Объяснимый искусственный интеллект

Объяснимый искусственный интеллект (Explainable AI, XAI) – модель, которая могла бы в перспективе объяснять механизмы, лежащие за алгоритмами машинного обучения.
Множество решений, применяющих алгоритмы ИИ, представляют собой подобие «черного ящика», — зачастую не только конечные пользователи, но и сами разработчики не могут точно определить, как именно модель машинного обучения пришла к тем или иным выводам в ходе обработки исходных данных.
Понимание алгоритмов работы искусственного интеллекта позволит разработчикам точно оценивать влияние входных признаков на выходной результат модели, выявлять необъективности и недостатки, связанные с работой модели, а также проводить тонкую настройку и оптимизацию ИИ.
Для пользователей объяснимость результата работы ИИ важна в части понимания причин выводов, сделанных моделью, а для экспертов – для объяснения тех выводов, которые на первый взгляд не имеют под собой оснований.
Потребность в объяснимом искусственном интеллекте со стороны общества подтверждается такими документами, как: статья 22 Общего регламента по защите данных (ЕС) дает человеку право требовать объяснения того, как автоматизированная система приняла решение, которое его затрагивает; Закон об ответственности за работу алгоритмов (США) прямо требует от компаний предоставить оценку рисков для конфиденциальности или безопасности личности, создаваемых автоматизированной системой принятия решений, а также рисков, которые способствуют принятию неточных, несправедливых, предвзятых или дискриминационных решений; Закон о равных возможностях получения кредитов (США) устанавливает возможность объяснения причин получения или отказа в кредите, что представляется затруднительным при использовании искусственного интеллекта на основе «черного ящика» и другие.
Проблемой объяснения работы искусственного интеллекта занимаются такие крупные образовательные учреждения, как Технологический университет Мичигана (США), Корнелльский Университет (США), Университет Карнеги Меллон (США), Университет Дьюк (США), Эдинбургский университет (Великобритания), Борнмутский университет (Великобритания), Лондонский университет (Великобритания), Норвежский университет естественных и технических наук. Группам ученых, занимающимся изучением и развитием данной проблематики, выделяются гранты от правительств и университетов.
Агентство перспективных оборонных исследовательских проектов (DARPA) Министерства обороны США, ответственное за разработку новых технологий, проводит программу Explainable AI (XAI). Одиннадцать команд XAI исследуют широкий спектр методов и подходов разработки объяснимых моделей и эффективных интерфейсов объяснения.
В национальных программах развития технологий таких стран, как Франция, Норвегия, Индия, Южная Корея и других также говорится о необходимости развития XAI как неотъемлемой части государственной политики.
Объяснимость модели может быть рассмотрена на всех этапах разработки искусственного интеллекта, как для изначально интерпретируемых моделей ИИ (линейная и логистическая регрессия, деревья решений и другие), так и для моделей на основе «черного ящика» (персептрон, сверточная и рекуррентная нейронные сети, сеть долгосрочной кратковременной памяти и другие).
Для моделей, сложно поддающимся интерпретации пользователями, наиболее популярными в научной среде апостериорными методами объяснений (объяснимость после моделирования) являются LIME, SHAP и LRP.
Компании IBM, Microsoft, Google и opensource-сообщество предоставляют пользователям наборы инструментов и программные пакеты для объяснимого искусственного интеллекта.
Развитие технологий XAI находится на раннем этапе — большинство методов все еще находится в стадии разработки, появляются новые комбинированные методы, в ходе экспериментов часть теорий подвергаются критике. Количество и уровень вовлеченных участников исследований свидетельствуют о важности рассматриваемой тематики.
Методы XAI могут быть использованы для прогнозирования рисков и угроз при распространении информации, но наибольший эффект от технологии может быть получен при развитии методов XAI, выявляющих различные виды разнородных неструктурированных медиаматериалов. Это необходимо учитывать при разработке концептуальной архитектуры информационных систем ведомства.
Аналитическая справка: Объяснимый искусственный интеллект
Содержание
Задачи, решаемые с помощью машинного обучения и искусственного интеллекта
Обоснование необходимости использования объяснимого искусственного интеллекта (XAI)
Апостериорные методы объяснений
Проблемы, связанные с развитием и использованием XAI
Термины и определения
|
Аддитивный |
получаемый при сложении. |
|
Аппроксимация функции |
нахождение такой функции (аппроксимирующей функции), которая была бы близка заданной. Такая задача возникает при наличии погрешности в исходных данных (в этом случае нецелесообразно проводить функцию точно через все точки) или при желании получить упрощенное математическое описание сложной или неизвестной зависимости. |
|
Блок линейной ректификации (Rectified linear unit, ReLU)’ |
функция активации, определяемая как положительная часть ее аргумента. |
|
Гомоскедастичность |
свойство, означающее постоянство условной дисперсии вектора или последовательности случайных величин. |
|
Гладкая функция |
функция, имеющая непрерывную производную на всем множестве определения. Часто под гладкими функциями подразумевают функции, имеющие непрерывные производные всех порядков. |
|
Глубокая декомпозиция Тейлора (Deep Taylor decomposition) |
практический метод для декомпозиции прогнозов больших глубоких нейронных сетей. Он работает, выполняя обратный проход по сети с использованием заранее определенного набора правил. В результате он производит разложение вывода нейронной сети на входные переменные. Может использоваться как инструмент визуализации или как часть более сложного метода анализа. Глубокая декомпозиция Тейлора используется, например, для объяснения современных нейронных сетей для компьютерного зрения. |
|
Градиент |
вектор, касающийся функции и указывающий в направлении наибольшего увеличения этой функции. Градиент равен нулю при локальном максимуме или минимуме, потому что нет единого направления увеличения. В математике градиент определяется как частная производная для каждой входной переменной функции. |
|
Граф |
основная модель описания пространства состояний в задачах поиска оптимального решения задач. |
|
Граф знаний |
собрание фактов, в котором объекты (узлы) соединены друг с другом типизированными связями. Информация, сохраняемая в графе, может быть различной: знания из многих областей; знания из какой-то конкретной области (к примеру, в Bio2RDF и UMLS содержатся знания из области биологии и медицины); знания, относящиеся к конкретной отрасли или предприятию. Графы знаний могут содержать вспомогательные фактические сведения об элементах, входящих в обучающую выборку, что позволяет ее расширить. |
|
Дисперсия некоторой случайной величины X |
мера того, насколько значения в распределении варьируются в среднем по отношению к среднему. Дисперсия рассчитывается как среднеквадратическая разница каждого значения в распределении от ожидаемого значения. Или ожидаемое квадратичное отличие от ожидаемого значения. |
|
Локальные объяснения |
набор методов, которые помогают понять индивидуальные прогнозы моделей машинного обучения. |
|
Локальные суррогатные модели |
интерпретируемые модели, такие как линейная регрессия или деревья решений, которые используются для объяснения индивидуальных предсказаний модели черного ящика. |
|
Метод главных компонент (principal component analysis, PCA) |
один из основных способов уменьшить размерность данных, потеряв наименьшее количество информации. Вычисление главных компонент может быть сведено к вычислению сингулярного разложения матрицы данных или к вычислению собственных векторов и собственных значений ковариационной матрицы исходных данных. |
|
Метод последовательных приближений (метод итераций) |
метод решения математических задач при помощи такой последовательности приближения, которая сходится к решению и строится рекуррентно (т. е. каждое новое приближение вычисляют, исходя из предыдущего; начальное приближение выбирается в достаточной степени произвольно). Применяется для приближённого нахождения корней алгебраических и трансцендентных уравнений, для доказательства существования решения и приближённого нахождения решений дифференциальных, интегральных и интегро-дифференциальных уравнений, для качественной характеристики решения и в ряде др. математических задач. Применяется для решения уравнений или систем уравнений в случаях, когда искомые параметры не могут быть выражены в явном виде. |
|
Мультиколлинеарность |
тесная корреляционная взаимосвязь между отбираемыми для анализа факторами, совместно воздействующими на общий результат, которая затрудняет оценку и анализ общего результата. |
|
Мультипликативный |
получаемый при умножении. |
|
Предиктор |
прогностический параметр, фактор. |
|
Разреженные линейные модели |
линейные модели, в которых в результате обучения часть компонент может иметь нулевой вес. |
|
Случайный лес (random forest) |
модель, состоящая из множества деревьев решений. Вместо того, чтобы просто усреднять прогнозы разных деревьев (такая концепция называется просто «лес»), эта модель использует две ключевые концепции, которые и делают этот лес случайным: случайная выборка образцов из набора данных при построении деревьев; при разделении узлов выбираются случайные наборы параметров. |
|
Стохастический градиентный спуск |
оптимизационный алгоритм, отличающийся от обычного градиентного спуска тем, что градиент оптимизируемой функции считается на каждом шаге не как сумма градиентов от каждого элемента выборки, а как градиент от одного, случайно выбранного элемента. |
|
Функция активации (активационная функция, функция возбуждения) |
функция, вычисляющая выходной сигнал искусственного нейрона. В качестве аргумента принимает сигнал, получаемый на выходе входного сумматора. |
|
Эвристический алгоритм |
алгоритм решения задачи, включающий практический метод, не являющийся гарантированно точным или оптимальным, но достаточный для решения поставленной задачи. Позволяет ускорить решение задачи в тех случаях, когда точное решение не может быть найдено. |
Задачи, решаемые с помощью машинного обучения и искусственного интеллекта
Все задачи, решаемые с помощью машинного обучения (machine learning, ML) и искусственного интеллекта (artificial intelligence, AI), относятся к одной из следующих категорий:
1) Задача регрессии – прогноз на основе выборки объектов с различными признаками. На выходе должно получиться вещественное число.
2) Задача классификации – получение категориального ответа на основе набора признаков. Имеет конечное количество ответов (как правило, в формате «да» или «нет»).
3) Задача кластеризации – распределение данных на группы.
4) Задача уменьшения размерности – сведение большого числа признаков к меньшему (обычно 2–3) для удобства их последующей визуализации.
5) Задача выявления аномалий – выявление отклонений от стандартных случаев. Схожа с задачей классификации, но более сложна в обучении.
Модели искусственного интеллекта/машинного обучения — это математические алгоритмы, которые с помощью вклада человека (эксперта) «обучаются» на наборах данных воспроизводить решение, которое эксперт примет при анализе такого же набора данных. Обучившись воспроизводить решение эксперта, модель в дальнейшем функционирует самостоятельно, позволяя таким образом автоматизировать решение задач. В идеале модель должна также обосновывать своё решение, чтобы помочь интерпретировать процесс принятия решения.
Искусственные нейронные сети
Искусственная нейронная сеть (ИНС) — математическая модель, а также ее программное или аппаратное воплощение, построенная по принципу организации и функционирования биологических нейронных сетей. В общем случае ИНС может состоять из нескольких слоев простейших процессоров (нейронов), каждый из которых осуществляет некоторое математическое преобразование (вычисляет результат математической функции) над входными данными и передает полученный результат на следующий слой или на выход сети.
ИНС решают проблемы распознавания образов, выполнения прогнозов, оптимизации, ассоциативной памяти и управления.
Нейроны входного слоя получают данные извне (например, от сенсоров системы распознавания лиц) и после их обработки передают сигналы через синапсы нейронам следующего слоя. Нейроны второго слоя (его называют скрытым, потому что он напрямую не связан ни со входом, ни с выходом ИНС) обрабатывают полученные сигналы и передают их нейронам выходного слоя. Поскольку речь идет об имитации нейронов, то каждый процессор входного уровня связан с несколькими процессорами скрытого уровня, каждый из которых, в свою очередь, связан с несколькими процессорами уровня выходного. Такая простейшая ИНС способна к обучению и может находить простые взаимосвязи в данных. Более сложная модель ИНС будет иметь несколько скрытых слоев нейронов, перемежаемых слоями, которые выполняют сложные логические преобразования. Каждый последующий слой сети ищет взаимосвязи в предыдущем. Такие ИНС способны к глубокому (глубинному) обучению (рис. 1).
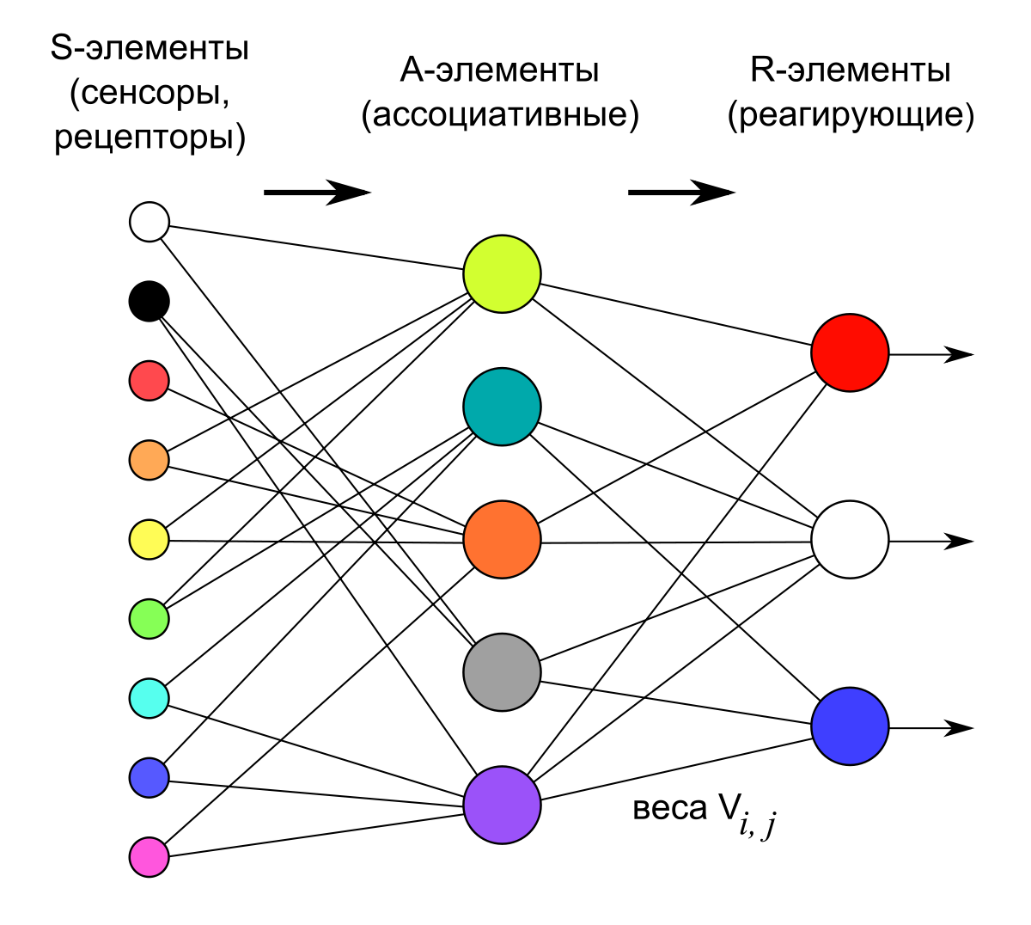
Рис. 1. Модель нейронной сети
Персептрон – это простейшая модель нейросети, состоящая из одного нейрона. Нейрон может иметь произвольное количество входов, а один из них обычно тождественно равен 1. Этот единичный вход называют смещением. Каждый вход имеет свой собственный вес. При поступлении сигнала в нейрон вычисляется взвешенная сумма сигналов, затем к сигналу применяется функция активации и сигнал передается на выход (рис. 1). Такая простая сеть способна решать ряд задач: выполнять простейший прогноз, регрессию данных и т.п., а также моделировать поведение несложных функций. Главное для эффективности работы этой сети – линейная разделимость данных.
Многослойный персептрон — обобщение однослойного персептрона. Слоем называют объединение нейронов; на схемах, как правило, слои изображаются в виде одного вертикального ряда (в некоторых случаях схему могут поворачивать, и тогда ряд будет горизонтальным). Многослойный персептрон состоит из некоторого множества входных узлов (рис. 2), нескольких скрытых слоев вычислительных нейронов и выходного слоя.
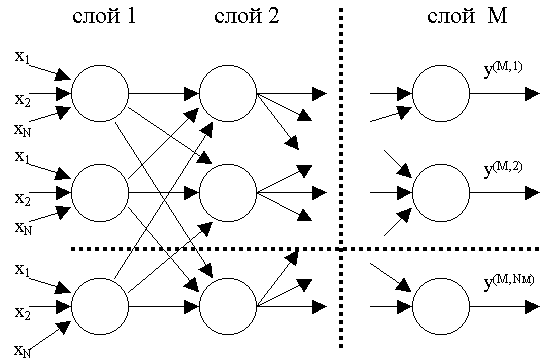
Рис. 2. Многослойный персептрон
Отличительные признаки многослойного персептрона:
- Все нейроны обладают нелинейной функцией активации, которая является дифференцируемой.
- Сеть достигает высокой степени связности при помощи синаптических соединений.
- Сеть имеет один или несколько скрытых слоев.
Такие многослойные сети еще называют глубокими. Эта сеть нужна для решения задач, с которыми не может справиться персептрон — в частности, линейно неразделимых задач. Многослойный персептрон является единственной универсальной нейронной сетью, универсальным аппроксиматором, способным решить любую задачу машинного обучения. Именно поэтому, если исследователь не уверен, нейросеть какого вида подходит для решения стоящей перед ним задачи, он выбирает сначала многослойный персептрон.
Сверточная нейронная сеть (Convolutional neural network, CNN) – сеть, которая обрабатывает передаваемые данные не целиком, а фрагментами. Данные последовательно обрабатываются, а после передаются дальше по слоям. Сверточные нейронные сети состоят из нескольких типов слоев: сверточный слой, субдискретизирующий слой, слой полносвязной сети (когда каждый нейрон одного слоя связан с каждым нейроном следующего). Слои свертки и подвыборки (субдискретизации) чередуются и их набор может повторяться несколько раз. К конечным слоям часто добавляют персептроны, которые служат для последующей обработки данных (рис. 3).
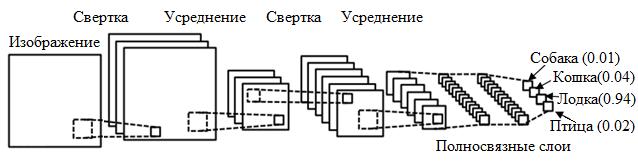
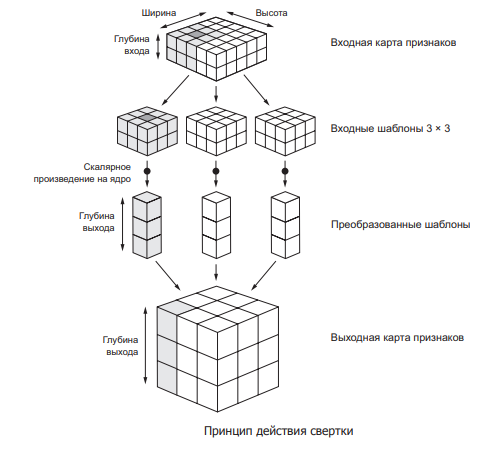
Рис. 3. Сверточная нейронная сеть
Суть операции свертки в том, что каждый фрагмент изображения умножается на матрицу (ядро) свёртки поэлементно, а результат суммируется и записывается в аналогичную позицию выходного изображения для перехода от конкретных особенностей изображения к более абстрактным деталям, и далее – к ещё более абстрактным, вплоть до выделения понятий высокого уровня (присутствует ли что-либо искомое на изображении).
Сверточные нейронные сети решают следующие задачи: классификация, детекция (поиск и определение объектов) и сегментирование.
Описанные сети относятся к сетям прямого распространения. Наряду с ними существуют нейронные сети, архитектуры которых имеют в своем составе связи, по которым сигнал распространяется в обратную сторону.
Рекуррентная нейронная сеть (Recurrent neural network, RNN) – сеть, соединения между нейронами которой образуют ориентированный цикл, т.е. в сети имеются обратные связи. При этом информация к нейронам может передаваться как с предыдущих слоев, так и от самих себя с предыдущей итерации (задержка) (рис. 4).
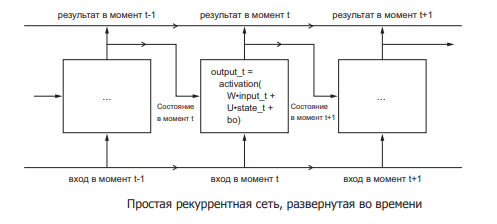
Рис. 4. Рекуррентная нейронная сеть
Характеристики сети:
- Каждое соединение имеет свой вес, который также является приоритетом.
- Узлы подразделяются на два типа: вводные и скрытые.
- Информация, находящаяся в нейронной сети, может передаваться как по прямой — слой за слоем, так и между нейронами.
Особенность рекуррентной нейронной сети состоит в том, что она имеет «области внимания». Данная область позволяет задавать фрагменты передаваемых данных, которым требуется усиленная обработка.
Информация в рекуррентных сетях со временем теряется со скоростью, зависящей от активационных функций. Данные сети применяются в распознавании и обработке текстовых данных.
Сеть долговременной краткосрочной памяти (Long short-term memory, LSTM) – особая разновидность архитектуры рекуррентных нейронных сетей, способная к обучению долговременным зависимостям. Поэтому LSTM подходит для прогнозирования различных изменений при помощи экстраполяции (выявление тенденции на основе данных), а также в любых задачах, где важно умение «держать контекст» (рис. 5).
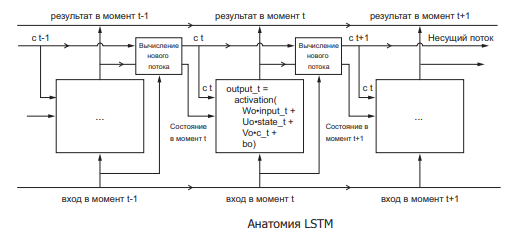
Рис. 5. Сеть долговременной краткосрочной памяти
Любая рекуррентная нейронная сеть имеет форму цепочки повторяющихся модулей нейронной сети. В RNN структура одного такого модуля очень проста, например, он может представлять собой один слой с функцией активации tanh (гиперболический тангенс). Структура LSTM также напоминает цепочку, но вместо одного слоя нейронной сети она содержат четыре, и эти слои взаимодействуют особенным образом.
Первый шаг в LSTM – определить, какую информацию можно выбросить из состояния ячейки. Это решение принимает сигмоидальный слой, называемый «слоем фильтра забывания» (forget gate layer).
Следующий шаг – решить, какая новая информация будет храниться в состоянии ячейки. Этот этап состоит из двух частей. Сначала сигмоидальный слой под названием «слой входного фильтра» (input layer gate) определяет, какие значения следует обновить. Затем tanh-слой строит вектор новых значений-кандидатов, которые можно добавить в состояние ячейки.
Затем происходит замена старых значений на новые, после чего происходит расчет выходных данных. Сначала в работу вступает сигмоидальный слой, который решает, какую информацию из состояния ячейки нужно выводить. Затем значения состояния ячейки проходят через tanh-слой, чтобы получить на выходе значения из диапазона от -1 до 1, и перемножаются с выходными значениями сигмоидального слоя, что позволяет выводить только требуемую информацию.
Самоорганизующаяся нейронная сеть (например, сеть Кохоннена,
рис. 6 и 7) – нейронная сеть, структура которой имеет один слой нейронов без коэффициентов смещения (тождественно единичных входов). Процесс обучения сети происходит при помощи метода последовательных приближений. Нейронная сеть подстраивается под закономерности входных данных, а не под лучшее значение на выходе. В результате обучения сеть находит область, в которой находится лучший нейрон, который в итоге на выходе будет иметь 1, а остальные нейроны, сигнал на которых получился меньше — 0.
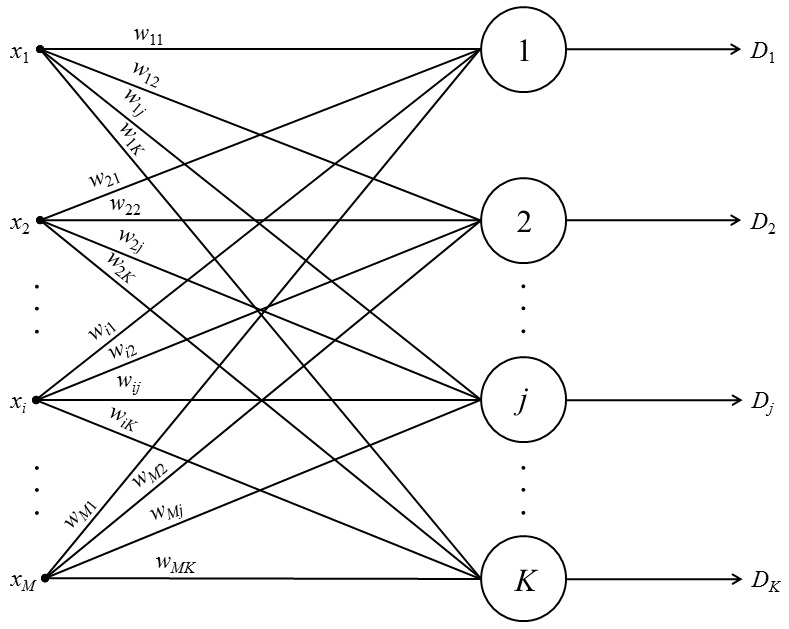
Рис. 6. Сеть Кохоннена
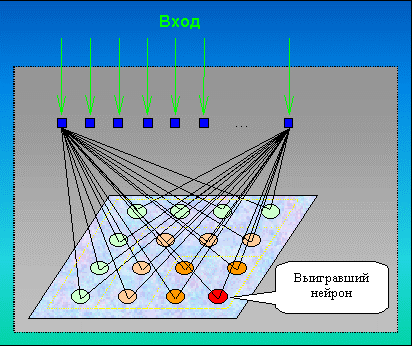
Рис. 7. Схема активации нейронов сетей Кохоннена
Такие сети часто используются в задачах кластеризации и классификации.
Генеративно-состязательная нейросеть (Generative adversarial network, GAN) — архитектура, состоящая из генератора и дискриминатора, настроенных на работу друг против друга. GAN по своей сути имитируют любое распределение данных. GAN обучают создавать структуры, похожие на сущности из реального мира в области изображений, музыки, речи, прозы (рис. 8).
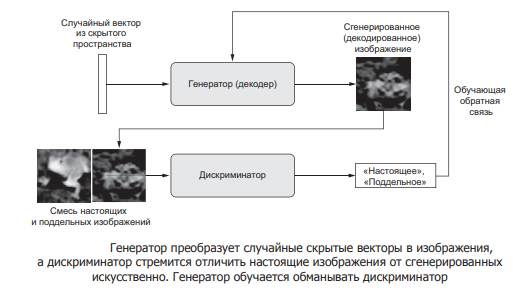
Рис. 8. Генеративно-состязательная нейросеть
Дискриминационные алгоритмы пытаются классифицировать входные данные. Учитывая особенности полученных данных, сети стараются определить категорию, к которой данные относятся.
Генеративные алгоритмы пытаются подобрать образы к данной категории.
Шаги, которые проходит GAN:
- Генератор получает случайное число и возвращает изображение.
- Это сгенерированное изображение подается в дискриминатор наряду с потоком изображений, взятых из фактического набора данных.
- Дискриминатор принимает как реальные, так и поддельные изображения и возвращает вероятности, числа от 0 до 1, причем 1 представляет собой подлинное изображение и 0 представляет фальшивое.
Таким образом, у GAN есть двойной цикл обратной связи:
- Дискриминатор находится в цикле с достоверными изображениями.
- Генератор находится в цикле вместе с дискриминатором.
Дискриминатор представляет собой стандартную сверточную сеть, которая может классифицировать изображения, подаваемые на нее с помощью биномиального классификатора, распознающего изображения как реальные или как поддельные. Генератор в некотором смысле представляет собой обратную сверточную сеть: хотя стандартный сверточный классификатор принимает изображение и уменьшает его разрешение, чтобы получить вероятность, генератор принимает вектор случайного шума и преобразует его в изображение. Первый отсеивает данные с помощью методов понижения дискретизации, таких как maxpooling, а второй генерирует новые данные.
Обе сети пытаются оптимизировать целевую функцию или функцию потерь в игре zero-sum.
При построении модели в первую очередь происходит выбор алгоритма ее работы, наиболее подходящего для решения конкретной задачи.
Обоснование необходимости использования объяснимого искусственного интеллекта (XAI)
Модели глубокого обучения и нейронные сети работают на основе скрытых слоев (т.е. между входными данными и выходным результатом существует несколько уровней математической обработки и принятия решений), но демонстрируют результаты лучше, чем базовые алгоритмы машинного обучения. Использование таких моделей в сферах с повышенным уровнем ответственности за принятые решения привело к созданию концепции объяснимого искусственного интеллекта, в рамках которой исследуются методы анализа или дополнения моделей ИИ, позволяющие сделать внутреннюю логику и выходные данные алгоритмов прозрачными и интерпретируемыми для человека (рис. 9).
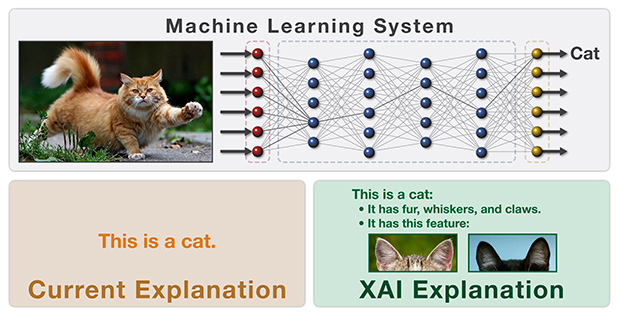
Рис. 9. Представление объяснения работы модели
Предполагается, что объяснимость ИИ будет включать в себя три составляющие: симулируемость, разложимость, алгоритмическую прозрачность.
Симулируемость означает возможность анализа модели человеком; наиболее важным критерием для симулируемости является сложность модели. Простые, но обширные (со слишком большим количеством правил) системы, основанные на правилах не соответствуют этой характеристике, тогда как одиночная нейронная сеть персептрона попадает в нее.
Разложимость означает способность объяснить каждую из частей модели (входные данные, параметры и выходные данные). Громоздкие функции не соответствуют данному критерию.
Алгоритмическая прозрачность означает способность пользователя понять процесс, которому следует модель ИИ, чтобы произвести любой заданный вывод из ее входных данных. Линейная модель ИИ считается прозрачной, потому что ее поверхность ошибок (математическая интерпретация механизма обучения ИИ) понятна и может быть рассмотрена, что дает пользователю достаточно знаний о том, как модель будет действовать в каждой ситуации, с которой он может столкнуться. В глубоких архитектурах ИИ этого не происходит, поскольку поверхность ошибок может быть непрозрачной и ее нельзя полностью наблюдать, соответственно, решение необходимо аппроксимировать с помощью эвристической оптимизации (например, с помощью стохастического градиентного спуска).
Объяснения алгоритмов работы ИИ могут быть представлены в текстовой или визуальной форме.
Текстовые объяснения представляют собой метод создания символов, отображающих логику алгоритма посредством семантического отображения.
Многие из методов визуализации сопровождаются методами уменьшения размерности для упрощения понимания работы модели человеком. Методы визуализации могут сочетаться с другими методами для улучшения их понимания и считаются наиболее подходящим способом представить сложные взаимодействия между переменными, участвующими в модели.
Существует несколько различных подходов для решения проблемы объяснимости ИИ.
Локальные объяснения сегментируют пространство решений и дают объяснения менее сложным подпространствам решений, которые актуальны для всей модели. Эти объяснения могут быть сформированы с помощью методов, которые объясняют часть функционирования всей системы.
Объяснения на примерах предполагают извлечение репрезентативных примеров, которые улавливают внутренние отношения и корреляции, обнаруживаемые анализируемой моделью данных, и относятся к результату, сгенерированному определенной моделью.
Объяснения посредством упрощения в совокупности обозначают те методы, в которых целая новая система ИИ перестраивается на основе обученной модели ИИ, которую необходимо объяснить. Новый ИИ обычно пытается оптимизировать свое сходство с изначальной моделью ИИ, уменьшая при этом ее сложность, но сохраняя тот же уровень производительности.
Методы апостериорного объяснения релевантности признаков проясняют внутреннее функционирование модели, вычисляя оценку релевантности для ее управляемых переменных. Эти оценки количественно определяют влияние (чувствительность) на выходные данные модели. Сравнение оценок различных переменных показывает вес, которую модель присваивает каждой из таких переменных при получении результатов.
Отсутствие объяснимости может приводить к ситуациям, когда модель присваивает более высокий вес тем входным переменным, которые объективно не должны иметь такого веса.
Пример: разбор решений модели, которая должна была классифицировать волков и хаски, показал, что она основывала свои выводы на факте наличия снега на фоне (рис. 10).

Рис. 10. Классификация волков и хаски на основе незначимого признака (наличия снега)
Злоумышленники могут добавлять небольшие искажения в изображения, которые не повлияют на решение человека, но могут сбить с толку алгоритм, ранее доказавший свою эффективность на не измененных искусственно изображениях (рис. 11).

Рис. 11. Намеренное незначительное искажение изображения
Этические проблемы, связанные с работой моделей черного ящика, возникают из-за их склонности непреднамеренно принимать несправедливые решения с учетом чувствительных факторов, таких как раса, возраст или пол человека. Пример: система оценки риска повторного совершения преступных деяний COMPAS принимала расу как одну из важных характеристик для принятия решения о высоком риске рецидива.
Интерпретируемые модели
Объясняемость может быть рассмотрена на всех этапах разработки ИИ, а именно: перед моделированием, в процессе разработки модели и после моделирования.
Самый простой способ добиться интерпретируемости — использовать только подмножество алгоритмов, создающих интерпретируемые модели ИИ. Линейная регрессия, логистическая регрессия и дерево решений являются обычно используемыми интерпретируемыми моделями ИИ.
Модель линейной регрессии прогнозирует цель как взвешенную сумму входных параметров. Линейность установленных отношений облегчает интерпретацию. Модели линейной регрессии давно используются статистиками, компьютерными специалистами и другими людьми, занимающимися количественными проблемами.
Линейные уравнения имеют легкую для понимания интерпретацию на модульном уровне (на уровне весов). Линейные модели широко распространены в медицине, социологии, психологии и др.
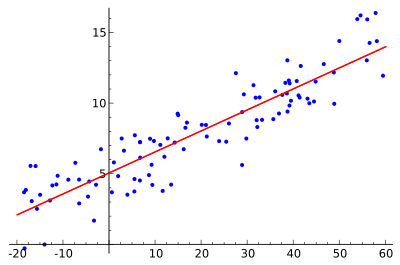
Рис. 12. Линейная регрессия
Отношения модели ИИ должны соответствовать определенным допущениям, а именно: линейность, нормальность, гомоскедастичность (имеют постоянную среднюю дисперсию), независимость, фиксированные характеристики и отсутствие мультиколлинеарности.
Однако, линейные модели имеют следующие недостатки. Каждая нелинейность или взаимодействие должны создаваться вручную и явно передаваться модели в качестве входной характеристики; в части взаимосвязей линейные модели сильно ограничены и обычно сильно упрощают реальность, что сказывается на их возможностях прогнозирования; интерпретация весов может быть сложна для понимания, поскольку зависимость прослеживается на всей модели. Признак с высокой положительной корреляцией с результатом y и другой признак могут получить отрицательный вес в линейной модели, потому что, учитывая другой коррелированный признак, он отрицательно коррелирует с y в многомерном пространстве. Полностью коррелированные функции делают невозможным поиск однозначного решения линейного уравнения.
Логистическая регрессия моделирует вероятности проблем классификации с двумя возможными исходамии является расширением модели линейной регрессии для задач классификации. Интерпретация более сложна по сравнению с линейной регрессией, поскольку интерпретация весов является мультипликативной, а не аддитивной.
Логистическая регрессия может пострадать от полного разделения. Если есть функция, которая идеально разделяет два класса, модель логистической регрессии больше не может быть обучена, поскольку вес для этой функции не будет сходиться — оптимальный вес будет бесконечным.
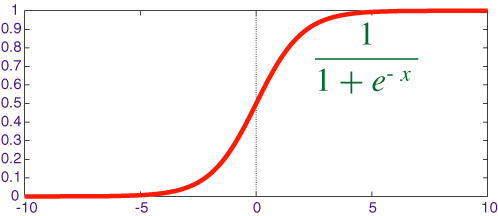
Рис. 13. Логистическая регрессия
Преимущество логистической регрессии в задачах классификации заключается в том, что она дает вероятности получения результатов для класса. Отсюда непосредственно вытекает ее практическое значение — это мощный статистический метод предсказания событий, которые являются результатом одной или нескольких независимых переменных.
Модель может быть расширена для предсказания нескольких классов, тогда она называется полиномиальная регрессия.
Обобщенные линейные модели (General linear model, GLM) расширяют возможности модели линейной регрессии. Эти модели дают возможность использовать переменные отклика с распределением ошибок, отличным от нормального. GLM — это общая математическая структура для выражения отношений между переменными, которые могут выражать или проверять линейные отношения между числовой зависимой переменной и любой комбинацией категориальных или непрерывных независимых переменных. Большинство методов машинного обучения с учителем каким-то образом расширяют GLM (через методы штрафов, метод ансамблей, объединение прогнозов из нескольких моделей машинного обучения в одном наборе данных и другие).
Обобщенная аддитивная модель (Generalized additive model, GAM) — это обобщенная линейная модель, в которой линейный предиктор линейно зависит от неизвестных гладких функций некоторых переменных-предикторов, и интерес сосредоточен на выводе об этих гладких функциях. В своей работе GAM использует сплайн-функции — функции, которые можно комбинировать для аппроксимации произвольных функций. GAM вводят штрафы для весов, чтобы они оставались близкими к нулю, что эффективно снижает гибкость сплайнов и снижает возможность переобучения. Параметр гладкости, который обычно используется для управления гибкостью кривой, затем настраивается с помощью перекрестной проверки.
Большинство модификаций линейной модели делают модель менее интерпретируемой. Любая функция связи, которая не является функцией идентичности, усложняет интерпретацию; взаимодействия также усложняют интерпретацию; эффекты нелинейных функций либо менее интуитивно понятны, либо больше не могут быть суммированы в одно число. GLM, GAM и другие расширения полагаются на предположения о процессе генерации данных. Если предположения не работают, интерпретация весов больше не действует.
Производительность древовидных ансамблей, таких как случайный лес или градиентное дерево, во многих случаях выше, чем у самых сложных линейных моделей.
Метод ансамблей базируется на алгоритмах машинного обучения, генерирующих множество классификаторов и разделяющих все объекты из вновь поступающих данных на основе их усреднения или итогов голосования. Изначально метод ансамблей был частным случаем байесовского усреднения, но затем усложнился дополнительными алгоритмами:
- бустинг (boosting) – преобразует слабые модели в сильные посредством формирования ансамбля классификаторов (улучшающее пересечение);
- бэггинг (bagging) – собирает усложнённые классификаторы, при этом параллельно обучая базовые (улучшающее объединение);
- корректирование ошибок выходного кодирования.
Метод ансамблей – более мощный инструмент по сравнению с отдельно стоящими моделями прогнозирования:
- сводит к минимуму влияние случайностей, усредняя ошибки каждого базового классификатора;
- уменьшает дисперсию;
- исключает выход за рамки множества: если агрегированная гипотеза оказывается вне множества базовых гипотез, то на этапе формирования комбинированной гипотезы оно расширяется при помощи того или иного способа, и гипотеза уже входит в него.
Дерево принятия решений — это метод поддержки принятия решений, основанный на использовании древовидного графа: модели принятия решений, которая учитывает их потенциальные последствия (с расчётом вероятности наступления того или иного события), эффективность, ресурсозатратность. Преимущества метода заключаются в том, что он структурирует и систематизирует проблему; итоговое решение принимается на основе логических выводов.
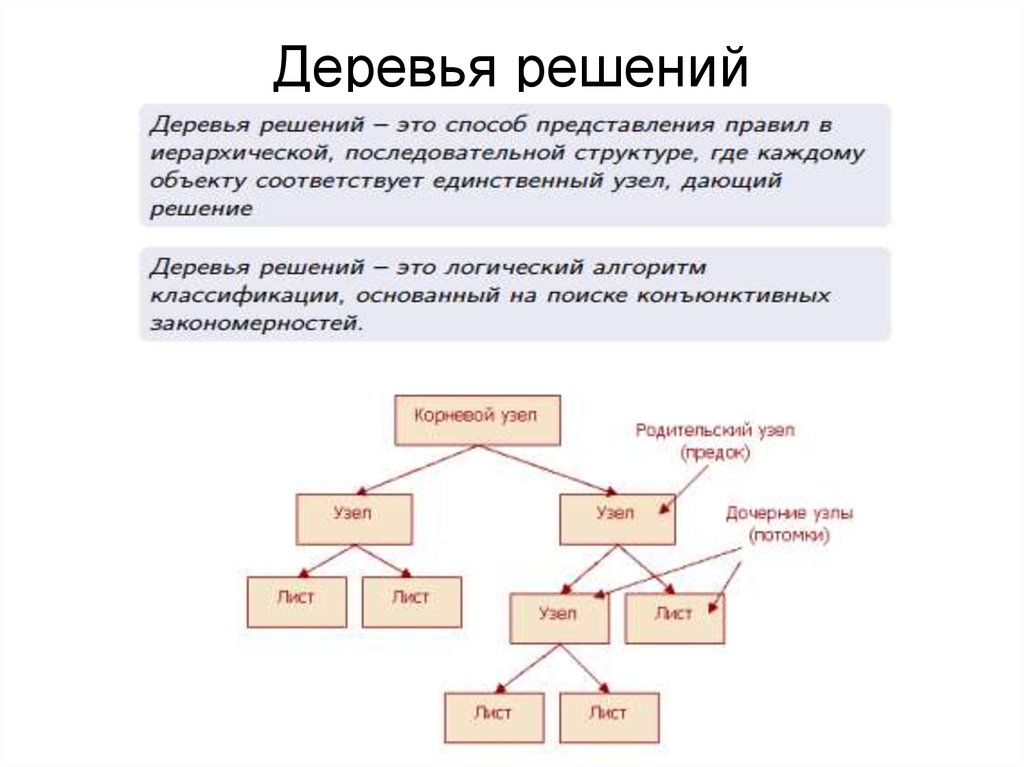
Рис. 14. Дерево решений
Наивные байесовские классификаторы относятся к семейству простых вероятностных классификаторов, основанных на теореме Байеса, которая рассматривает функции как независимые (это называется строгим, или наивным, предположением). Используется в следующих областях машинного обучения: определение спама, приходящего на электронную почту; автоматическая привязка новостных статей к тематическим рубрикам; выявление эмоциональной окраски текста; распознавание лиц и других паттернов на изображениях.
Алгоритм RuleFit изучает разреженную линейную модель с исходными функциями, а также ряд новых функций, которые являются правилами принятия решений. Новые функции отражают взаимодействие между исходными функциями. RuleFit автоматически генерирует эти функции из деревьев решений. Каждый путь через дерево может быть преобразован в правило принятия решения путем объединения разделенных решений в правило. Деревья решений в данном случае обучены предсказывать интересующий результат, что гарантирует необходимость разбиения для задачи прогнозирования. Для RuleFit можно использовать любой алгоритм, который генерирует множество деревьев решений, например, случайный лес (рис. 15).
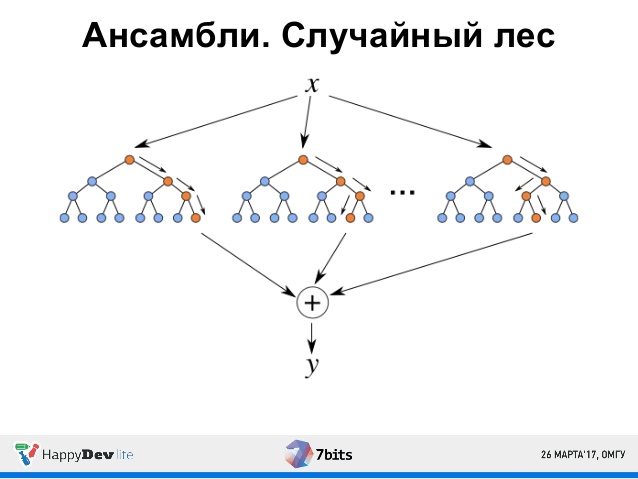
Рис. 15. Случайный лес
Каждое дерево разбивается на правила принятия решений, которые используются в качестве дополнительных функций в модели разреженной линейной регрессии. RuleFit имеет показатель важности функции, который помогает определить линейные условия и правила, которые важны для прогнозов. Важность функции рассчитывается на основе весов регрессионной модели. Показатель важности может быть агрегирован для исходных функций. RuleFit также представляет графики частичной зависимости, чтобы показать среднее изменение прогноза при изменении характеристики.
Метод k-ближайших соседей используется для задач классификации (иногда в задачах регрессии), объект относится к тому классу, которому принадлежит большинство из его соседей (рис. 16).
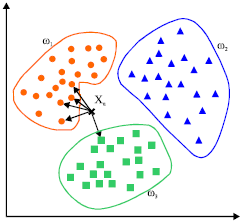
Рис. 16. K-ближайших соседей
В процессе обучения алгоритм просто запоминает все векторы признаков и соответствующие им метки классов. При работе с реальными данными, т.е. наблюдениями, метки класса которых неизвестны, вычисляется расстояние между вектором нового наблюдения и ранее запомненными. Затем выбирается k ближайших к нему векторов, и новый объект относится к классу, которому принадлежит большинство из них.
Увеличение значение параметра k повышает достоверность классификации, но при этом границы между классами становятся менее четкими. На практике хорошие результаты дают эвристические методы выбора параметра k, например, перекрестная проверка.
Несмотря на свою относительную алгоритмическую простоту, метод показывает хорошие результаты. Главный недостаток: высокая вычислительная трудоемкость, которая увеличивается квадратично с ростом числа обучающих примеров.
Апостериорные методы объяснений
Когда модели машинного обучения не соответствуют ни одному из критериев, налагаемых для объявления их прозрачными, необходимо разработать и применить к модели отдельный метод для объяснения ее решений. Это цель методов апостериорной объяснимости, которые нацелены на передачу понятной информации о том, как уже разработанная модель производит свои прогнозы для любого заданного входа.
Интерпретация в данных методах основана на ограниченном доступе к внутренней работе модели. Например, объяснения могут быть получены из градиентов, «прогона» модели в обратном направлении или с помощью запросов путем оценки более простых суррогатных моделей для фиксации наблюдаемого локального поведения входа-выхода.
Глобальные апостериорные объяснения полезны для принимающих решения лиц, которых поддерживает модель машинного обучения. Врачи, судьи и кредитные специалисты получают общее представление о том, как работает модель, но обязательно существует разрыв между моделью черного ящика и объяснением. Местные апостериорные объяснения актуальны для частных лиц, таких как пациенты, ответчики, на которых влияет результат модели и которым необходимо понимать ее интерпретацию с их конкретной точки зрения.
Большим преимуществом методов интерпретации, не зависящих от модели, по сравнению с методами интерпретации для конкретных моделей является их гибкость.
Желательными аспектами системы объяснения, не зависящей от модели, являются: гибкость модели (метод интерпретации может работать с любой моделью машинного обучения, такой как случайные леса и глубокие нейронные сети); гибкость объяснений (различные формы объяснений, например, линейная формула для одних случаев, график с важностью функций – для других); гибкость представления (система объяснения должна иметь возможность использовать другое представление объекта в качестве объясняемой модели).
LIME (Local interpretable model-agnostic explanations, локально интерпретируемое не зависящее от модели объяснение) объясняет классификатор для конкретного единичного выхода функции и поэтому подходит для локального рассмотрения. Объясняет отдельные прогнозы нейронной сети, аппроксимируя ее локально с помощью интерпретируемых моделей, таких как линейные модели и мелкие деревья.
Для локального объяснения решения алгоритма для определенного входа, линейная модель обучается имитировать алгоритм только для небольшой области вокруг входа. Эта линейная модель по своей природе может быть интерпретирована и сообщает, как изменится выход при изменении какой-либо входной функции.
LIME работает с табличными данными, текстом и изображениями.
Объяснения, созданные с помощью локальных суррогатных моделей, могут использовать другие (интерпретируемые) функции, которым была обучена исходная модель. Эти интерпретируемые функции должны быть получены из экземпляров данных. Классификатор текста может полагаться на встраивание абстрактных слов как на признаки, но объяснение может основываться на наличии или отсутствии слов в предложении. Модель регрессии может полагаться на неинтерпретируемое преобразование некоторых атрибутов, но объяснения могут быть созданы с использованием исходных атрибутов. Например, регрессионную модель можно обучить на компонентах метода главных компонентов ответов на опрос, а LIME можно обучить на исходных вопросах опроса. Использование интерпретируемых функций для LIME может быть большим преимуществом по сравнению с другими методами, особенно когда модель была обучена с неинтерпретируемыми функциями.
Методы, не зависящие от модели, основанные на возмущениях (такие как LIME) более склонны к нестабильности, чем их аналоги, основанные на градиентах.
В случае повторного процесса выборки, могут измениться объяснения. Нестабильность в данном случае означает, что объяснениям трудно доверять, и нужно быть очень критичным.
Локальные суррогатные модели с LIME очень многообещающие. Но этот метод все еще находится в стадии разработки, и необходимо решить многие проблемы, прежде чем его можно будет безопасно применять.
SHAP (Аддитивное объяснение Шепли) — метод объяснения индивидуальных прогнозов. SHAP основан на игре теоретически оптимальных значений Шепли. SHAP определяет предельный вклад каждой функции в достижение выходного значения, начиная с базового значения.
Значения Шепли рассматривают все возможные прогнозы с использованием всех возможных комбинаций входных данных. Благодаря такому подходу SHAP может гарантировать согласованность и локальную точность.
SHAP хорошо работает для задач классификации и регрессии, но плохо применим для обучения с подкреплением.
SHAP имеет прочную теоретическую основу в теории игр. Прогноз справедливо распределен между значениями признаков. На выходе можно получить контрастные объяснения, которые сравнивают полученный прогноз со средним прогнозом.
Быстрое вычисление позволяет вычислить множество значений Шепли, необходимых для интерпретации глобальной модели. Методы глобальной интерпретации включают важность характеристик, зависимость характеристик, взаимодействия, кластеризацию и сводные графики. С SHAP глобальные интерпретации согласуются с локальными объяснениями, поскольку значения Шепли являются «атомарной единицей» глобальных интерпретаций.
Недостатки метода:
- Проблема медленных решений (методы SHAP требуют вычисления значений Шепли для множества значений) остается актуальной для глобальных объяснений модели.
- SHAP может игнорировать зависимость функций при замене значений признаков случайными значениями, что, в свою очередь, может привести к приданию слишком большого значения маловероятным точкам данных.
TreeSHAP решает проблему экстраполяции к маловероятным точкам данных, но создает новую проблему. TreeSHAP изменяет функцию значения истинности, полагаясь на условное ожидаемое предсказание. При изменении функции, не влияющие на прогноз значения могут получить значение, отличное от нуля.
LIME и SHAP были признаны научным сообществом как самые многообещающие модели апостериорных объяснений, не зависящих от модели, однако группой ученых было проведено исследование, доказавшее, что данные методы плохо определяют необъективность модели. В эксперименте со специально созданным классификатором, который был явно необъективен, используя в качестве значимых признаков только данные о расе человека, данные методы игнорировали необъективность, находя вполне безобидные объяснения для полученных в ходе работы модели выходных данных.
Объяснения этих классификаторов, сгенерированные с использованием готовых реализаций LIME и SHAP, не помечают какие-либо важные чувствительные атрибуты (например, расу) как важные особенности классификатора для любого из тестовых примеров, демонстрируя, что необъективные классификаторы успешно обманули эти методы объяснения.
Две другие тесно связанные ветви методов интерпретируемости — это подходы, основанные на обратном распространении, и подходы на основе градиентов. Они либо распространяют решение алгоритма обратно по модели, либо используют информацию о чувствительности, предоставляемую градиентами потерь. Примеры: сети деконволюции, управляемое обратное распространение, Grad-CAM, интегрированные градиенты и послойное обратное распространение (LRP).
GradCAM — это метод атрибуции слоев, разработанный для сверточных нейронных сетей и обычно применяющийся к последнему сверточному слою. GradCAM вычисляет градиенты заданного выходного параметра по отношению к данному слою, усредняет их для каждого выходного канала и умножает средний градиент для каждого канала на активацию слоя. Результаты суммируются по всем каналам, и к выходу применяется функция активации ReLU, возвращающая только неотрицательные атрибуты.
GradCAM часто используется как общий метод атрибуции. Для этого атрибуты GradCAM подвергаются повышающей дискретизации и рассматриваются как маска для входных данных, поскольку выходные данные сверточного слоя обычно пространственно совпадают с входным изображением.
Многие из этих подходов были разработаны только для (сверточных) нейронных сетей. Заметным исключением является LRP.
Layer-wise relevance backpropagation (LRP) — это метод, который определяет важные пиксели путем выполнения обратного прохода в нейронной сети. Обратный проход — это консервативная процедура перераспределения релевантности, при которой нейроны, которые вносят наибольший вклад в более высокий уровень, получают от него наибольшую релевантность.
Метод может быть легко реализован на большинстве языков программирования и интегрирован в существующие нейронные сети. Правила распространения, используемые LRP, могут пониматься как глубокая декомпозиция Тейлора для многих архитектур, в том числе Deep Sparse Rectifier Neural Networks (сетей глубокого выпрямления) или LSTM.
LRP также отлично работает для сверточных нейронных сетей (CNN) и может использоваться для сетей долгой краткосрочной памяти (LSTM).
В методе интегрированных градиентов (Integrated Gradients, IG) градиент выходных данных прогноза вычисляется с учетом характеристик входных данных по интегральной траектории. Целью метода является объяснение взаимосвязи между предсказаниями модели с точки зрения ее характеристик. Использование: понимание важности функций, определение перекоса данных и отладка производительности модели.
IG стал популярным методом интерпретируемости из-за его широкой применимости к любой дифференцируемой модели, простоты реализации, теоретического обоснования и вычислительной эффективности по сравнению с альтернативными подходами, что позволяет масштабировать его до крупных сетей и функций.
Данный метод не требует модификации исходной сети, прост в реализации и применим к множеству глубоких моделей (разреженных и плотных, текстовых и визуальных).
Интегрированные градиенты определяют важность функций на отдельных примерах, но не предоставляют визуализацию важности функций для всего набора данных; определяют индивидуальные значения функций, но не объясняют взаимодействия и комбинации функций.
На основе метода интегрированных градиентов метод XRAI оценивает перекрывающиеся области изображения для создания карты значимости, которая выделяет соответствующие области изображения, а не пиксели (рис. 17).
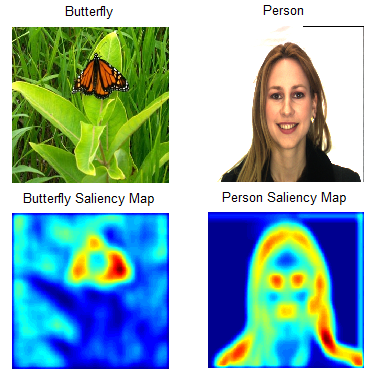
Рис. 17. Карта значимости признаков
Независимо от атрибуции на уровне пикселей, XRAI сверхсегментирует изображение, чтобы создать лоскутное одеяло из небольших областей. XRAI использует графовый метод для создания сегментов изображения. Затем происходит агрегация атрибуции на уровне пикселей в каждом сегменте, чтобы определить его плотность атрибуции. Используя эти значения, XRAI ранжирует каждый сегмент, а затем упорядочивает сегменты от наиболее положительного до наименее положительного. Это определяет, какие области изображения наиболее заметны или наиболее сильно влияют на предсказание класса.
Метод рекомендован для естественных изображений, которые представляют собой любые сцены реального мира, содержащие несколько объектов.
DeepLIFT — это подход, основанный на обратном распространении, который приписывает изменение входным данным на основе различий между входными данными и соответствующими ссылками (или базовыми показателями) для нелинейных активаций. Таким образом, DeepLIFT пытается объяснить разницу между исходными данными и эталонными данными с точки зрения разницы между входными данными и эталонными данными.
DeepLIFT SHAP — это метод, расширяющий DeepLIFT для аппроксимации значений SHAP. DeepLIFT SHAP берет распределение базовых показателей и вычисляет атрибуцию DeepLIFT для каждой пары исходных данных и базовых показателей и усредняет полученные атрибуции для каждого примера входных данных.
Правила DeepLIFT для нелинейностей служат для линеаризации нелинейных функций сети, метод аппроксимирует значения SHAP для линеаризованной версии сети. Метод также предполагает, что входные функции независимы.
Существующие решения для XAI
AIX360 от IBM — расширяемый набор инструментов, который предлагает ряд возможностей для улучшения объяснимости модели. Соответствующий пакет Python AI Explainability 360 включает в себя алгоритмы, охватывающие различные метрики объяснений наряду с посредническими метриками объяснимости, предоставляет инструменты для визуального исследования поведения обученных моделей с помощью минимального количества кода.
Набор инструментов включает в себя серию алгоритмов интерпретируемости, которые отражают современные исследования по этой теме, а также интуитивно понятный пользовательский интерфейс, который помогает понять модели машинного обучения с разных точек зрения. Один из основных вкладов AI Explainability 360 заключается в том, что он не полагается на единственную форму интерпретации модели машинного обучения. AI Explainability 360 дает разные объяснения для разных ролей, таких как специалисты по обработке данных или заинтересованные стороны в бизнесе. Объяснения, генерируемые AI Explainability 360 могут быть основаны на данных или на моделях.
Разработчики могут начать использовать AI Explainability 360, включив интерпретируемые компоненты с помощью API, включенных в набор инструментов. AI Explainability 360 включает в себя серию презентаций и руководств, которые могут помочь разработчикам относительно быстро начать работу.
Интерпретируемость модели в Microsoft Azure обеспечивается пакетом SDK, используя который можно объяснять предсказания модели через генерацию важности значения функций для всей модели или отдельных точек данных и с помощью интерактивной визуализации для обнаружения связей в данных и объяснений во время обучения модели.
Azureml-interpret использует методы интерпретируемости, разработанные в Interpret-Community, пакете Python с открытым исходным кодом для обучения интерпретируемых моделей и помощи в объяснении систем искусственного интеллекта с «черным ящиком». Interpret-Community служит базой для поддерживаемых моделей объяснения этого SDK и в настоящее время поддерживает следующие методы интерпретируемости: вариации SHAP (TreeSHAP, SHAP deep Explainer, SHAP Kernel explainer и др.), Global Surrogate1Основан на идее обучения глобальных суррогатных моделей, имитирующих модели черного ящика, Permutation Feature Importance Explainer2Метод, используемый для объяснения моделей классификации и регрессии. На высоком уровне работает путем случайного перемешивания данных по одной функции за раз для всего набора данных и вычисления степени изменения интересующей метрики производительности. Чем больше изменение, тем важнее эта функция. PFI может объяснить общее поведение любой базовой модели, но не объясняет отдельные прогнозы. Для объяснения работы глубоких нейронных сетей можно использовать TabularExplainer, который использует методы SHAP.
Google Cloud’s AI Explanations ставит целью использовать объяснения ИИ для упрощения разработки модели, а также объяснить поведение модели ключевым заинтересованным сторонам. AI Explanations работает с моделями, решающими задачи классификации и регрессии, демонстрируя, как та или иная функция данных повлияла на результат. В AI Explanations используются следующие методы: метод интегрированных градиентов, XRAI и Sampled Shapley. Для визуализаций используется What-If Tool.
В 2018 году Команда PAIR (People + AI Reserach, часть Google AI) представила What-If Tool — инструмент для обнаружения предвзятости в моделях искусственного интеллекта. Он поставляется как часть веб-приложения TensorBoard. What-If Tool визуализирует влияние определенных данных на предсказание модели, при этом доступен для тех, кто не разбирается в программировании.
What-If Tool позволяет:
- Автоматически визуализировать набор данных с использованием Facets. Facets Overview дает возможность получить представление о форме каждой функции набора данных; Facets Dive с помощью визуализации позволяет изучить отдельные наблюдения.
- Редактировать отдельные примеры из набора и отслеживать, как это отражается на результатах.
- Автоматически создавать графики частичных зависимостей, отражающие перемены в предсказании модели при изменении какого-либо одного свойства.
- Сравнивать наиболее похожие примеры из датасета, для которых модель дала разные предсказания.
Проверить работу инструмента можно на заранее обученных алгоритмах: модели многоклассовой классификации; модели классификации изображений; регрессионной модели. What-if-tool может работать с текстовыми, визуальным и табличными данными.
Платформа Thales XAI обеспечивает различные уровни объяснения, например, на основе примеров, на основе функций, контрфактов с использованием текстовых и визуальных представлений, однако стоит отметить, что упор делается на объяснение на основе семантики с помощью графов знаний. Графы знаний используются для кодирования лучшего представления данных, структурирования модели машинного обучения более интерпретируемым образом и принятия семантического сходства для локального (на основе экземпляров) и глобального (на основе модели) объяснения.
Объяснение любого предсказания связи получается путем определения репрезентативных горячих точек в графе знаний, то есть связанных частей графиков, которые при удалении отрицательно влияют на точность прогнозирования.
ELI5 — это пакет Python, который помогает отлаживать классификаторы машинного обучения и объяснять их прогнозы. Он обеспечивает поддержку нескольких платформ и пакетов машинного обучения:
scikit-learn. В настоящее время ELI5 позволяет объяснять веса и прогнозы линейных классификаторов и регрессоров scikit-learn, печатать деревья решений в виде текста или графическом формате SVG, показывать важность функций и объяснять прогнозы деревьев решений и ансамблей на основе деревьев.
Также поддерживаются Pipeline и FeatureUnion.
Функции некоторых инструментов в Eli5:
XGBoost — показать важность функций и объяснить прогнозы XGBClassifier, XGBRegressor и xgboost.Booster.
LightGBM — показать важность функций и объяснить прогнозы LGBMClassifier и LGBMRegressor.
CatBoost — показать важность функций CatBoostClassifier и CatBoostRegressor.
Keras – объяснить предсказания классификаторов изображений с помощью визуализаций GradCAM.
ELI5 также реализует несколько алгоритмов проверки моделей черного ящика:
TextExplainer позволяет объяснять предсказания любого текстового классификатора с использованием алгоритма LIME. Существуют также утилиты для использования LIME с нетекстовыми данными и произвольными классификаторами черного ящика, но эта функция в настоящее время является экспериментальной.
Метод перераспределения важности можно использовать для вычисления значимости признаков для оценщиков черного ящика.
Есть возможность получить текстовое объяснение для отображения на консоли, HTML-версию, встраиваемую в блокнот IPython или на веб-панели, версию JSON, которая позволяет реализовать настраиваемый рендеринг и форматирование на клиенте, а также преобразовать объяснения в объекты DataFrame pandas.
Пакеты с открытым исходным кодом значительно улучшили воспроизводимость исследований и внесли значительный вклад в недавние исследования в области глубокого обучения и XAI.
Некоторые программные пакеты XAI, доступные в GitHub:
Interpret от InterpretML может использоваться для объяснения моделей черного ящика и в настоящее время поддерживает объяснимый бустинг, деревья решений, список правил принятия решений, линейную логистическую регрессию, SHAP kernel explainer, TreeSHAP, LIME, анализ чувствительности Морриса и частичную зависимость.
Пакет IML охватывает такие методы как важность функций, графики частичной зависимости, графики индивидуальных условных ожиданий, накопленные локальные эффекты, суррогаты деревьев, LIME и SHAP.
Пакет DeepExplain включает различные методы на основе градиента, такие как карты значимости, интегрированные градиенты, DeepLIFT, LRP и др., а также методы на основе возмущений, такие как окклюзия, SHAP и др.
Проблемы, связанные с развитием и использованием XAI
В научных исследованиях, посвященных объяснимому искусственному интеллекту, одной из главных проблем развития XAI считается тот факт, что создание более понятной модели машинного обучения может в конечном итоге ухудшить качество принимаемых ею решений.
Не всегда верно, что более сложные модели по своей сути более точны. Это утверждение неверно в тех случаях, когда данные хорошо структурированы, а функции, имеющиеся в распоряжении разработчика, имеют высокое качество и ценность. Этот случай распространен в некоторых отраслевых средах, поскольку анализируемые функции ограничиваются контролируемыми физическими проблемами, в которых все функции сильно коррелированы, и в данных можно исследовать не так уж много возможного ландшафта значений.
Более сложные модели обладают гораздо большей гибкостью, чем их более простые аналоги, что позволяет аппроксимировать более сложные функции.
Дилемма аппроксимации тесно связана с интерпретируемостью: объяснения, сделанные для модели машинного обучения, должны соответствовать требованиям аудитории, для которой они формируются, обеспечивая репрезентативность исследуемой модели без излишнего упрощения ее основных черт.
В науке в отношении XAI еще не существует единых объективных показателей того, что конкретно является хорошим объяснением. Для решения данной проблемы исследователи предлагают провести ряд экспериментов в области человеческой психологии, социологии или когнитивных наук для создания объективно убедительных объяснений.
Объяснения более убедительны, когда они являются ограничительными, что означает, что предварительным условием для хорошего объяснения является то, что оно не только указывает, почему модель приняла решение X, но и почему она приняла решение X, а не решение Y. Для объяснений более важны причинно-следственные связи, чем определение вероятности. Необходимо преобразовать вероятностные результаты в качественные понятия, содержащие причинно-следственные связи. Возможно, достаточно сосредоточиться исключительно на основных причинах процесса принятия решений. В ряде исследований было доказано, что использование контрфактических объяснений может помочь пользователю понять решение модели.
Хотя методы объяснимости все чаще используются в качестве проверок работоспособности в процессе разработки, все еще существуют значительные ограничения на существующие методы, которые не позволяют их использовать для непосредственного информирования конечных пользователей. Эти ограничения включают в себя необходимость оценки объяснений экспертами в предметной области, риск ложных корреляций, отраженных в объяснениях модели, отсутствие причинно-следственной интуиции и задержку при вычислении и отображении объяснений в реальном времени. В будущих исследованиях следует стремиться устранить эти ограничения.
- 1Основан на идее обучения глобальных суррогатных моделей, имитирующих модели черного ящика
- 2Метод, используемый для объяснения моделей классификации и регрессии. На высоком уровне работает путем случайного перемешивания данных по одной функции за раз для всего набора данных и вычисления степени изменения интересующей метрики производительности. Чем больше изменение, тем важнее эта функция. PFI может объяснить общее поведение любой базовой модели, но не объясняет отдельные прогнозы
Похожие записи:
 Семантический анализ для автоматической обработки естественного языка
Семантический анализ для автоматической обработки естественного языка
 Компьютерное зрение: технологии, компании, тренды
Компьютерное зрение: технологии, компании, тренды
 Отчет о мониторинге правоприменения регулирования информационного пространства в странах мира в 2020 году
Отчет о мониторинге правоприменения регулирования информационного пространства в странах мира в 2020 году
 Рынок технологий Умного дома 2021 г.
Рынок технологий Умного дома 2021 г.
 Искусственный интеллект: технологии и применение
Искусственный интеллект: технологии и применение