дорожных камер в облачное решение ET City Brain увеличилось число ежедневных сообщений об авариях в Ханчжоу и уменьшилось время реагирования. Уровень точности идентификации инцидентов составил более 92%. Автономный транспорт – компания активно разрабатывает данное направление, планируя использовать беспилотные автомобили для доставки продукции. Тестирование беспилотных транспортных средств проводятся в городе Ханчжоу, средняя скорость движения составляет на данный момент 30-40 км/ч, грузоподъемность – до нескольких тонн. |
|
Baidu | PaddleSeg – библиотека семантического сегментирования изображений. PaddleDetection – высокопроизводительный инструментарий обнаружения объектов. Apollo – технологии ИИ, включая алгоритмы распознавания лиц, анализа поведения за рулем, биометрию, использующиеся в бортовых системах автомобилей. Сейчас Baidu бесплатно предоставляет производителям автомобилей лицензию на свою систему в обмен на пользовательские данные, использующиеся для совершенствования моделей. Впоследствии планируется на базе Apollo создавать полностью автономные транспортные средства. |
|
Deep Glint | Squatter Zhiyuan – система, включающая в себя алгоритмы глубокого обучения, разработанные и оптимизированные для сценариев видеонаблюдения. Умные камеры – камеры, соединенные с серверами обработки визуальной информации, используемые для автоматического мониторинга охраняемых объектов. Роботы-аватары – роботизированные системы с портативной камерой и экраном, применяющиеся для дистанционной коммуникации.Система распознавания лиц DeepGlint широко используется полицией Китая. Также совместно с Hyundai внедряется в автомобили для биометрического распознавания водителей и анализа моделей поведения в процессе вождения. |
Российские компании | |
|
Яндекс | Yandex Vision – сервис компьютерного зрения для работы с изображениями. Сервис Yandex Vision включает в себя технологии OCR (Optical Character Recognition), автоматическую модерацию контента и определение присутствия человека на изображении.Поиск по изображению – по многим оценкам, поиск Яндекса по картинке является лучшим в мире, обходя по качеству поиски Google, Bing и Baidu. |
|
VisionLabs | LUNA SDK – набор библиотек и нейронных сетей для анализа изображений и работы с биометрическими образцами, который позволяет специалистам по разработке ПО создавать приложения для различных устройств. LUNA PLATFORM – система управления биометрическими данными, которая может решать разнообразные задачи с помощью функции распознавания лиц – например, распознавание клиента банка, идентификация сотрудников офиса при входе в здание и т.д. |
|
NtechLab | FindFace Security – «коробочное» решение для организации видеонаблюдения с использованием распознавания лиц. В режиме реального времени определяет лица в видеопотоке, сверяет со списками мониторинга и отправляет уведомления при обнаружении совпадений. FindFace Security работает с обычными камерами и распознает лица в том числе в затрудненных условиях: при плохом освещении и наличии посторонних предметов в кадре, при различных поворотах головы и изменении внешности человека. Архитектура сервиса позволяет подключать практически неограниченное количество видеокамер и серверов. |
|
Vocord | VOCORD Traffic – многофункциональная интеллектуальная система контроля дорожного движения для распознавания автомобильных номеров и фотовидеофиксации более 15 видов нарушений ПДД. VOCORD Tahion – ПО для создания систем видеонаблюдения и видеоаналитики любого масштаба. VOCORD ParkingContol – интеллектуальная система для распознавания ГРЗ ТС и контроля транспорта на парковке или другом объекте с пропускным режимом. |
|
Mail.ru Group | Компьютерное зрение для Retail:
|
|
Tevian | Основное направление – распознавание лиц. Чаще всего лицензируется в форме SDK, иногда в виде веб-системы, реже – в виде кастомизированного решения на основе SDK. В 2019 появился модуль распознавания документов, есть модуль для оценки размера очередей. |
|
ABBYY | ABBYY FineReader Engine – многофункциональный инструментарий разработчика, который позволяет встраивать в приложения интеллектуальные технологии распознавания данных. Эти технологии позволяют распознавать печатный текст (OCR), рукопечатный текст (ICR), метки (OMR) и штрихкоды (OBR). ABBYY Mobile Capture – универсальный инструмент для разработчика, который позволяет встраивать в мобильные приложения и клиенты функции автоматического захвата изображений документов и распознавания текста. ABBYY FlexiCapture – универсальная платформа для интеллектуальной обработки информации.ABBYY FineReader Server – корпоративное серверное решение для распознавания, хранения и преобразования файлов в PDF и другие электронные редактируемые форматы. |
|
3DiVi | Nuitrack – ПО для трекинга тела и распознавания жестов. Face SDK – ПО для распознавания лиц. Seemetrix – видеоаналитика для рекламных дисплеев.Мультибиометрическая платформа НейроАМБИС, с элементами искусственного интеллекта. |
|
ГосНИИАС | Бортовые авиационные системы улучшенного и синтезированного видения на платформе интегрированной модульной авионики (ИМА); комплекс автоматизированного дешифрирования авиационных изображений местности; система обработки, комплексирования, и анализа видеоинформации, необходимой для навигации летательных аппаратов; технология распознавания лиц в сложных некооперативных условиях съемки. |
|
Cognitive Technologies | Компания представляет решения для управления автономным автотранспортом, сельхозтранспортом и железнодорожным транспортом. Также специалисты Cognitive разработали первый промышленный прототип 4D-радара с наилучшими техническими характеристиками. |
- 1Computer Vision Market Size, Share & Trends Analysis Report By Component (Hardware, Software), By Product Type (Smart Camera-based, PC-based), By Application, By Vertical, By Region, And Segment Forecasts, 2020 – 2027. Опубликовано: сентябрь 2020 г. grandviewresearch.com/industry-analysis/computer-vision-market
- 2
- 3Проект ILSVRC (ImageNet Large Scale Visual Recognition Challenge, Кампания по широкомасштабному распознаванию образов в ImageNet) различные программные продукты ежегодно соревнуются в классификации и распознавании объектов и сцен в базе данных ImageNet, ведётся c 2010 года.
- 4Открытая программная библиотека для машинного обучения, поддерживаемая Google. tensorflow.org
Похожие записи:
 Искусственный интеллект: технологии и применение
Искусственный интеллект: технологии и применение
 Объяснимый искусственный интеллект
Объяснимый искусственный интеллект
 Семантический анализ для автоматической обработки естественного языка
Семантический анализ для автоматической обработки естественного языка
 Обзор технологий создания Deepfake и методов его выявления
Обзор технологий создания Deepfake и методов его выявления
 Государственные программы США анализа медиаматериалов Агентства передовых исследований в сфере разведки (IARPA)
Государственные программы США анализа медиаматериалов Агентства передовых исследований в сфере разведки (IARPA)