Обзор технологий создания Deepfake и методов его выявления

Оглавление
ПРИМЕРЫ ДИПФЕЙК-ПРИЛОЖЕНИЙ И ИНСТРУМЕНТОВ
УГРОЗЫ, СВЯЗАННЫЕ С ПРИМЕНЕНИЕМ ТЕХНОЛОГИИ
МИРОВОЙ ОПЫТ БОРЬБЫ С DEEPFAKE В ЧАСТИ ТЕХНИЧЕСКИХ РЕШЕНИЙ
МИРОВОЙ ОПЫТ ПРАВОВОГО РЕГУЛИРОВАНИЯ DEEPFAKE-ТЕХНОЛОГИЙ
РЕКОМЕНДАЦИИ ПО БОРЬБЕ С ДИПФЕЙКАМИ В ЧАСТИ ТЕХНИЧЕСКИХ РЕШЕНИЙ
ОПИСАНИЕ ТЕХНОЛОГИИ
Deepfake (от англ. deep learning — «глубокое обучение» и fake — «фальшивый») — реалистичная манипуляция аудио-, фото- и видеоматериалами с помощью искусственного интеллекта для достижения максимального сходства с реальными изображениями и звуковыми дорожками.
В большинстве случаев в основе метода лежат генеративно-состязательные нейросети (GAN). При использовании данного метода работают две нейросети. Первая из них (генеративная, Generator, G) генерирует изображения, а вторая (дискриминативная, Discriminator, D) отвечает за поиск отличий между ними и настоящими образцами.
Используя набор переменных латентного пространства, генеративная сеть пытается «слепить» новый образец, смешав несколько исходных образцов. Дискриминативная сеть обучается различать подлинные и поддельные образцы, а результаты различения подаются на вход генеративной сети так, чтобы она смогла подобрать лучший набор латентных параметров, и дискриминативная сеть уже не смогла бы отличить подлинные образцы от поддельных. Таким образом, целью сети G является повысить процент ошибок сети D, а целью сети D является наоборот улучшение точности распознавания.
Дискриминативная сеть D, анализируя образцы из оригинальных данных и из подделанных генератором, достигает некоторой точности различения. Генератор при этом начинает со случайных комбинаций параметров латентного пространства, а после оценки полученных образцов сетью D, применяется метод обратного распространения ошибки, который позволяет улучшить качество генерации, подправив входной набор латентных параметров. Постепенно искусственные изображения на выходе генеративной сети становятся всё более качественными. Сеть D реализуется как свёрточная нейронная сеть, в то время как сеть G наоборот разворачивает изображение на базе скрытых параметров.
В процессе совместного конкурентного обучения, если система достаточно сбалансирована, достигается минимаксное состояние равновесия, в котором обе сети значительно улучшили своё качество, и теперь сгенерированные изображения могут быть использованы практически как настоящие.
Данная технология может применяться для синтеза человеческого изображения, объединяя несколько снимков, на которых человек запечатлён с разных ракурсов и с разным выражением лица, и создавая из них видеопоток. Анализируя фотографии, специальный алгоритм в несколько этапов обучается тому, как выглядит и может двигаться человек.
Алгоритм в обычном случае использует два видеоряда: первый – видеоряд с человеком, лицо которого будет использоваться для замены, второй – оригинальный видеоряд, в котором будет производится замена лица. Очевидно, что на качество результата влияет множество свойств исходных файлов и входных данных (в том числе разрешение и длительность видеофайлов, разнообразность мимики персонажей, относительная схожесть лиц, освещение в роликах и т. д.).
На первом шаге работы алгоритма происходит покадровое извлечение изображений из обоих видеорядов.
На втором этапе происходит детектирование контуров лица в изображениях, полученных из первого видеоряда. Затем, для оптимизации вычислительного ресурса, происходит удаление некорректных (неудачных) кадров. К ним относятся все те, которые не содержат четко различимого лица; оно также не должно быть закрыто предметом, волосами и пр. На этом этапе для оптимальной работы алгоритма необходимо участие человека.
На третьем этапе осуществляется детектирование контуров лица в изображениях, полученных из второго видеоряда. Главным отличием является то, что для «принимающей» сцены важно определить лица во всех кадрах, содержащих лицо, даже мутные. Иначе в этих кадрах не будет произведено замены. При этом есть опция, позволяющая человеку вручную указать контуры лица на кадрах, где лицо не было определено.
Четвертый этап – тренировка нейросетей на полученных выборках изображений. Для тренировки необходимо выбрать одну из моделей. Это наиболее времязатратная и ресурсоемкая часть, которая может длиться несколько суток или недель. Чем дольше длится тренировка, тем лучший результат будет получен; кроме того, на качество результата здесь напрямую влияет производительность используемого оборудования.
По результатам обучения на пятом этапе производится покадровое наложение сгенерированных лиц на изображения, полученные из исходной сцены. Возможно несколько режимов наложения, наиболее часто используется метод Пуассона.
На шестом, финальном этапе, происходит склейка полученных кадров (исходная сцена + наложенное сгенерированное лицо) в видео с той же частотой кадров и звуком, что и в оригинале.
Для каждого из этапов алгоритма требуется совершенно различное количество времени от человека и машины. ПО, покадрово извлекающее изображения из видео, работает несколько минут, однако для проверки результатов человеку могут потребоваться часы. ПО отмечает все лица в каждом изображении и имеет довольно много ложных срабатываний. Для получения хороших результатов человеку нужно пройти по всем результатам, удаляя ненужные лица и все объекты, распознанные как лица.
В свою очередь, обучение нейросети легко настроить, и оно практически не требует человеческого участия. Однако для получения хороших результатов могут потребоваться дни или даже недели компьютерного времени.
Итоговый шаг, преобразование, проходит быстро и для человека, и для компьютера. Получив подходящим образом обученную модель, можно генерировать дипфейк-видео меньше, чем за минуту.
Кроме визуального синтезирования, генеративно-состязательные нейросети умеют работать с голосом. Соответствующие наборы методик называют технологией клонирования голоса (англ. voice changing, voice cloning).
Языковые модели позволяют компьютерам создавать случайные предложения приблизительно той же длины и грамматической структуры, что и заданные в качестве образца для обучения модели.
ПРИМЕРЫ ДИПФЕЙК-ПРИЛОЖЕНИЙ И ИНСТРУМЕНТОВ
DeepFaceLab
Бесплатное ПО DeepFaceLab является одним из наиболее популярных приложений для создания дипфейков и использует новые нейронные сети для замены лиц в видео. Программа размещена на GitHub и использует библиотеку TensorFlow, исходный код выложен пользователем iperov.
По словам разработчика, более 95% дипфейк-видео создаётся с помощью DeepFaceLab.
Библиотека стремительно развивается, сейчас существует несколько релизов:
— в виде пакета исполняемых (.bat) файлов для ОС Windows 7 и выше;
— DeepFaceLab для Linux;
— Google Colab – реализация, основанная на использовании удаленных вычислительных мощностей.
Минимальные системные требования для запуска проекта достаточно низкие — процессор с поддержкой SSE-инструкций, оперативная память объемом не менее 2 Гб + файл подкачки, OpenCL-совместимая видеокарта (NVIDIA, AMD, Intel HD Graphics). Рекомендуется процессор с поддержкой AVX-инструкций, оперативная память объемом не менее 8 Гб, видеокарта NVIDIA с объемом видеопамяти не менее 6 Гб.
Doublicat (Reface)
Разработчики сервиса Reflect в декабре 2019 года представили бесплатное приложение Doublicat для Android и iOS.
Программа позволяет реалистично менять лица на двух фотографиях.
Для создания изображения нужно сделать селфи (автопортрет, созданный с помощью камеры телефона), а затем выбрать какой-либо из знаменитых GIF-мемов и вставить туда своё лицо. В начале января приложение Doublicat получило широкое распространение среди пользователей сети Интернет.
Спустя полгода компания добавила в приложение замену лица на видео и переименовала Doublicat в Reface. С новой функцией популярность сервиса выросла, cейчас у Reface официально насчитывается 20 млн установок, их количество продолжает расти. Насколько быстро, компания не уточняет. Её представитель добавила, что контентом, созданным в приложении, делятся 65% пользователей.
Zao
Бесплатное китайское дипфейк-приложение Zao для Android и iOS может заменить лицо известного героя или актёра на лицо пользователя в любом отрывке популярного фильма, сериала, шоу или клипа, и при этом не понадобится вдаваться в тонкости и нюансы монтажа и обработки видео.
Zao позволяет менять голоса знаменитостей и накладывать своё лицо на тело актёра в сцене. Приложение предоставляет выбор из множества видеоклипов. В большинстве случаев результат выглядят не идеальным, но забавным. Его слабая сторона — алгоритм работает с предобученными данными. Пользователь не может загрузить свой контент, он загружает туда лишь изображение, которое переносится в заданный разработчиками набор видео.
Многие пользователи сочли, что приложение может оказаться небезопасным, поскольку в политике конфиденциальности указано, что компания-разработчик Momo вправе применять сгенерированные видеоролики в собственных целях (т.е. ей принадлежит весь созданный программой контент).
FakeApp
Приложение FakeApp — это десктопное приложение, которое позволяет легко создавать фотореалистичные видеоролики, в которых оригинальные лица заменены на лица других людей. Несмотря на блокировку оригинального сайта приложения и упоминаний и обсуждений его использования, в сети Интернет сохранились сайты-зеркала, а на Reddit есть раздел со ссылками на скачивание FakeApp со страниц файловых хостингов Google Drive и анонимного Mega, а также с инструкциями по его применению.
Качество полученного ролика зависит от того как хорошо обучилась программа. Чем больше сходство между людьми и чем больше у пользователя фотографий для обучения, тем более незаметной будет подмена.
Neural Voice Puppetry
В декабре 2019 года специалисты из Мюнхенского технического университета и Института информатики Общества Макса Планка опубликовали научную работу, посвященную системе Neural Voice Puppetry.
Для генерации видеозаписи ей нужен аудиофайл с голосом человека и его фотография. Процесс состоит из трех этапов. Сперва рекуррентная нейросеть анализирует речь на записи и строит модель, отражающую особенности произношения спикера. Эта модель направляется в обобщающую нейронную сеть, которая рассчитывает коэффициенты для построения трехмерной модели лица. На следующем этапе рендер-модуль генерирует финальную запись.
Разработчики заявляют, что Neural Voice Puppetry воспроизводит ролики высокого качества, но проблемы, связанные с синхронизацией звука, на данный момент в системе не решены.
Avatarify
Avatarify Work – бесплатный фильтр с использованием технологии Deepfake, который позволяет пользователям анимировать неподвижное изображение лица в режиме реального времени во время звонков в Skype, Zoom и других сервисах видеоконференций.
Этот фильтр отслеживает точки на лице пользователя (через веб-камеру) и фиксирует уникальную мимику, возникающую во время речи. Затем Avatarify накладывает ее на фотографию другого человека.
Затем анимированный аватар интегрируется в Zoom, Skype или любую другую платформу для видеозвонков. Для выбора аватара нужно иметь детальную фотографию его лица.
Единственным ограничением этого фильтра является то, что он не может воспроизводить голос в реальном времени. Голос пользователя будет звучать через «маску» аватара.
На данный момент для работы Avatarify требуется компьютер с графическим процессором, чтобы запускать программное обеспечение со скоростью 30 кадров в секунду. Создатели сервиса в настоящее время работают над оптимизацией программного обеспечения для других компьютеров и возможным использованием облачных хранилищ.
По словам разработчиков, для полноценного использования Avatarify нужна видеокарта с поддержкой CUDA (NVIDIA). В противном случае фильтр переключится на центральный процессор и будет работать очень медленно.
MachineTube
Пользователь Reddit под ником sinofis создал сайт MachineTube, позволяющий подменять лицо на видео или в изображениях. Разработчик использовал в качестве алгоритмов для распознавания и переноса лиц несколько проектов с открытым кодом, опубликованных на GitHub. Пока в сервисе доступно несколько натренированных нейросетевых моделей для знаменитостей, например, Дональда Трампа и Спока из сериала «Звездный путь». Пользователю не нужно устанавливать на компьютер специальную программу, но за счет использования браузерной библиотеки для машинного обучения сервис проводит вычисления с помощью вычислительных мощностей компьютера пользователя.
Пользователю необходимо выбрать имеющийся на сайте ролик или фотографию или загрузить свой, а затем выбрать параметры переноса. После этого сервис загружает на компьютер пользователя все необходимые ему данные и проводит обработку. Разработчик отмечает, что на создание десятисекундного ролика в среднем уходит около десяти минут. Пока десять секунд — это максимальная длина ролика, а максимальное разрешение составляет 480p (пикселей по вертикали). В будущем автор планирует оптимизировать алгоритмы и ослабить эти ограничения, а также загружать новые натренированные модели для переноса лиц.
Neural Rendering
Инженеры из Университетов Стэнфорда, Макса Планка и Принстона создали на основе алгоритма Deepfake нейросеть, которая позволяет редактировать речь говорящего на видео. Алгоритм, разработанный учеными, получил название Neural Rendering. Ему требуется около 40 минут, чтобы изучить мимику говорящего на видео и сопоставить форму его лица с каждым фонетическим слогом.
После этого нейросеть составляет 3D-модель лица говорящего и позволяет редактировать то, что он говорит, изменяя при этом мимику спикера.
Код нейросети не опубликован учеными по этическим соображениям.
VeraVoice
В конце октября 2019 года было объявлено о запуске сервиса Vera Voice, который позволяет синтезировать голоса знаменитостей на русском языке. Это совместный продукт компании Screenlife Technologies Тимура Бекмамбетова и разработчика HR-сервиса «Робот Вера» Stafory.
В основе Vera Voice лежит нейросеть, способная учиться копировать речь людей с оригинальных записей. Разработка будет использоваться в интерактивных мобильных приложениях по мотивам фильмов и сериалов, в которых пользователи смогут «разговаривать» с персонажами.
Для синтеза голоса достаточно нескольких часов аудиоданных, озвученных обладателем голоса, и оцифрованного текста, который он зачитывает. Аудиопоток и текст выгружаются в несколько нейронных сетей одновременно, одна генерирует спектрограмму звука (его визуальное изображение), а вторая — непосредственно звук, рассказал он.
Screenlife Technologies и Stafory планируют заключать договоры с обладателями голоса.
В августе 2020 года Vera Voice объявил о запуске технологии в США. В приложения клонирования голоса Parodist теперь есть возможность создавать контент на английском языке. Пока доступны голоса 32 знаменитых личностей, в том числе Дональда Трампа, Джо Байдена, Уилла Смита и Билли Айлиш.
Также появилась возможность свободного синтеза речи. Таким образом, пользователи Parodist могут не только воспользоваться готовыми шаблонами, но и создавать собственный контент.
Для этого нужно набрать сообщение в разделе «Свой текст» на русском или английском языках. Затем нейросеть Parodist осуществляет перевод текста в речь. Поддерживается создание сообщений размером до 150 знаков.
Разработка отмечает, что для свободного синтеза доступны не все герои Parodist, так как подобные действия ограничены законами разных стран.
На русском языке текст можно перевести в речь основателя студии Кубик в кубе Руслана Габидуллина, а на английском — в речь персонажа Гомера Симпсона.
Разработчики также добавили возможность получить доступ к шаблонам из платной версии за просмотр рекламы.
GPT-3
Исследователи из OpenAI в мае 2020 года представили GPT-3 — алгоритм, который может выполнять разные задания по написанию текста на основе всего нескольких примеров. В новой версии используется та же архитектура, что и в предыдущем алгоритме GPT-2 (основной задачей этого алгоритма было предсказание следующего слова в тексте), однако разработчики увеличили количество используемых в модели параметров до 175 миллиардов, обучив модель на 570 гигабайтах текста. В итоге GPT-3 может отвечать на вопросы по прочитанному тексту, писать стихи, разгадывать анаграммы, решать простые арифметические примеры и переводить на несколько языков (семь процентов всего датасета — тексты на иностранных языках) — для этого ей немного от 10 до 100 примеров того, как именно это делать.
Подробное описание работы алгоритма исследователи выложили на arXiv.org, однако в препринте они выразили беспокойство по поводу того, что разработанная ими модель может быть использована во вред — поэтому ее они пока что не предоставили. На странице разработчиков на GitHub можно найти кусок датасета и примеры заданий, которые использовались в работе.
Лиам Порр, студент, изучающий информатику в Калифорнийском университете в Беркли, в июле 2020 года создал блог на Substack под псевдонимом Адолос. Поскольку OpenAI в настоящее время сделал GPT-3 доступным для ограниченной аудитории разработчиков, то Порр попросил доступ к GPT-3 у профессора, уже использовавшего технологию.
Порр давал заголовок и вступление к посту, а GPT-3 создавал статью, затем выбирал лучшие из нескольких получаемых вариантов, выдаваемых моделью, и копировал их в свой блог с минимальным редактированием.
Первый пост занял первое место в Hacker News, набрав почти 200 голосов и более 70 комментариев. За одну неделю блог набрал 26 000 просмотров и приобрел 60 подписчиков. По словам Порра, очень немногие люди указали, что блог мог быть написан AI.
УГРОЗЫ, СВЯЗАННЫЕ С ПРИМЕНЕНИЕМ ТЕХНОЛОГИИ
Дискредитация личности
С распространением дипфейков появились случаи «дискредитации» публичных личностей, чьих изображений много в открытом доступе.
В качестве примера одного из известнейших дипфейков можно привести опубликованное в 2018 году фальшивое видео с экс-президентом США Бараком Обамой, где он якобы оскорбляет нынешнего главу американского государства. Видеоролик был сделан при помощи программ FakeApp и Adobe After Effects.
В середине 2019 года в Сети появилось сфабрикованное видео с Марком Цукербергом, который будто бы откровенно обрисовал текущее положение дел с персональными данными людей.
В том же году в интернете опубликовали дипфейк-видео со спикером Палаты представителей Конгресса США Нэнси Пелоси. Автор ролика с помощью технологий искусственного интеллекта изменил речь Пелоси так, что она плохо выговаривала слова, и пользователи, посмотревшие видео, посчитали, что политик находится в состоянии алкогольного опьянения. Всё это переросло в большой скандал, и лишь спустя некоторое время было доказано, что речь Пелоси была сгенерирована компьютером.
В мае 2018 года в сети появился ролик, в котором президент США Дональд Трамп обращается к жителям Бельгии, призывая их отказаться признать Парижские соглашения по климатическому урегулированию. Видео вызвало волну возмущения в комментариях в адрес американского президента. Однако позже выяснилось, что Трамп ничего такого не говорил, а само видео было заказано бельгийской социалистической партией, чтобы привлечь внимание к проблеме изменения климата.
Искажение фактов, фейковые новости
Насколько известно экспертам, пока написание фейковых новостей с помощью ИИ использовалось только в исследовательских целях. Первым известным инструментом для создания фейковых новостей стала программа
GPT-2, которую в феврале 2019 года представила OpenAI, некоммерческая исследовательская организация из Сан-Франциско. GPT-2 способна придумать не только новости, но также рассказы и диалоги, анализируя текст на 8 млн веб-страниц. В августе 2019 года 72% из 500 опрошенных человек приняли написанную GPT-2 новость за настоящую. Для сравнения: настоящую новость назвали правдоподобной 83% респондентов.
Учитывая возможные риски, OpenAI пока предоставила специалистам доступ лишь к ограниченной версии GPT-2, чтобы они разработали способ находить искусственно сгенерированные тексты.
В июне 2019 года специалисты Вашингтонского университета и Института искусственного интеллекта имени Аллена представили программу Grover, способную писать и определять фейковые новости. В августе 2019 года израильская AI21 Labs разместила на своем сайте инструмент для генерирования текстов HAIM, открытый для пользователей. Чтобы создать статью, ИИ необходимо иметь начало и конец истории, должна быть задана длина текста и тема.
AI21 Labs считает опасения по поводу технологии преувеличенными. По словам ее сооснователя Йоава Шохама, использование ИИ для пропаганды по-прежнему ограничено, поскольку он недостаточно хорошо анализирует политический контекст, чтобы зацепить целевую аудиторию.
Своевременный и хорошо реализованный дипфейк может пошатнуть всю политическую систему страны или даже мира (в случае, например, публикации речи главы государства с призывом к насилию или началу военных действий).
Deepfake как угроза для информационной безопасности бизнеса
Целевой фишинг (англ. spearphishing) направлен на то, чтобы обмануть конкретных сотрудников определённой компании и заставить их выполнить вручную какую-нибудь операцию.
Такие действия, как правило, труднее обнаружить технически (с точки зрения средств защиты информации), так как электронное письмо не содержит никаких подозрительных ссылок или вложений и обычно используется в сочетании с атакой Business E-mail Compromise (BEC), когда хакеры получают контроль над корпоративной учётной записью электронной почты и могут отправлять письма с легитимных адресов.
По данным ФБР, за последние три года атаки типа BEC обошлись компаниям по всему миру более чем в 26 млрд долларов США. Дипфейки увеличивают количество возможных вариантов проведения подобных атак.
Например, сотрудник компании получает электронное письмо от генерального директора с просьбой принять некоторые финансовые меры, затем ему приходит текстовое послание с мобильного номера того же топ-менеджера, а потом — и аудиосообщение, где голос генерального директора называет работника по имени и ссылается на предыдущие разговоры с ним. Скорее всего, сотрудник не задумается о том, дипфейк это или нет.
В качестве примера такой атаки можно привести инцидент, который произошёл в августе 2019 года в одной компании, работающей в сфере энергетики. Было установлено, что киберпреступник использовал технологию создания дипфейков для осуществления мошеннических действий на сумму в
220 000 евро. Злоумышленник вышел на связь с финансовым отделом как управляющий из Германии. Он смоделированным голосом попросил срочно перевести деньги на счёт в Венгрии, и у бизнес-партнеров не было ни единого повода не верить звонящему.
МИРОВОЙ ОПЫТ БОРЬБЫ С DEEPFAKE В ЧАСТИ ТЕХНИЧЕСКИХ РЕШЕНИЙ
SemaFor
23 августа 2019 года DARPA (Управление перспективных исследовательских проектов Министерства обороны США) опубликовано предварительное уведомление о закупке ПАК Semantic Forensics (SemaFor) в федеральной системе закупок США.
Программа экспертизы содержания (семантического анализа) мультимедийных материалов Semantic Forensics (SemaFor) должна быть разработана в целях автоматизации поиска фальсифицированных медийных материалов (текстов, аудио, изображений, видео) для защиты от крупномасштабных дезинформационных атак в режиме реального времени. По информации DARPA, ПАК «SemaFor» создается для идентификации фальсификата, его анализа и классификации, выявления специфических атрибутов, определения значимых характеристик (в том числе источника/создателя материалов, способов/алгоритмов создания и управления дезинформацией), выявления признаков целевого манипулирования медиаресурсом (с целью создания ложных новостей, социальной нестабильности, фальсификации результатов электронного голосования и т.п.).
Результатом конструктивного взаимодействия множества исполнителей Программы должен стать открытый продукт, обеспечивающий взаимодействие и интеграцию, способность легко добавлять, удалять, заменять и модифицировать программные и аппаратные компоненты для его быстрого обновления будущими разработчиками и пользователями. В связи с этим программное обеспечение, включая исходный код, документацию, аппаратные разработки и технические данные, сгенерированные системой, должны быть представлены в качестве программно-аппаратного комплекса с открытым исходным кодом.
Структура Программы SemaFor предполагает четыре уровня (технических области – ТО), которые создаются разными, но взаимодействующими исполнителями (Рисунок 1):
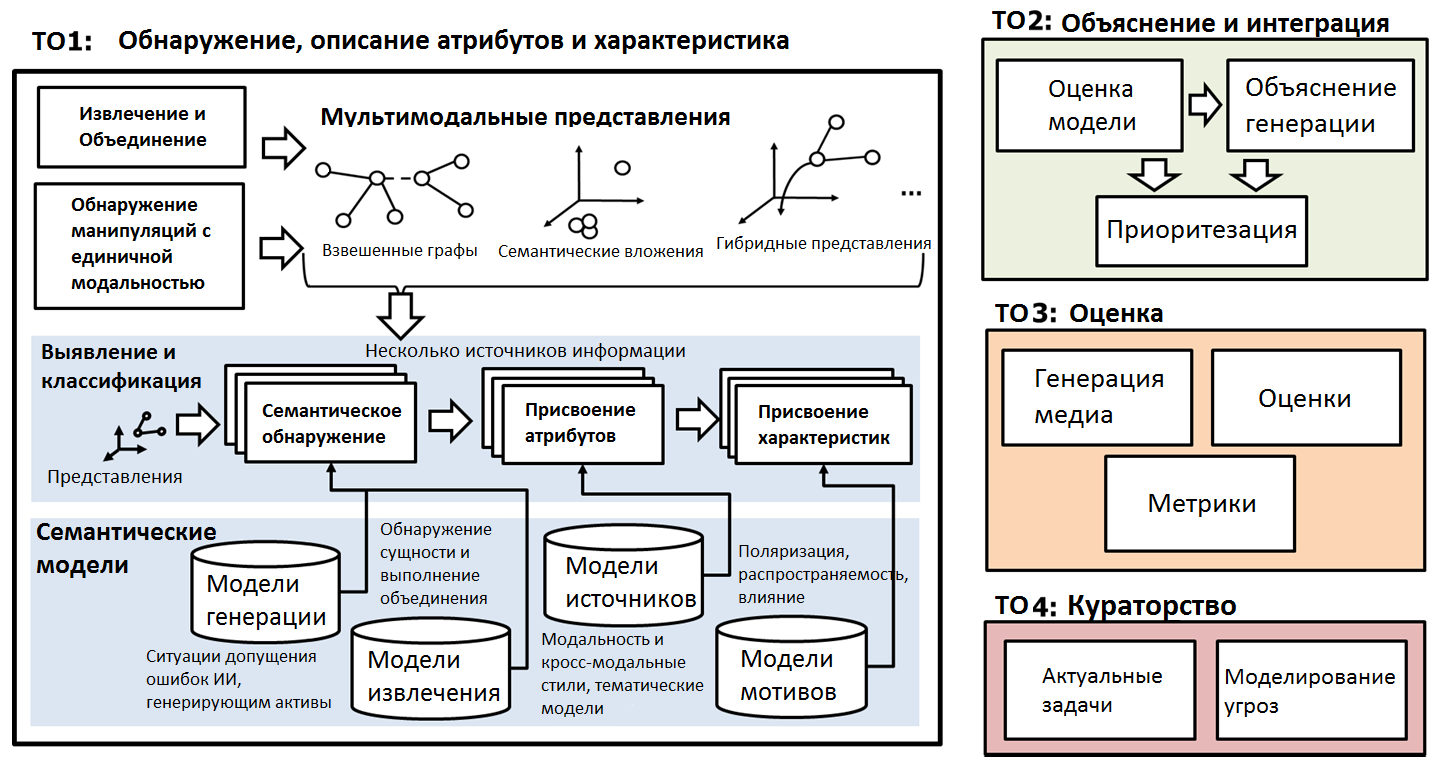 Рис. 1. Технические области Программы SemaFor
Рис. 1. Технические области Программы SemaFor
ТО1 (уровень исследования взаимосвязей между элементами системы обеспечивают специалисты Data Scientist). Идентификация фальсифицированных медиа, выявление их атрибутов и характеристик: алгоритмы обнаружения будут исследовать одиночные и мультимодальные материалы и причины семантических несоответствий, чтобы определить, был ли материал сфальсифицирован. Алгоритмы атрибуции будут анализировать содержание медиаресурсов по отношению к предполагаемым источникам, чтобы определить источник. Алгоритмы атрибуции также могут выявить организацию-фальсификатора или частное лицо. Алгоритмы характеристик будут проверять содержание медиаматериала и то, был ли он сфальсифицирован со злонамеренным умыслом, например, чтобы значительно изменить его тон, поляризацию, содержание или степень влияния в реальном мире.
ТО2 (уровень формирования системных решений обеспечивается специалистами по анализу данных). Проектирование и интеграция: интеграция результатов ТО1 (полученных от всех исполнителей), оценка результативности работы модели, формирование системных решений, приоритезация, разработка прототипа системы SemaFor; исполнитель ТО2 также отвечает за разработку алгоритмов автоматизированного сбора и контроля доказательств, представленных при выполнении ТО1 для анализа. Эта работа должна способствовать разработке алгоритмов ТО2, которые используют оценки и доказательства исполнителей ТО1 для приоритезации сфальсифицированных медиаматериалов, что важно для последующего анализа человеком. Такая расстановка приоритетов важна при масштабировании системы до реальных объемов современного медиа пространства. Прототип системы SemaFor должен обладать высокой масштабируемостью и быть предназначен для развертывания в облаке. Вероятные платформы включают GovCloud и C2S, но могут также включать операционные системы, используемые военными ведомствами (МО и СВР). Предложения по TO2 должны допускать применение SemaFor в МО и СВР на закрытой информации.
ТО3 (методический уровень обеспечивается аналитиками, использующими модель). Оценка: разработка критериев оценки, методики оценки, генерация/выборка целевых медиаматериалов, оценка объектов и их влияния, разработка дополнительных метрик. Целью оценки является понимание того, насколько SemaFor может удовлетворить потребности потенциальных партнеров (МО, СВР, коммерческие организации), а также для понимания прогресса развития программы в достижении ее научных целей. Оценки SemaFor будут характеризовать все элементы прототипа.
ТО4 (уровень бизнес-аналитики). Постановка и корректировка развития: курирующие процесс создания SemaFor исполнители ТО4 отбирают актуальные задачи для тестирования подходов и методов, разработанных в рамках ТО1 и ТО2; моделируют угрозы, в том числе перспективные. TO4 призвана ставить задачи для программы в качестве непредвзятого куратора, в целях направления развития Программы SemaFor с учетом актуальных тенденций. TO4 также разработает модели угроз, основанные на текущих и перспективных технологиях, чтобы гарантировать актуальность защиты SemaFor в обозримом будущем.
Программа SemaFor будет направлена не только на обнаружение семантических несоответствий, но также должна определять манипуляции с медиа, созданные человеком, которые могут казаться семантически согласованными, но передавать ложную информацию.
Хакатоны длительностью в одну неделю предлагается проводить на каждом значимом этапе программы.
Таблица 1. Возможности обнаружения, установления подлинности, категоризации сгенерированных медиа
| Функции | Текущие технологии | SemaFor | |
| Обнаружение | Автоматическое обнаружение семантических несоответствий и манипуляций с медиаконтентом | Ограничено | Да |
| Обнаружение манипуляций с использованием различных методов | Ограничено | Да | |
| Устойчивость ко многим алгоритмам манипуляции | Низкая | Высокая | |
| Навыки злоумышленника для обхода алгоритмов обнаружения | Средние | Высокие | |
| Установление подлинности | Автоматическое подтверждение источника или авторства | Ограничено | Да |
| Автоматическое определение уникальных характеристик источника | Нет | Да | |
| Объяснение несоответствий стилю автора | Нет | Да | |
| Категоризация и обоснование | Автоматическое определение намерений и влияния выделенной манипуляции | Нет | Да |
| Предоставление доказательств и объяснений намерений манипуляции | Нет | Да | |
| Обоснованная приоритезация сгенерированных / измененных медиа для обзора | Нет | Да |
Контракт на сумму 11 920 160 долларов США с фиксированной оплатой в июне 2020 года получила корпорация PAR Government Systems Corp. (Нью-Йорк). Работы будут проводиться в Риме, штат Нью-Йорк, с ожидаемой датой завершения в июне 2024 года. Финансирование исследований, разработок, испытаний и оценок на 2020 финансовый год в размере 1 500 000 долларов США будет выделено на момент присуждения контракта.
Deepfake Detection Challenge
В июне 2020 года компании Facebook и Microsoft подвели итоги конкурса для разработчиков Deepfake Detection Challenge.
Целью программы было объявлено создание решений, которые помогут индустрии «определять и предотвращать» распространение видео, созданных с помощью искусственного интеллекта для введения пользователей в заблуждение.
Лучшим участникам удалось добиться точности распознавания свыше 82 процентов на стандартном тестовом датасете (упрощ. коллекция логических записей) и чуть больше 65 процентов — на усложнённом датасете: в нем использовались отвлекающие компоненты (например, фильтры или надписи).
Всего в конкурсе приняли участие 2114 разработчиков, которые создали более 35 тысяч моделей.
Оценка эффективности алгоритмов проводилась двумя способами: в первом использовался заранее предоставленный разработчикам тестовый датасет, а во втором — закрытый и усложненный (в нём использовались видео с бегущими строками, фильтрами и актёрами, которые частично прикрывали лицо).
Согласно турнирной таблице на Kaggle, при оценке работы с помощью стандартного тестового датасета победил пользователь под ником Good At Curve Fitting: точность при определении дипфейков с помощью его алгоритма составила 82,56 процента.
При использовании для проверки закрытого датасета победил белорусский разработчик Селим Сефербеков из компании Mapbox: его алгоритм смог определить дипфейки с точностью 65,18 процента (при стандартной проверке он также занял четвертое место).
Согласно странице проекта на Kaggle, разработчики, занявшие первые пять мест в двух турнирных таблицах, получат на всех миллион долларов на дальнейшие разработки. Также организаторы выложили в открытый доступ датасет, который использовался разработчиками для обучения моделей: в нем около 470 гигабайтов видео.
Датасет от Google и Jigsaw
Google и Jigsaw (бывшая Google Ideas, обе компании принадлежат холдингу Alphabet) решили помочь в совершенствовании алгоритмов для распознавания дипфейков, дополнив уже существующий проект FaceForensics++, в рамках которого европейские разработчики создали датасет, а также автоматизированный бенчмарк, состоящий из нескольких алгоритмов для подмены лиц и определяющий их эффективность с помощью различных методов.
Новый датасет Deep Fake Detection Dataset основан на 363 роликах, которые разработчики сняли специально для проекта. На основе этих роликов они создали 3068 новых, в которых лица добровольцев заменены на другие: для создания роликов использовали публично доступные алгоритмы Deepfakes, Face2Face, FaceSwap и NeuralTextures. Разработчики отмечают, что в будущем будут дополнять датасет.
Однако вскоре среди разработчиков появились критические замечания в отношении FaceForensics++, поскольку при тестировании стали очевидны недостатки модели, разработанной на основании данных, которые были созданы специально для проекта. Например, модель не справлялась с определением фейковых видео, взятых напрямую с YouTube.
Assembler
Компания Jigsaw выпустила инструмент под названием Assembler, который должен помочь в проверке подлинности изображений. Как указано в описании платформы, Assembler объединяет несколько методов обнаружения манипуляций над изображением, включая детектор, который определяет дипфейки, созданные с помощью нейросети StyleGAN.
Assembler оснащён семью детекторами, каждый из которых разработан для определения конкретной манипуляции с изображением. Пять детекторов, которые были разработаны сотрудниками Калифорнийского университета в Беркли и Неаполитанского университета в Италии, могут определять различные цветовые несоответствия и аномалии, распознавать фотомонтаж и находить клонированные объекты на фото. Два других инструмента определяют дипфейки, созданные нейросетями. Эти инструменты — разработка самой Jigsaw.
Assembler, указывают в Массачусетском технологическом институте, — хороший шаг в борьбе с дипфейками, однако он не охватывает многие существующие методы изменения контента, в том числе те, которые используются для манипуляций с видео. Команда Jigsaw планирует добавлять и обновлять различные методы обнаружения манипуляций в Assembler по мере его развития.
Сейчас разработка Jigsaw проходит тестирование в фактчекинговых организациях и СМИ, например, Agence France-Presse, Animal Politico и Rappler. При этом, как указывает газета The New York Times, Assembler не планируют выпускать в доступ для широкого круга пользователей.
Content Authenticity Initiative
Компания Adobe выпустила white paper функции, которая позволит маркировать изображения, обработанные в фоторедакторе. Adobe обещает встроить новую функцию в Photoshop уже в этом году. В компании надеются, что технология позволит ограничить распространение обработанных изображений, которые выдаются за подлинные.
Система Content Authenticity Initiative (CAI) будет добавлять к изображениям теги, которые помогут отследить всю историю фото вплоть до того, какой камерой оно было снято. С помощью тегов, защищённых криптографией, будет фиксироваться и факт обработки изображения.
Adobe начала работать над новой функцией в 2019 году. Партнёрами компании по проекту стали Twitter и газета The New York Times. Twitter, по всей видимости, станет одной из первых платформ, которая будет тестировать технологию.
В Adobe рассчитывают, что функция поможет улучшить работу автоматизированных систем выявления фейковых фото, которые работают на некоторых социальных платформах. Например, новость может получить пометку с предупреждением о возможной дезинформации, если выяснится, что к ней прикреплено обработанное фото.
Чтобы функция работала, поддержку CAI должны обеспечить производители ПО и фотокамер, а также социальные платформы. Truepic, стартап, который создаёт ПО для проверки фотографий, планирует в этом году выпустить бета-версию программы, которая будет встраивать теги CAI в камеру смартфона Android. Google и Apple пока не проявили интереса к системе, указывает Wired.
В Adobe признают, что у новой функции есть слабые места. В частности, несмотря на то, что использование криптографии в CAI затрудняет вмешательство в теги, способы их взлома существуют. В официальном документе проекта говорится о том, что теги CAI можно удалить из файла и добавить поддельные. При этом лицо или организацию, добавившие поддельные теги, можно заблокировать, но это не поможет устранить ущерб, нанесенный подделкой.
Самая большая потенциальная слабость CAI заключается в том, что система будет, по всей вероятности, работать только с небольшой частью контента, заявил в комментарии Wired Ваэль Абд-Альмагид, профессор Южно-Калифорнийского университета.
Grover
Исследователи Школы компьютерных наук и инженерии имени
Пола Г. Аллена Университета Вашингтона и Института искусственного интеллекта имени Аллена разработали Grover – алгоритм, который, как они утверждают, смог отобрать 92% дипфейков в тестовом наборе, составленном из открытых данных Common Crawl Corpus. Команда объясняет свой успех копирайтинговым подходом, который, по их словам, помог разобраться с особенностями языка, созданного ИИ.
Giant Language Model Test Room
Команда ученых из Гарварда и MIT-IBM Watson AI Lab отдельно выпустила The Giant Language Model Test Room, веб-среду, которая пытается определить, был ли текст написан с помощью модели ИИ. Учитывая семантический контекст, она предсказывает, какие слова наиболее вероятно появятся в предложении, по сути, написав свой собственный текст. Если слова в проверяемом образце соответствуют 10, 100 или 1000 наиболее вероятных слов, индикатор становится зеленым, желтым или красным соответственно. Фактически она использует свой собственный прогнозируемый текст в качестве ориентира для выявления искусственно сгенерированного контента.
Resemblyzer
В начале 2020 года команда Resemble выпустила инструмент с открытым исходным кодом под названием Resemblyzer, который использует ИИ и машинное обучение для обнаружения аудио-дипфейков путем получения голосовых образцов высокого уровня и прогнозирования того, являются ли они реальными или смоделированными. Получив аудиофайл с речью, он создает математическое представление, суммирующее характеристики записанного голоса. Это позволяет разработчикам сравнить схожесть двух голосов или выяснить, кто говорит в данный момент. Отметим, что эта же компания в 2017 году создала инструмент для клонирования голосов из аудиоданных (по заявлению разработчиков, Resemble достаточно всего 5 минут данных)
МИРОВОЙ ОПЫТ ПРАВОВОГО РЕГУЛИРОВАНИЯ DEEPFAKE-ТЕХНОЛОГИЙ
В США были предприняты попытки регулирования дипфейков. В штате Калифорния был принят закон, который запрещает создавать и распространять дипфейки в пределах 60 дней до выборов. Однако такая мера вызвала у экспертов скепсис – закон будет трудно соблюдать, и куда быстрее будет воспользоваться старыми нормами об авторском праве, чем новым региональным механизмом.
Другая мера была принята на национальном уровне – в декабре 2019 года президент США Дональд Трамп подписал федеральный закон, который непосредственно относится к теме «подделок». В частности, закон предписывает правительству тщательно отслеживать «иностранный след» в дипфейках, а также уведомлять Конгресс о подобных действиях, направленных на вмешательство в выборные процессы.
Американский штат Вирджиния с 1 июля 2019 года официально расширил свой запрет на «порноместь», добавив в него «реалистичные фейковые видео и фото, включая сгенерированные на компьютере дипфейки».
Отметим, что сама по себе «порноместь» запрещена в этом регионе еще с 2014 года. Если пользователь сети опубликует «интимное фото или видео другого человека без его согласия с целью запугивания или принуждения», ему будет грозить до 12 месяцев тюрьмы и до $2500 штрафа. Теперь это наказание распространяется в том числе на фейковые фото или видео.
В 2019 году в штате Техас был принят закон, согласно которому дипфейки запретили создавать только в политических целях (закон вступил в силу 1 сентября 2019 года). В штате Нью-Йорк законодатели предложили запретить «воссоздавать цифровые образы людей» без их согласия — однако Ассоциация кинематографистов Америки раскритиковала эту идею, поскольку «она может помешать созданию исторических и биографических фильмов», а потому судьба законопроекта пока под вопросом.
Китайское правительство в ноябре 2019 года приняло закон, который запрещает публикацию фейк-ньюс, созданных с использованием искусственного интеллекта и виртуальной реальности.
Любые материалы с использованием ИИ или VR должны иметь специальную хорошо различимую пометку, несоблюдение правил может рассматриваться как уголовное преступление. Закон вступил в силу с 1 января 2020 года.
Важную роль в документе играют правила регулирования дипфейков. В Управлении по вопросам киберпространства считают, что эта технология может «поставить под угрозу национальную безопасность, подорвать социальную стабильность и нарушить общественный порядок».
В январе 2020 года стало известно, что Facebook будет удалять дипфейки и манипулятивные видео. Под запрет попадает контент, созданный с помощью искусственного интеллекта или машинного обучения, который может менять лица и голоса людей. Кроме того, видео удалят, если выяснится, что оно отредактировано неочевидным для среднего пользователя способом, из-за которого тот может подумать, что человек сказал слова, которых на самом деле он не говорил. Названные меры станут подготовкой соцсети к предстоящим выборам президента США осенью 2020 года. В компании подчеркнули, что не станут удалять контент, если он является пародией или сатирой. Проверкой контента займутся 50 независимых компаний.
В России порядок ограничения доступа к информации, распространяемой с нарушением закона определяется Федеральным законом от 27.07.2006 N 149-ФЗ (ред. от 03.04.2020) «Об информации, информационных технологиях и о защите информации» (статья 15.3), за распространение фейковых новостей предусмотрена административная ответственность (ст. 13.15 КоАП РФ — злоупотребление свободой массовой информации). Публичное распространение заведомо ложной информации об обстоятельствах, представляющих угрозу жизни и безопасности граждан, и публичное распространение заведомо ложной общественно значимой информации, повлекшее тяжкие последствия, наказываются согласно Уголовному кодексу Российской Федерации от 13.06.1996 N 63-ФЗ (ред. от 31.07.2020), ст. 207.1-2.
РЕКОМЕНДАЦИИ ПО БОРЬБЕ С ДИПФЕЙКАМИ В ЧАСТИ ТЕХНИЧЕСКИХ РЕШЕНИЙ
Для борьбы с дипфейками возможны два направления: защита аутентичности контента и распознавание искусственно созданных изображений/видео/аудио и текстов.
Некоторые развивающиеся технологии уже помогают создателям видеоконтента защищать его аутентичность. С помощью специального шифровального алгоритма в видеопоток с определенными интервалами встраиваются хеши; если видео будет изменено, хеши также изменятся. Создавать цифровые сигнатуры для видео также можно, используя ИИ и блокчейн. Это похоже на защиту документов водяными знаками; однако в случае с видео трудности заключаются в том, что хеши должны оставаться неизменными при сжатии видеопотока различными кодеками.
Еще один способ борьбы с дипфейками – использовать программу, вставляющую в видеоконтент специальные цифровые артефакты, маскирующие группы пикселей, по которым ориентируются программы для распознавания лиц. Этот прием замедляет работу дипфейк-алгоритмов, и в результате качество подделки будет более низким, что, в свою очередь, снизит вероятность успешного использования дипфейка.
Команда ученых из Бостонского университета создала алгоритм, позволяющий защитить публикуемые в интернете фотографии и видео от изменений с помощью дипфейк-технологий. О разработке сообщает «Популярная механика». Согласно алгоритму, на фото или видео накладывается невидимый фильтр, и когда злоумышленник пытается использовать нейронную сеть для манипуляций с этими медиафайлами, то изображения остаются неизменными, либо полностью искажаются. Всё дело в фильтре, который отображает пиксели особым образом, и изображение становится неузнаваемым и непригодным для изготовления дипфейков. Авторы алгоритма сделали общедоступными как описание технологии своей разработки, так и её код, а кроме того опубликовали видео, с демонстрацией работы фильтра.
Чтобы распознать дипфейк, учёные из Университета Олбани провели эксперимент, в котором выявили, что в среднем люди моргают 17 раз в минуту. Эта цифра увеличивается до 26 раз во время разговора, и падает до 4,5 раз во время чтения. Эти же учёные предложили свой метод распознавания фейковых видеороликов, объединив две нейронные сети, для того чтобы более эффективно распознавать ненастоящие лица. Как выяснилось, нейронные сети часто упускают спонтанные и непроизвольные физиологические действия. Например, дыхание во время речи, движение глаз или моргание. Однако известно, что вскоре после публикации данного исследования были созданы более совершенные алгоритмы, способные намного лучше имитировать естественные движения человека. Тем не менее, на дипфейк-видео все еще можно встретить «мерцание» по контурам лица человека, смену качества видео на отдельных кадрах или участках видео, а также размытие или искривление мелких или четких деталей, например, волос или зубов.
Хотя эти признаки могут помочь в обнаружении дипфейка в настоящий момент, но с совершенствованием технологии единственным вариантом для надежного обнаружения дипфейка скорее всего станут другие типы ИИ, обученные отличать подделки от реальных носителей.
Согласно материалам конференции IEEE по компьютерному зрению и распознаванию образов 2019 года, дипфейк-видео содержат внутрикадровые и временные несоответствия, поэтому предполагается, что при покадровой обработке видео низкоуровневые артефакты, создаваемые при манипуляциях с лицом, проявят себя именно как временные артефакты с несоответствиями между кадрами.
Группа ученых из Германии предложила метод машинного обучения, основанный на частотном анализе, направленный на распознавание дипфейк изображений лиц. Функционирование модели основано на работе двух основных блоков: блок извлечения признаков с использованием дискретного преобразования Фурье (ДПФ); обучающий блок, в котором классификатор использует новые преобразованные функции, чтобы определить, настоящее лицо или нет (Рисунок 2).
Входные изображения при этом преобразуются в оттенки серого перед дискретным преобразованием Фурье.
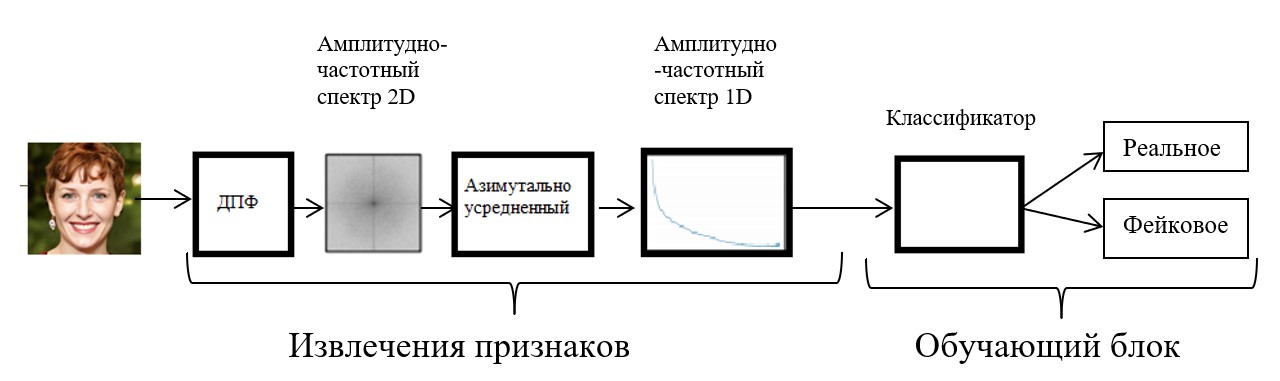
Рис. 2 Схема метода определения фейковых изображений
Для ликвидации угрозы информационной безопасности для бизнеса рекомендуется: использовать многофакторную аутентификацию сотрудников, электронную подпись для защиты сообщений электронной почты, отслеживать факты наличия программ для создания дипфейков на компьютерах пользователей, минимизировать число каналов коммуникаций компании, обеспечить согласованное распространение информации, ограничить фото- и видеоконтент с участием руководящих лиц предприятия, разработать план реагирования на дезинформацию (по аналогии с инцидентами безопасности), организовать централизованный мониторинг каналов и отчётность.
Похожие записи:
 WhatsApp внес изменения в свои Условия использования и Политику приватности
WhatsApp внес изменения в свои Условия использования и Политику приватности
 Отчет о мониторинге правоприменения регулирования информационного пространства в странах мира в 2020 году
Отчет о мониторинге правоприменения регулирования информационного пространства в странах мира в 2020 году
 Международный опыт регулирования возрастных ограничений в интернете
Международный опыт регулирования возрастных ограничений в интернете
 Республика Индия
Республика Индия
 Риски и угрозы, сопутствующие развитию индустрии киберспорта и гейминга
Риски и угрозы, сопутствующие развитию индустрии киберспорта и гейминга