Искусственный интеллект: технологии и применение

Под ИИ понимают комплекс технологических решений, который позволяет имитировать когнитивные (мыслительные) функции человека и получать результаты, сопоставимые, как минимум, с результатами интеллектуальной деятельности человека. При этом имитация включает самообучение и поиск решений без заранее заданного алгоритма.
ОГЛАВЛЕНИЕ
Введение. Искусственный интеллект: определение, технологии
Предиктивная аналитика, интеллектуальные системы поддержки принятия решений
ИИ в сфере информационной безопасности
Инициативы по развитию ИИ в РФ со стороны государства
Российские проекты с использованием ИИ
Заключение. Перспективы использования ИИ в Ведомстве
Введение. Искусственный интеллект: определение, технологии
Юридически понятие «искусственный интеллект» (ИИ) впервые было сформулировано Указом Президента РФ от 10 октября 2019 г. № 490 «О развитии искусственного интеллекта в Российской Федерации», а впоследствии в Федеральном законе № 123-ФЗ «О проведении эксперимента по установлению специального регулирования в целях создания необходимых условий для разработки и внедрения технологий искусственного интеллекта в субъекте Российской Федерации – городе федерального значения Москве и внесении изменений в статьи 6 и 10 Федерального закона “О персональных данных”».
Комплекс технологических решений включает в себя информационно-коммуникационную инфраструктуру, программное обеспечение (в том числе в котором используются методы машинного обучения), процессы и сервисы по обработке данных и поиску решений.
Принцип работы ИИ заключается в сочетании большого объема данных с возможностями быстрой, итеративной обработки этих данных интеллектуальными алгоритмами, что позволяет программам автоматически обучаться на базе закономерностей и признаков, содержащихся в данных.
ИИ представляет собой комплексную дисциплину со множеством теорий, методик и технологий. Ключевыми понятиями в ИИ являются:
Машинное обучение —алгоритмы анализа данных с целью найти в них закономерности. В нем используются методы нейросетей, статистики, исследования операций и т.п. для выявления скрытой полезной информации в данных; при этом явно не программируются инструкции, указывающие, где искать данные и как делать выводы.
Нейросеть — это один из методов машинного обучения; математическая модель, а также её программное или аппаратное воплощение, построенная по принципу организации и функционирования биологических нейронных сетей — сетей нервных клеток живого организма. В общем случае искусственная нейронная сеть (ИНС) может состоять из нескольких слоев простейших процессоров (нейронов), каждый из которых осуществляет некоторое математическое преобразование (вычисляет результат математической функции) над входными данными и передает полученный результат на следующий слой или на выход сети.
Алгоритм работы простейшей нейросети приведен на рисунке
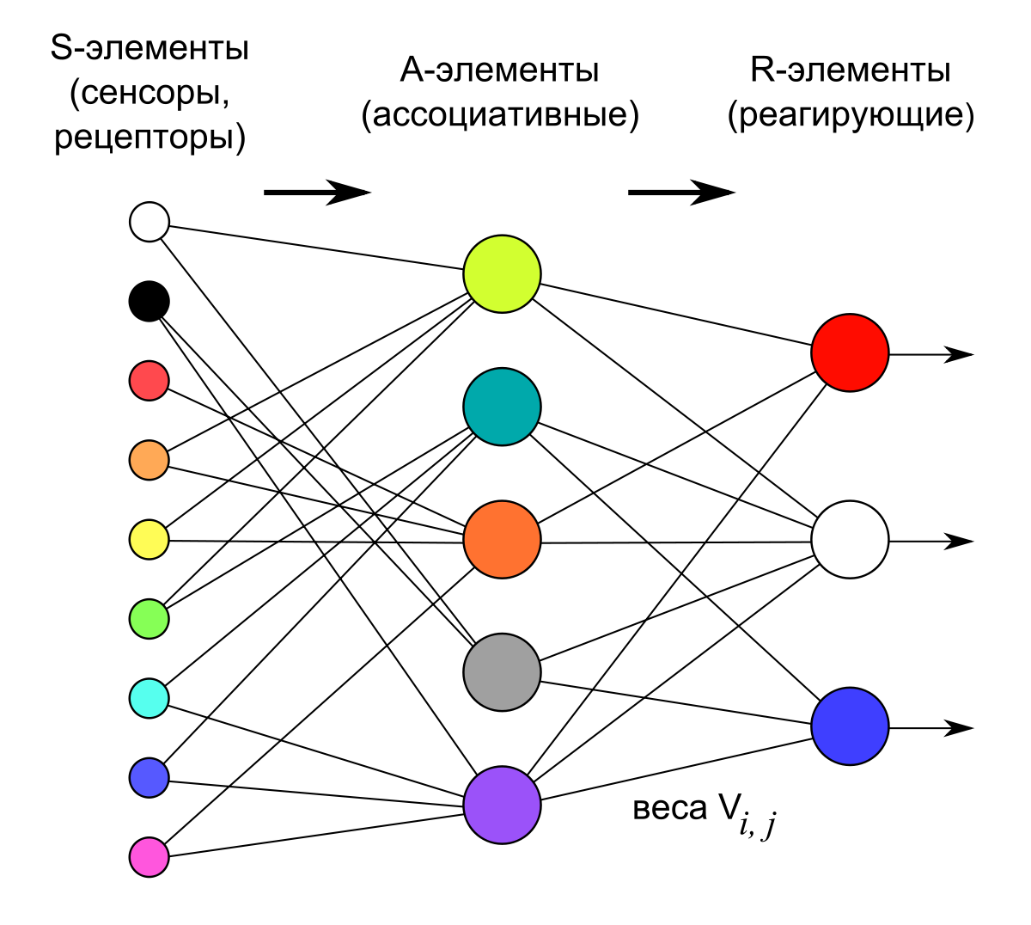
Нейроны входного слоя получают данные извне (например, от сенсоров системы распознавания лиц) и после их обработки передают сигналы через синапсы нейронам следующего слоя. Каждому из сигналов первоначально присваивается некоторый весовой коэффициент. Нейроны второго слоя (его называют скрытым, потому что он напрямую не связан ни с входом, ни с выходом ИНС) осуществляют математическое преобразование над полученными сигналами и передают вычисленный результат нейронам выходного слоя. Поскольку речь идет об имитации нейронов, то каждый процессор входного уровня связан с несколькими процессорами скрытого уровня, каждый из которых, в свою очередь, связан с несколькими процессорами уровня выходного. Выходной результат сравнивается с эталонным; в случае его несоответствия производится подстройка весовых коэффициентов. Процесс повторяется на большом наборе данных (так называемом обучающем датасете) до тех пор, пока выходное значение, генерируемое нейросетью, не будет совпадать с эталонным.
Таким образом, описанная простейшая ИНС способна к обучению и может находить простые взаимосвязи в данных. Более сложная модель ИНС будет иметь несколько скрытых слоев нейронов, перемежаемых слоями, которые выполняют сложные логические преобразования. Каждый последующий слой сети ищет взаимосвязи в предыдущем. Такие ИНС способны к глубокому (глубинному) обучению.
Для обучения глубоких нейросетей, а также для обнаружения сложных закономерностей в больших массивах данных используются повышенные вычислительные мощности и усовершенствованные методики. Распространенные области применения: распознавание изображений и речи.
Когнитивные вычисления — направление ИИ, задачей которого является обеспечение процесса естественного взаимодействия человека с компьютером, аналогичного взаимодействию между людьми. Конечная цель ИИ и когнитивных вычислений — имитация когнитивных процессов человека компьютером благодаря интерпретации изображений и речи с выдачей соответствующей ответной реакции.
Возможности современных технологий искусственного интеллекта реализуются по следующим направлениям (согласно информации Министерства экономического развития Российской Федерации):
- компьютерное зрение;
- обработка естественного языка;
- распознавание и синтез речи;
- интеллектуальные системы поддержки принятия решений (ИСППР).
Компьютерное зрение опирается на распознавание шаблонов и на глубокое обучение для распознавания изображений и видео. Машины уже умеют обрабатывать, анализировать и понимать изображения, а также снимать фото или видео и интерпретировать окружающую обстановку.
Обработка естественного языка — это способность компьютеров анализировать, понимать и синтезировать человеческий язык, включая устную речь. Используя Siri или Google assistant, уже можно управлять компьютерами с помощью обычного языка, используемого в повседневном обиходе.
ИСППР — инструментарий выработки рекомендаций для лица, принимающего решение. Алгоритмы упорядочивают (ранжируют) конечное множество альтернатив (решений) или оптимизируют их на бесконечном множестве, используя технологии датамайнинга, моделирования и визуализации..
Компьютерное зрение
Компьютерное зрение (Computer vision, CV) — это научное направление в области искусственного интеллекта, в частности робототехники, и связанные с ним технологии получения изображений объектов реального мира, их обработки, использования полученных данных для решения разного рода прикладных задач без участия (полного или частичного) человека.
Примеры задач компьютерного зрения: распознавание, идентификация, обнаружение, распознавание текста, восстановление 3D формы по 2D изображениям, оценка движения, восстановление сцены, восстановление изображений, выделение на изображениях структур определенного вида, сегментация изображений, анализ оптического потока.
В компьютерном зрении, как и в любой другой области, связанной с машинным обучением, для тренировки ИИ требуется большой объем структурированных размеченных данных (датасетов). Поэтому научные группы и исследовательские организации по всему миру в первую очередь работают над созданием, очисткой и дополнением открытых датасетов, содержащих гигантские массивы визуальных, либо графических данных.
Стандартный CV-датасет состоит из набора типовых размеченных изображений, разделенных на классы в зависимости от их семантического содержания.
Объем рынка Computer Vision растет и к 2023 году должен составить
25,32 миллиарда долларов. Взрывной рост ожидается на территории Азиатско-тихоокеанского региона, что подкрепляется растущими инвестициями.
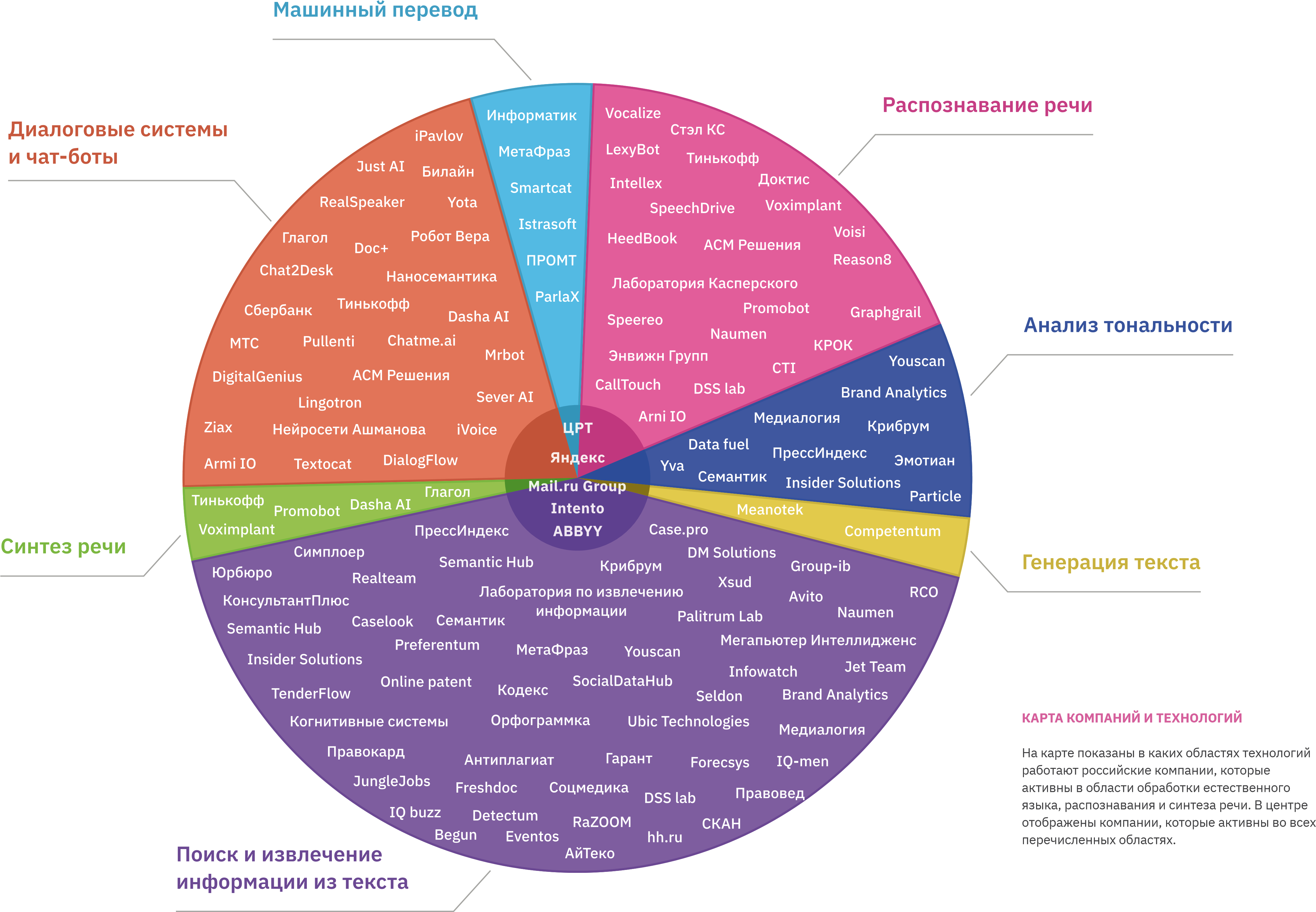
Рынок России также имеет тенденцию роста к концу 2023 года может вырасти по отношению к 2018 в 4,8 раз, что составит 38 млрд руб. Ключевые игроки на этом рынке сосредоточены на стратегическом партнерстве и сотрудничестве, приобретениях и выпусках новых продуктов для увеличения доходов. Ярким примером является подписанное 9 ноября 2019 года соглашение об альянсе Mail.ru Group, Сбербанк, Яндекс, Газпром нефть, МТС и РФПИ с целью реализации национальной стратегии развития искусственного интеллекта.
На стыке технологий появляются интересные решения, к примеру синергия технологий CV и предиктивной аналитики открывает дополнительные возможности аналитики посетителей и поведения аудитории. Совместное использование этих технологий позволяет анализировать популяционные характеристики аудиторных сегментов, которые описывают социально-демографическую структуру зарегистрированных с помощью компьютерного зрения посетителей, их профиль поведения. На основе полученной информации можно делать глубокие маркетинговые исследования, сегментировать аудиторию посетителей в оффлайне, сегментировать аудиторию с точки зрения различия их краткосрочных интересов, прогнозировать повторные посещения, отток и вектор коммерческих интересов посетителей.
Компьютерное зрение активно используется в Security&Integrity подразделениях и помогает справляться с различным нежелательным пользовательским контентом в продуктах крупных IT-компаний, таких как Google, Facebook, Mail.ru Group, Yandex. В связи со все нарастающим увеличением доли фото и видео-контента в коммуникационных и развлекательных сервисах модели, умеющие определять смысловое послание на основе визуальной составляющей, становятся неотъемлемой частью систем защиты. Наиболее частой используемой технологии зрения в Integrity является OCR, или автоматическое распознавание текста с изображения, ввиду простоты генерации фото текста со стороны злоумышленников.
Google, помимо проверки на спам писем в Gmail, использует OCR для улучшения категоризации своих писем, в частности писем-скидок. Facebook в 2019 г. в рамках своей стратегии по защите пользователей от нежелательного контента доложил об активном использовании NLP1Natural Language Processing, обработка естественного языка и CV в рамках единой модели для классификации такого контента, технологии CV используются для понимания смысла и OCR, что помогает визуально распознавать такие сложные кейсы, как постеры о продаже наркотиков. В 2018 Mail.ru Group на свое двадцатилетие Почты рассказала об использование распознавания логотипов и визуального оформления письма для борьбы с мошенническими письмами.
Компьютерное зрение активно применяется в поиске для выдачи релевантных изображений и видео. С развитием этой области появились такие алгоритмы, как сверточные и сиамские нейросети, метрическое обучение и т.д., с помощью которых машина учится понимать смысл сложных объектов. Это позволяет поисковикам решать огромный спектр задач: от общего поиска информации в интернете до некоторых более специфичных проблем, которые представляют отдельный интерес.
За последние три года применение компьютерного зрения стало трендом и в финансовой отрасли. В мире этому способствует переориентация финансовых и страховых компаний на цифровые каналы рапространения, появление комплексных fintech- и insuretech-решений. В России драйверами роста рынка CV в финансовой отрасли также стали развитие национальной программы цифровой экономики и инициатива Центрального Банка РФ по созданию национальной цифровой платформы для сбора, обработки и хранения биометрических персональных данных.
В 2018-2019 гг. появились сертифицированные интеграционные решения для систем контроля управления доступом (СКУД) и портативные терминалы для организации контроля доступа по биометрическим данным. Обработка видеопотока, выбор лучшего кадра и наибольшего лица на нём, проверка liveness, извлечение и сравнение биометрических слепков могут выполняться непосредственно на устройстве, что позволяет добиться результатов, близких к скорости при прикладывании бесконтактной карты. А интеграция со СКУД повышает удобство сотрудников (так как отпадает необходимость носить с собой карту) и снижает риск несанкционированного доступа третьих лиц на охраняемую территорию по скомпрометированным учётным данным/пропускам.
Терминалы оплаты, которые позволяют оплатить покупку «по лицу» — еще один пример востребованных решений, использующих технологии CV. Возможность подтверждения транзакции лицом в пилотном режиме тестируется в сетевых магазинах, пиццериях, кофейнях.
Классические сценарии использования решений, основанных на технологии распознавания лиц, интегрированы с ESB или CRM системами финансовых и страховых организаций и используются в процедурах KYC (Know Your Customer, «Знай своего клиента»), кредитного скоринга и идентификации клиентов. Перспективными выглядят попытки применения алгоритмов распознавания в банкоматах, системах управления очередями и интеграция с ПО для видеонаблюдения. Всё чаще финансовые организации используют биометрические данные в качестве дополнительного фактора подтверждения финансово-значимых операций в удалённых каналах.
Компьютерное зрение необходимо для создания автономных машин, индустриальных роботов и других сценариев, где требуется та же способность к визуальному анализу, которой обладают люди.
Чтобы нивелировать человеческий фактор, увеличить повторяемость и повысить надежность контроля, при визуальном поиске дефектов продукции используются системы машинного зрения. Условно их можно разделить на две части: контроль полуготового материала и осмотр уже готового продукта в конце производственного цикла. С использованием нейросетей можно выявлять от 92% до 99% всех дефектов в зависимости от задачи, при ложных срабатываниях на уровне 3-4%. Нормальный уровень брака на разных производствах составляет от 0,5% до сотых процента. Такие показатели вполне подходят, чтобы заменить человека, который обнаруживает эти дефекты. Кроме визуального анализа, есть и другие способы проведения неразрушающего контроля, встречающиеся, например, в сталелитейной промышленности, такие как ультразвуковой, вихретоковый и рентгеновский контроль. Помимо традиционных камер, возможно задействовать информацию о температуре поверхности и геометрическую информацию о предмете.
Современные системы видеоаналитики могут выявлять потенциально опасные ситуации на промышленных предприятиях. Отслеживание событий по заданным параметрам позволяет минимизировать число нежелательных инцидентов, обеспечивать бесперебойную работу оборудования и снижать риск производственного травматизма. Используя камеры и данные с других сенсоров на производственной площадке, операторы могут дать роботам и машинам возможность совместной безопасной работы.
Среди основных сценариев работы промышленной видеоаналитики — контроль наличия средств индивидуальной защиты (каски, страховочные тросы, халаты, наушники) и доступа в опасные зоны. С помощью видеоаналитики можно также определить открытый огонь, прорыв трубопровода, разливы, задымления, выявить факты нарушения целостности ограждений, пронос объектов за периметр, обнаружить оставленные предметы. Отслеживание курения на площадке или использования телефона в определенных местах (например, на заправочной станции) также становится возможным. Другим сценарием использования компьютерного зрения для контроля безопасных условий труда является мониторинг состояния работающего персонала и определение усталости.
Видеоаналитика применяется для мониторинга производственных площадей и инфраструктуры. Возможности видеоаналитики по определению и локализации движущихся объектов и транспортных средств, местоположению оборудования и людей, отслеживанию происходящего на каком-либо участке превосходят возможности человека. Такое управление компьютерными системами и умное распределение задач повышает общую производительность и увеличивает отдачу от использования оборудования.
Проблемы сбора данных для последующего анализа часто связаны с тем, что на многих предприятиях осталось старое, еще советское оборудование. Оснащать его датчиками не всегда экономически целесообразно. Чтобы оцифровать такое оборудование и сэкономить на переоснащении, возможно использование компьютерного зрения для считывания данных с экранов.
Роботы с системами компьютерного зрения способны учитывать расположение объектов, анализируя видеопоток с 3D-камеры и данные от лазеров и сенсоров. Такой подход позволяет роботам выполнять задачи с высокой точностью и практически при любом освещении. Модели компьютерного зрения используются при планировании перемещений робота и для избежания столкновений. Источником данных для алгоритмов служит лазерный дальномер (лидар), установленный на роботе, который с заданной частотой отправляет на вход алгоритма компьютерного зрения вектор координат.
Камеры видеонаблюдения являются основой систем мониторинга транспорта. Основными применениями, уже сейчас находящие широкое применение, являются: системы видеофиксации нарушений ПДД; управление стоянкой транспортных средств; система мониторинга траффика (определить загруженность, повысить безопасность, увеличить пропускную способность за счёт адаптивного управления светофорами; регистрировать дорожные инциденты); системы безопасности для определения факта угона, проведения розыскных или антитеррористических мероприятий.
В Москве построена одна из самых масштабных в мире систем безопасности с идентификацией личности. Система заработала в сентябре 2017 г. в тестовом виде и осенью 2019 эксперимент признан успешным. До недавнего времени система работала на 1500 одновременных видеопотоках. Для распознавания лиц камеры городской системы видеонаблюдения используют базу МВД. Алгоритм отслеживает в реальном времени лица людей и сравнивает результаты поиска с базами данных. В рамках пилотного внедрения видеоаналитики используется алгоритм одной из отечественных компаний — NtechLab — одного из признанных мировых лидеров.
В медицине компьютерное зрение используется для автоматизированного анализа всех видов диагностической визуализации: цитология и патогистология, изображение кожных покровов, места болезни, эндоскопическая картина, результаты лучевых исследований (рентгенографии, компьютерные и магнитно-резонансные томографии, гибридные методики, ультразвуковые изображения). Основные задачи: скрининг, поддержка принятия диагностических решений, повышение производительности труда врача, контроль качества и профилактика ошибок.
Обработка естественного языка
Обработка естественного языка (Natural Language Processing, NLP) — пересечение машинного обучения и математической лингвистики, направленное на изучение методов анализа и синтеза естественного языка. NLP применяется во многих сферах, в том числе в голосовых помощниках, автоматических переводах текста и фильтрации текста.
Основными тремя направлениями являются: распознавание речи (Speech Recognition), понимание естественного языка (Natural Language Understanding) и генерация естественного языка (Natural Language Generation).
Глубокое обучение существенно повысило (и продолжает повышать) качество машинной обработки языка, для некоторых задач — уже вплотную к человеческому уровню.
Организации могут использовать NLP-приложения двумя способами:
- Для понимания запросов пользователя, сформулированных на естественном языке (как текстовых, так и голосовых):
- Обеспечение более качественного и таргетированного ответа посредством понимания вопросов пользователей и их желаний;
- Выявление внешних запросов и представление интеллектуальных альтернатив.
- Для понимания содержания текстов (извлечение информации из массивов неструктурированных данных):
- Извлечение из текстовых документов юридической информации для идентификации сотрудников, клиентов, продукции, процедур и т.д;
- Идентификация и понимание значения контента на естественном языке (документы, отчеты, электронная почта и т.д.) с целью предоставления ответов на естественном языке.
NLP позволяет лучше понимать запросы пользователей и анализировать корпоративную информацию. Использование данной технологии гарантирует, что у каждого пользователя есть доступ к наиболее актуальным, полезным источникам информации, которые иначе остались бы скрытыми в огромных объемах данных.
Основные типы обработки естественного языка:
- оптическое распознавание символов (Optical Character Recognition): механический или электронный перевод изображений рукописного, машинописного или печатного текста в текстовые данные, использующиеся для представления символов в компьютере.
- распознавание речи (Speech Recognition): преобразование произнесенных слов в данные, которые может понять компьютер. Это NLP-технология, которая используется в голосовых помощниках типа Siri, Алиса, Cortana, Echo или Google Assistant.
- машинный перевод (Machine Translation): перевод текста с одного языка на другой. Эта технология лежит в основе таких приложений для перевода, как Google Translate или Яндекс Переводчик.
- вывод информации на человеческом языке (Natural Language Generation): эта технология используется, когда Алиса, Siri или Cortana отвечают на ваш вопрос.
- анализ настроений (Sentiment Analysis): извлечение данных из контекста (часто «большого текста», big text) и оценка того, являются ли эти данные эмоционально отрицательными или положительными.
- семантический поиск (Semantic Search): тесно связанная с распознаванием речи технология, которая позволяет задавать вопросы голосовым помощникам как при разговоре с другим человеком.
- программирование на естественном языке (Natural Language Programming): это инструменты, которые позволяют пользователям создавать приложения и программное обеспечение, используя команды на естественном языке (вместо программирования традиционным способом).
- аффективные вычисления (Affective Computing): использование NLP и других технологий для понимания и воспроизведения человеческих эмоций.
Рыночные тенденции в сегменте NLP:
| Тренд | Описание |
| Внедрение голосовых интерфейсов | Развитие технологий speech-to-text будет первым шагом для упрощения офисных задач (например, планирования времени руководителя, поиска документов, обработки конфиденциальной информации). С повышением точности распознавания, глубины понимания и качества синтеза речи голосовые интерфейсы будут интегрированы практически во все устройства: диалоговые системы в умном доме, автомобиле, бытовой технике, боты-помощники. |
| Рост числа чат-ботов | Рост количества интеллектуальных ассистентов в различных отраслях бизнеса, в том числе в коммерческих сервисах банков, ритейлеров, телекома и других компаний, которые активно взаимодействуют с клиентами. Все вербальное общение с массовой аудиторией в наиболее популярных сервисах будут вести роботы, которые научатся распознавать эмоции, используя в том числе мультимодальную оценку эмоций, и будут сами использовать эмоциональную составляющую в разговоре. |
| Поиск информации на естественном языке | Интеллектуальный поиск с возможностью делать запросы на естественном языке. Все больше организаций хотят быстро находить неструктурированные данные во всех внутренних источниках, автоматически определять их содержание и выделять значимые факты в специализированных юридических или финансовых текстах. За счет развития глубоких моделей извлечения фактов из текстов и автореферирования их содержания будет существенно повышаться качество поиска информации. |
| Создание и развитие собственных решений | Крупные компании — банки, телеком, промышленность — будут развивать и наращивать собственную экспертизу в области ИИ, в том числе разговорного с собственной командой лингвистов, data scientists, NLP-инженеров и т.д. Примеры аутсорсинга отдельных задач в ближайшее время останутся малочисленными. Уже наблюдается быстрый рост ИИ команд многих крупных компаний. |
Распознавание и синтез речи
Распознавание и синтез речи — система решений, позволяющих осуществлять перевод речевого запроса в текстовый вид, в том числе анализ тембра и тональности голоса, распознавание эмоций.
Системы автоматического распознавания речи, как правило, являются компонентом программных продуктов и используются для автоматизации процессов и упрощения взаимодействия между пользователем и информационной системой. Примерами наиболее успешного применения технологии распознавания речи могут служить программные продукты, использующиеся в call-центрах. Распознавание в составе таких продуктов позволяет в автоматическом режиме обрабатывать простые запросы, контролировать качество оказываемых услуг и оценивать уровень удовлетворённости клиентов. Также среди большого числа людей популярность приобрели различные голосовые помощники.
Одним из ключевых компонентов таких систем является модуль распознавания речи. Также с развитием индустрии развлечений значительно увеличился и объём аудиовизуальных данных. Необходимость субтитрирования таких данных является ключевой при обеспечении доступности контента для людей с ограничениями слуха. Не менее значимыми являются системы диктовки, которые переводят речь в текстовое представление для дальнейшего автоматического формирования протоколов, извлечения тезисов и подготовки заметок. Такие системы популярны в журналистике, медицинской диагностике, составлении протоколов судебных заседаний или совещаний. Технология распознавания речи широко применяется в сфере образования: в различных программных продуктах, направленных на изучение иностранных языков. Использование технологии позволяет оценивать произношение учащегося и контролировать процесс обучения.
Внедрение ИИ расширило область применения технологий синтеза речи. В недалеком будущем синтез станет применяться для автоматического создания новостных сюжетов, озвучивания фильмов, игр и интерактивных образовательных курсов. Каждый сможет создать цифровую копию своего голоса и свободно общаться на различных языках. Возможно, что голосовые интерфейсы будут внедряться даже в обычные бытовые устройства, а умные колонки станут незаменимым атрибутом любой квартиры.
Хотя нейронные системы синтеза дали большой скачок в плавности и натуральности звучания, по-прежнему остается множество нерешенных проблем, например, эмоциональный синтез или синтез редких языков, для которых трудно найти достаточный объем данных для моделирования. Отдельно стоит упомянуть об этической стороне разработки подобных систем, ведь качественные синтезаторы, способные повторять тембр голоса человека, используя всего лишь несколько минут его речи, могут быть использованы мошенниками для взлома биометрических систем, шпионажа или шантажа. Все эти вопросы должны быть решены в будущем.
Главное препятствие сегодня состоит в том, что нейросеть генерирует речь слово за словом. Т.е., хотя она и генерирует связный текст, глядя далеко назад, она не держит мысль, глядя далеко вперед. У нее нет плана диалога и намерения донести до собеседника какую-то идею, как-то подвести его к ней. Она просто развивает определенную тему. Соответственно, следующее поколение моделей языка должно иметь определенный замысел истории и развивать свою мысль, исходя из какой-то конечной цели. Без этого невозможно будет создать искусственный разум, способный аргументированно отстаивать и доказывать свою точку зрения.
NLP применяется как часть информационных войн, которые идут на уровне государств. Эти войны идут в пространствах социальных сетей, СМИ, поисковиков, интернет-порталов, форумов, блогов. Одна из самых известных историй последнего времени — скандал с компанией Cambridge Analytica, которая анализировала данные профилей около 87 млн. пользователей Facebook и подбирала для них рекламные сообщения так, чтобы склонить данного пользователя к определенному голосованию на выборах в США, в частности, на выборах президента США Дональда Трампа в 2016 году.
Также в этой области технологии NLP активно применяются для быстрого анализа информационного поля и ситуативного реагирования. Например, основатель компании Крибрум Игорь Ашманов рассказывал об информационной атаке на один из крупнейших российских банков, когда в сети появилось много личных сообщений о потенциальных проблемах банка с выдачей наличных. В результате туда выстроились огромные очереди и банк пережил сильный отток денежных средств. Анализ сообщений позволил выявить эту серию сообщений, источники появления и предположительных интересантов такой атаки.
Еще одно применение, активно используемое государственными службами, это анализ информационного пространства (в основном соцсетей) с попыткой выявления активных групп граждан, общающихся, например, на оппозиционные темы или в целом негативно настроенными по отношению к власти. Целью такого анализа может быть прогноз несанкционированных митингов или выявление лидеров мнений. Также достаточно давно технологии NLP работают в системах технических средств для обеспечения функций оперативно-разыскных мероприятий, которые стоят на всех основных каналах коммуникации у крупных телеком-операторов, позволяя анализировать открытый трафик (например, электронную почту или телефонные звонки) с целью выявления определенных ключевых слов и оперативного реагирования на возникающие ситуации.
Одно из самых последних применений технологий NLP — генерация текстов на заданную тему. Приложений для такого применения много — начиная от негативных отзывов о компании-конкуренте в сети и до генерации фейковых новостей по заданной теме с целью информационной атаки.
Предиктивная аналитика, интеллектуальные системы поддержки принятия решений
Предиктивная аналитика (ПА) используется при прогнозировании будущих событий. ПА анализирует текущие и исторические данные, используя методы из статистики, интеллектуальный анализ данных, машинное обучение и искусственный интеллект для того, чтобы делать прогнозы о будущем. ПА объединяет вместе математику, информационные технологии и бизнес-процессы производства и управления. Бизнес может эффективно использовать большие данные для увеличения прибыли путем успешного применения предиктивной аналитики. Возможности предиктивной аналитика значительно выросли вместе с развитием больших данных.
Этапы построения предиктивной модели:
- Сбор требований.
- Сбор данных.
- Подготовка и анализ данных. Неструктурированные данные преобразуются в структурированную форму. Проверка качества данных, устранение ошибок и пропусков. Формирование обучающей и тестовой выборок.
- Статистика, машинное обучение. Все модели прогнозной аналитики основаны на статистических и/или машинных методах обучения. Машинное обучение часто имеет преимущество перед традиционными статистическими методами, но методы статистики, как правило, всегда вовлекаются в разработку любой прогнозной модели.
- Прогнозная модель. Разработка и тестирование модели.
- Прогнозирование и мониторинг. После успешных испытаний модель разворачивается для ежедневных прогнозов и процесса принятия решений. Результаты и отчеты генерируются моделью для управленческого процесса. Модель регулярно контролируют, чтобы убедиться, что она дает правильные результаты и делает точные прогнозы.
Некоторые из наиболее распространенных применений ПА:
Обнаружение мошенничества: обнаружение и предотвращение преступного поведения могут быть улучшены благодаря объединению нескольких методов анализа. Поведенческая аналитика может применяться для мониторинга действий в сети в режиме реального времени, идентифицировать аномальные действия, которые могут быть признаками мошенничества. Новые угрозы также могут быть обнаружены путем применения этой концепции.
Снижение риска: прогнозная аналитика применяется при оценке вероятности дефолта покупателя или потребителя, которым присваивается кредитный рейтинг. Кредитный рейтинг генерируется предиктивной моделью, используя все данные, связанные с кредитоспособностью человека/компании. Предиктивные модели применяются банками при выпуске кредитных карт и страховыми компаниями для выявления мошеннических действий клиентами.
В нефтегазовой промышленности системы обнаружения аномалий и предиктивного обслуживания являются важными областями применения машинного обучения. Широко распространенное применение сенсоров способствует использованию этого вида аналитики. Дефекты турбомашин, насосов и двигателей могут быть обнаружены на ранней стадии, и, таким образом, можно предотвратить дальнейшие потери за счет перевода внеплановых ремонтов в плановые.
Выгоды от внедрения подходов анализа данных были наглядно продемонстрированы в проекте Boston Consulting Group по созданию системы управления нефтегазовой платформой. Получение оперативных данных помогает в предупреждении остановов динамического оборудования и оценке достижимого потенциала его работы. Помимо этого, контроль процесса открывает новые возможности по работе с узкими местами производства.
Оптимизация маркетинговой кампании: применение прогнозной аналитики может выявить потенциальных клиентов и побудить их купить продукт. ПА активно используется для продвижения перекрестных продаж, помогает компаниям привлекать и удерживать выгодных клиентов.
Раннее обнаружение аномалий в технологическом процессе — одна из основных целей промышленного интернета вещей. Известные шаблоны процессов могут быть прерваны редкими событиями, которые обычно не обнаруживаются специалистом. В худшем варианте развития событий аномалия может привести к остановке всей производственной линии. Учитывая огромные массивы данных с сенсоров промышленных предприятий, поиск аномалий с помощью ручного осмотра кажется неразумным.
Украинский поставщик технологий Sciforce рассказывает о своем клиенте, который хотел ускорить регулярные алгоритмы обработки и повысить стабильность системы. Они создали коммерческий процесс обнаружения аномалий, который включает само обнаружение аномалий и прогнозирование будущих аномалий. В качестве моделей для обнаружения они использовали автоэнкодеры, для прогнозирующей части использовались рекуррентные нейронные сети. Эти модели давали достаточно точные прогнозы на срок до 10 минут.
Прогнозирование запасов и управление ресурсами может быть достигнуто путем применения ПА. Авиакомпании могут использовать ПА, чтобы установить цены на билеты, отели — для прогнозирования количества гостей на определенную ночь, чтобы максимизировать занятость и увеличить доход, фармацевтические компании могут предсказать истечение срока годности лекарств в конкретном регионе из-за спада продаж и точнее спланировать производство.
Прогнозирование спроса: компания Predictive Layer предлагает решение для прогнозирования потребления электроэнергии. Специализированный движок для динамического ценообразования помог сформировать достаточно точный прогноз потребления на следующий день. Заявленная экономия годовой закупки электроэнергии на национальных рынках электроэнергии ЕС составляет более $45 млн.
В логистике в масштабах международных корпораций стало возможным создание единой цифровой логистической системы. DHL и IBM описывают функцию ИИ в логистике в связке с роботизацией процессов (RPA), где ИИ учится копировать и улучшать процессы на основе данных, предоставленных RPA. Системы искусственного интеллекта становятся помощниками в логистических процессах, основанных на человеческих решениях. Помимо RPA, системы искусственного интеллекта помогают логистике перевести свою операционную модель с реактивного поведения на прогнозирование и упреждающие операции с помощью различных моделей прогнозирования
Система поддержки принятия клинических решений: экспертные системы на основе прогнозных моделей могут быть использованы для установления диагноза у пациента. ПА может использоваться при разработке лекарств.
ИИ в сфере информационной безопасности
На текущий момент количество кибератак растёт, а ландшафт угроз меняется с молниеносной скоростью. Например, продукты Kaspersky отражают более 700 млн онлайн-атак в квартал по всему миру (данные за вторую четверть 2019 года), а Cisco заявляет о блокировании 20 млрд сетевых атак в день (более 7 триллионов атак за 2018 год). Очевидно, что при таких объёмах вредоносной деятельности злоумышленники активно применяют средства автоматизации кибератак, в том числе технологии искусственного интеллекта и машинного обучения для их совершенствования и трансформации, а также для обхода известных средств защиты. Так, например, эффективным прототипом является известный троян Emotet. Основным каналом для его распространения является спам-фишинг, и группировка, стоящая за созданием Emotet, могла без особых затруднений использовать ИИ для усиления атаки, встраиваясь нативно в цепочки разговоров и используя анализ текста на естественном языке.
Другой возможной сферой вредоносного применения искусственного интеллекта является более эффективный подбор паролей или обход двухфакторной аутентификации. Ещё два года назад исследователи создали бота, который был способен обходить проверки СAPTCHA с эффективностью в 90% с помощью технологий ИИ. Используя огромное количество различных источников данных в даркнете для формирования базы знаний искусственного разума, злоумышленники могут сделать атаки на человека по-настоящему действенными. Для того, чтобы справиться с растущим объёмом атак, производители систем защиты тоже начинают активно внедрять технологии искусственного интеллекта, машинного и глубокого обучения для обнаружения, прогнозирования киберугроз, реагирования на них в режиме реального времени. По данным Webroot, около 85% профессионалов по информационной безопасности считают, что злоумышленники используют технологии ИИ в своих атаках.
В 2019 году мировой рынок технологий искусственного интеллекта в информационной безопасности оценивается экспертами (MarketsandMarkets, Zion Market Research) в $8 млрд, с достижением $30 млрд в 2025 году и ежегодным ростом на 23%.
Организации, внедряющие технологии искусственного интеллекта для поведенческого анализа и предиктивной аналитики, получают ощутимые результаты в виде повышения эффективности обнаружения атак, сокращения времени реагирования и затрат на организацию безопасности.
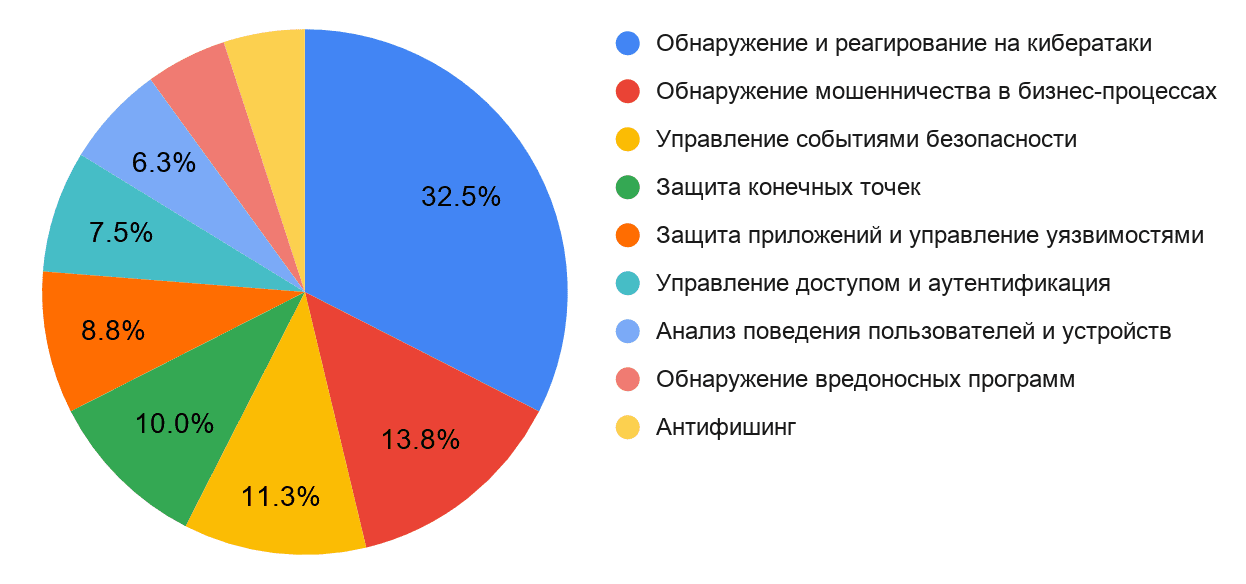
Распределение продуктов с применением технологий ИИ по сценариям использования
Классификация продуктов ИБ с технологиями искусственного интеллекта по сценариям применения
EDR (Endpoint Detection and Response) — платформы обнаружения атак на рабочих станциях, серверах, любых компьютерных устройствах (конечных точках) и оперативного реагирования на них. С помощью технологий ИИ продукты данной категории могут обнаруживать неизвестные вредоносные программы, автоматически классифицировать угрозы и самостоятельно реагировать на них, передавая данные в центр управления. ИИ принимает решения на основе общей базы знаний, накопленной путём сбора данных со множества устройств. Некоторые продукты данного типа используют технологии ИИ для разметки данных на конечных точках и дальнейшего контроля их перемещения, чтобы выявлять внутренние угрозы.
NDR (Network Detection and Response) — устройства и аналитические платформы, которые обнаруживают атаки на сетевом уровне и позволяют оперативно на них реагировать. Используя накопленную статистику и базу знаний об угрозах, продукты данного типа выявляют с помощью технологий ИИ угрозы в сетевом трафике и могут автоматически на них реагировать надлежащим образом, изменяя конфигурацию сетевых устройств и шлюзов. Часть продуктов данного типа специализируется на защите облачных провайдеров и их инфраструктуры. Дополнительный сценарий использования ИИ в сетевой защите — это анализ почтового трафика на предмет фишинга.
Антифрод (Antifraud) — системы, позволяющие выявлять угрозы в бизнес-процессах и предотвращать мошеннические операции в режиме реального времени. В системах защиты от мошенничества технологии ИИ применяются для определения отклонений от установленных бизнес-процессов, тем самым помогая быстро реагировать на возможное финансовое преступление или уязвимость процессов. Применение ИИ в таких системах особенно актуально, так как позволяет быстро адаптироваться к изменению логики и различных метрик бизнес-процессов, а также использовать лучшие практики в индустрии.
Выделить из миллиардов сигналов и огромных массивов разноформатных данных информацию, которая реально важна для отражения атаки, крайне сложно. Человек потратит на такой анализ слишком много времени. И напротив, встроенная система машинного обучения может проводить поведенческий анализ миллиардов сигналов каждый день. Это позволяет значительно сократить время реагирования на инциденты.
Так, при атаке на обычного пользователя Windows (например, с целью установки майнера в браузер), система распознает и блокирует ее за миллисекунды, а атаку на компанию enterprise-уровня система обнаруживает за несколько секунд. В итоге на каждый экземпляр зловредного софта, проанализированный экспертом компании, существующая система на базе Machine Learning и Artificial Intelligence обеспечивает защиту еще от 4500 зловредов.
ИИ в цепочке поставок
За прошедшие годы применение искусственного интеллекта в управлении цепочками поставок (Supply Chain Management, SCM) значительно возросло во всем мире благодаря более высокому спросу на прозрачность и отслеживаемость данных, а также необходимости улучшить обслуживание клиентов. Ведущие отрасли с точки зрения принятия ИИ в SCM (по данным на начало 2020 года) – телекоммуникации (26%), высокие технологии (23%), здравоохранение (21%), профессиональные услуги (19%), а также путешествия, транспорт и логистика (18%).
Несмотря на преимущества интеграции ИИ, некоторые организации не могут реализовать его из-за следующих проблем:
- Ограниченная доступность высококачественных, согласованных и обновляемых (в режиме реального времени) данных;
- Наличие данных о цепочке поставок в разных отделах (например, отдел маркетинга, отдел инвентаризации, менеджер по закупкам и другие имеют собственные базы данных);
- Ограниченная интеграция между системами и базами данных для доступа, очистки и анализа данных;
- Ограниченные политики управления данными, связанные с расширенной цепочкой поставок.
Эксперты по закупкам полагают, что недавние сбои в цепочке поставок, вызванные пандемией COVID-19, как никогда подчеркивают необходимость интеграции ИИ в цепочку поставок для оптимизации работы. Чтобы избежать критического сбоя в цепочке поставок, организации необходимо иметь полную картину всей экосистемы; точно прогнозировать спрос и предложение; и оптимально планировать логистику и доставку, среди прочего. ИИ, наряду с машинным обучением, позволяет организациям точно предвидеть загрузку/проблемы в снабжении и, соответственно, заранее предпринимать необходимые (предупредительные/корректирующие) шаги.
С помощью решений ИИ можно собирать и анализировать в реальном времени и исторические данные от нескольких подключенных устройств и систем (включая системы SCM, ERP и CRM), чтобы получить более широкую и глубокую информацию о работе, которая очень полезна для лиц, принимающих решения. Используя эти решения, команда по закупкам может получить представление о цепочке поставок, предвидеть проблемы (будь то внутри организации, например, из-за сбоев, или за ее пределами, например, задержка поставок) и принимать альтернативные меры для минимизации воздействия на цепочку поставок. Задержка с фактическим реагированием отрицательно сказывается на цепочках поставок и, соответственно, на чистой прибыли.
Традиционно прогнозирование не включает детали в режиме реального времени и основывается исключительно на исторических данных. Однако с использованием ИИ точность прогнозирования значительно повысилась, что позволяет руководителям не только лучше планировать, но и повышать эффективность.
Решения ИИ позволяют лицам, принимающим решения, анализировать существующие маршруты, выявлять узкие места и сосредотачиваться на наилучшем маршруте; это уменьшает как время, так и общую стоимость складирования и доставки. Инструменты обработки данных на основе ИИ и ML помогают фиксировать детали, связанные с перемещением товаров в реальном времени, и правильно оценивать время доставки.
Инициативы по развитию ИИ в РФ со стороны государства
Президент РФ Владимир Путин, выступая 4 декабря 2020 года на конференции AI Journey, анонсировал цифровую трансформацию России с повсеместным внедрением технологий искусственного интеллекта (ИИ) и больших данных в ближайшие 10 лет. В частности, глава государства назвал ряд правительственных решений, которые будут стимулировать развитие технологий в стране: формирование стратегии цифровой трансформации 10 ключевых отраслей российской экономики; внедрение ИИ-алгоритмов во все рабочие процессы; запуск экспериментальных правовых режимов, для реализации которых Правительству поручено оперативно разработать соответствующие законы; повышение эффективности управленческих процессов с помощью ИИ; совершенствование системы образования, в том числе школьного, в области современных технологий. Также Президент поручил в начале 2021 года внести проект закона о доступе ИИ-разработчиков к государственным большим данным.
Получить бесплатный доступ к статистическим данным — к показателям рождаемости, смертности, заключения браков, разводов — бизнес сможет уже в
2023 году. К этому времени Росстат планирует запустить центральную аналитическую платформу «Население», она должна стать «витриной данных» для граждан и бизнеса. В отличие от нынешней системы Росстата, которая фиксирует показатели ежемесячно, предполагается, что новая платформа будет это делать в режиме реального времени.
Федеральный проект «Искусственный интеллект» утвержден 27 августа 2020 г. на заседании президиума правительственной комиссии по цифровому развитию.
В декабре 2020 года о согласованном бюджете федерального проекта «Искусственный интеллект» (ИИ) и его структуре сообщил вице-премьер РФ Дмитрий Чернышенко в ходе совещания Президента РФ Владимира Путина с членами Правительства. На реализацию проекта «ИИ» предусмотрено 86,5 млрд руб., из них 24,6 млрд руб. — это бюджетное финансирование, 6,9 млрд руб. – привлеченные внебюджетные средства, 55 млрд руб. — средства Сбера.
В федеральном проекте нашли отражение шесть поставленных Президентом России в Национальной стратегии развития искусственного интеллекта задач:
- Поддержка научных исследований;
- Создание комплексной системы правового регулирования;
- Разработка и развитие программного обеспечения;
- Повышение доступности и качества данных;
- Увеличение доступности аппаратного обеспечения;
- Рост обеспеченности квалифицированными кадрами;
- Повышение уровня информированности населения.
К развитию ИИ в России привлекаются крупные государственные и частные компании.
Между Правительством Российской Федерации и ПАО «Сбербанк» подписано Соглашение о намерениях, предусматривающее подготовку компанией и утверждение Правительством Российской Федерации «дорожной карты» развития высокотехнологичной области «Искусственный интеллект». Отдельно подписано Соглашение между Правительством Российской Федерации и АО «УК «РФПИ», предусматривающее содействие в привлечении инвестиций в российские компании в области искусственного интеллекта совместно с международными партнерами.
Согласно дорожной карте развития «сквозной» цифровой технологии «Нейротехнологии и искусственный интеллект» 2019 года, в различных отраслях выделяются следующие области применения ИИ:
«Сельское хозяйство, лесное хозяйство, охота, рыболовство и рыбоводство»: повышение эффективности процессов селекции за счет учета генетических и фенотипических параметров, повышение урожайности за счет выстроенной автономной системы ухода за культурами, снижение затрат на техническое обслуживание и ремонт за счет прогнозирования поломок техники.
«Добыча полезных ископаемых»: оптимизация разведки и извлечения запасов на основе анализа геофизических данных, повышение эффективности и безопасности производственного процесса за счет применения автономного оборудования и транспорта, предотвращение простоев оборудования и дорогостоящих ремонтов за счет превентивного обслуживания.
«Обрабатывающие производства»: повышение качества и снижение затрат на проектирование продукции за счет комплексного моделирования параметров будущего продукта, автоматизация и оптимизация производственных процессов и сети поставок за счет снижения производственных ошибок, минимизации влияния человеческого фактора и эффективное прогнозирование спроса.
«Обеспечение электрической энергией, газом и паром»: сокращение сроков и затрат на проектирование и строительство объектов за счет анализа данных об условиях строительной площадки и опыта пр. проектов, оптимизация ремонтов за счет предиктивного обслуживания оборудования, оптимизация процессов управления сложными энергетическими системами за счет улучшения процессов диспетчеризации.
«Строительство»: улучшение качества строительного процесса за счет обнаружения ошибок строительства, использование ИИ для моделирования и анализа потенциальных опасностей (пожарных рисков, рисков разрушения здания и др.), улучшение качества архитектурного планирования за счет анализа изображений окрестностей.
«Торговля оптовая и розничная»: минимизации влияния человеческого фактора и эффективное прогнозирование спроса, оплата товаров и услуг голосом, который был идентифицирован искусственным интеллектом, прогнозирование поведенческой модели покупателя на основании ретроспективных покупок, автоматизация инвентаризации в магазине за счет использования распознавания изображений.
«Транспортировка и хранение»: оптимизация выстраивания маршрутов, учитывая прогнозы транспортных потоков и характеристик ТС, обеспечение безопасности вождения за счет выявления и предупреждения опасных ситуаций, использование беспилотных ТС, предотвращение поломок транспорта за счет прогнозирования неисправностей, оптимизация работы распределительных центров за счет автоматизированного учета продукции и скорости погрузки, роботизация складов.
«Деятельность гостиниц и предприятий питания»: мгновенный перевод речи туристов в гостиницах, создание персонализированного меню и диеты, автоматизированная доставка продуктов питания.
«Деятельность в области информации и связи»: оптимизация распределения сетевых ресурсов на основе реального времени и анализ прогнозной нагрузки, рекомендации в области необходимых инвестиций по строительству сетевой инфраструктуры за счет оценки потребностей сети, прогноз региональных тенденций спроса на телекоммуникационный трафик.
«Деятельность финансовая и страховая»: оценка кредитоспособности заемщиков и предложение новых банковских продуктов на основе данных о транзакциях, данных о клиенте в соцсетях, чат-боты, в том числе голосовые системы обработки клиентских запросов, повышение безопасности операций и предотвращение мошенничества, повышение эффективности планирования личных финансов и управления инвестициями, персонализация, таргетинг.
Российские проекты с использованием ИИ
12 ноября 2020 года на стратегической сессии руководители цифровой трансформации (РЦТ) семи федеральных органов исполнительной власти — Минэнерго, Минпромторга, Минкультуры, Минобрнауки, Росреестра, Россельхознадзора, ФНС — представили проекты по внедрению решений в сфере ИИ в своих ведомствах и формированию отраслевых датасетов.
В рамках данной сессии вице-премьер Дмитрий Чернышенко поручил Минцифры разработать реестр готовых решений в сфере ИИ для последующего применения в федеральных ведомствах.
В декабре Минцифры сформировало перечень ИИ-решений, которые будут внедряться в российских министерствах в 2023-2024 годах. Список решений представлен в письме, направленном в правительство замминистром цифрового развития Олегом Качановым. Предполагается, что внедрять их будут МВД, МЧС, Минздрав, Минпромторг, Федеральная налоговая служба (ФНС), Росреестр, Федеральный фонд обязательного медицинского страхования (ФФОМС).
Среди решений:
- ФФОМС планирует создать с использованием искусственного интеллекта сервис моделирования тарифов на оказание медицинской помощи; напоминать о визите к врачу и записи, собирать обратную связь и т.д.; голосового помощника для «умных» колонок и др.
- Росреестр с помощью нейросетей намерен распределять документы по типам, а также анализировать изображения, с помощью которых сможет различать объекты капитального строительства.
- МЧС планирует использовать искусственный интеллект для анализа изображений: находить на спутниковых снимках и ортофотопланах пожары, подтопления, наводнения, разрушения, ДТП и другие опасные ситуации.
- ФНС задействует искусственный интеллект для внедрения голосового ассистента для консультаций, а также для создания классификаторов по вновь поступающим вопросам и товарным наименованиям.
- МВД намерено использовать программное обеспечение с технологией искусственного интеллекта для идентификации и поиска лиц, выявления взаимосвязей между событиями, а также анализа биоматериала для определения внешних анатомических признаков (цвет глаз, волос, форма лица, головы).
- Минздрав планирует с помощью нейросетей выявлять новообразования и признаки COVID-19 на КТ-изображениях, снимках с микроскопов, данных лучевой диагностики.
- Минпромторг с помощью нейросетей создаст чат-бот, который будет консультировать пользователей по доступным мерам поддержки. Ведомство также намерено использовать технологию при анализе документов заявителей.
МЧС России во время стратегической сессии для РЦТ в октябре 2020 года представило проект по выявлению термических аномалий, прогнозированию уровня воды и распознаванию инфраструктуры и разрушений на снимках.
Министр государственного управления, информационных технологий и связи Московской области Максим Рымар сообщил, что за две недели с момента активного внедрения искусственного интеллекта в работу службы 122 удалось значительно разгрузить операторов. При этом он продемонстрировал реальный пример записи на приём к врачу с использованием ИИ. По функционалу и звуковым показателям система практически не отличается от речи оператора.
Алгоритм московской компании NtechLab по распознаванию deepfake-видео признан экспертами из лаборатории Facebook AI и Калифорнийского университета в Сан-Диего наиболее устойчивым к обману с использованием «состязательных атак» — малозаметных искажений видео, которые позволяют обмануть нейросеть. Анализ алгоритмов исследователи провели после того, как он в июне текущего года занял третье место на международном соревновании Deepfake Detection Challenge.
Сбербанк и исследовательское подразделение Microsoft Research разработали систему на основе искусственного интеллекта для управления роботами. Она позволяет обучить роботов взаимодействовать с физическим миром.
Ключевой целью исследовательского проекта была разработка решения, способного взаимодействовать с людьми, освобождая их от механически сложной рутинной работы и обеспечивая высокий уровень безопасности. Система может применяться в различных сферах — от логистики до проведения спасательных операций.
Работа над проектом осуществлялась в «Лаборатории робототехники» Сбербанка в Москве и в Microsoft в Беркли и Редмонде в США и длилась с мая 2019 года по май 2020. Разработчики должны были создать технологию выгрузки с помощью робота-манипулятора инкассаторских мешков с монетами весом до 6 кг из мобильных тележек для их последующей обработки в счетных машинах. Испытания системы в реальных условиях показали, что она может работать с точностью до 95%.
Входящие в группу Сбербанка компании — «СберЗдоровье», «СберМед ИИ» и «Лаборатория по искусственному интеллекту» — запустили онлайн-сервис постановки предварительного диагноза с помощью искусственного интеллекта.
По словам представителя сервиса «СберЗдоровье», в «памяти» системы 265 различных диагнозов, что охватывает 95% всех возможных случаев диагнозов россиян при первом обращении в больницы. Точность распознавания варьируется от 75 до 91%. Сервис работает исключительно на основе машинного обучения и опирается на экспертизу врачей.
Сбербанк также разработал решение SMART UAT, которое автоматизирует обработку входящих извещений об участии в приемо-сдаточных испытаниях ИТ-релизов. AI-based сервис работает в режиме поддержки принятия решений и позволяет автоматически определять необходимость участия сотрудников и персональный состав экспертов кибербезопасности для резолюции по каждому релизу. В системе используется доверительный порог, согласно которому AI-модель либо автоматически формирует отказ от участия, либо предлагает профильному эксперту решение и его вероятностные характеристики.
Сбербанк планирует открыть в России международный институт искусственного интеллекта. О планах открыть в январе 2021 года такой институт сообщил глава Сбербанка Герман Греф в первый день конференции AI Journey, проходившей в декабре 2020 года. По его словам, основная миссия института — обеспечить междисциплинарный подход к исследованиям для создания общего искусственного интеллекта.
Компания «Хоппер ИТ» внедрила роботизированный мониторинг работоспособности 2 000 цифровых сервисов с помощью решения «Сервис-монитор». Автоматизируются ручные процессы эскалации, уведомления и восстановления работоспособности цифровых сервисов.
Скрипты имитируют действия пользователей, обнаруживая проблемы, о которых еще не узнали жители и сотрудники. Система позволяет быстро выявить причину сбоя и устранить ее до широкого распространения среди пользователей.
Решение «Сервис-монитор» использует технологию компьютерного зрения для распознавания интерфейсов и облегчения поддержки роботизированных скриптов.
Собираются большие данные о работе цифровой инфраструктуры и происходит корреляционный анализ влияния технических ресурсов на сбои в бизнесе.
Команда МАК «Вымпел» внедрила на предприятии ПАО «Магнитогорский металлургический комбинат» программно-технический комплекс «Мониторинг-Предиктив», который контролирует работу электромеханического оборудования в процессе его эксплуатации.
Беспроводные датчики измеряют электромагнитное поле электродвигателей и их вибрацию. Полученные данные передаются в систему, которая быстро и точно определяет наличие и тип неисправностей и заблаговременно прогнозирует возможные дефекты составных частей электродвигателя.
Процессы технического обслуживания и ремонта электромеханического оборудования переведены из режима плановых ремонтов на обслуживание по состоянию, что существенно снижает затраты на его содержание.
Технология предсказания износа и выхода из строя агрегатов построена на методах кластеризации и машинного обучения. Для классификации неисправностей применялась нейронная сеть на базе многослойного персептрона, которая содержит 15 входных нейронов, по числу основных дефектов.
Специалисты компании ВКонтакте разработали собственный сервис по генерации ответов службы поддержки — «Долорес». Он автоматически формирует три варианта ответа на запрос. Агент Поддержки выбирает наиболее подходящий и отправляет его пользователю.
Если ни один из ответов не подходит, то запрос направляется на второй уровень к агентам Поддержки. Система определяет категорию вопроса и передает его сотруднику, отвечающему за это направление.
Детектор троллей выявляет несерьезные вопросы, а «Долорес» умеет шутливо на них отвечать.
Компания МТС создала единое окно мониторинга договоров и автоматизировала работу с документами.
Система позволяет работать как с электронными документами в формате MS Office, так и со скан-копиями, которые после загрузки обрабатываются при помощи технологий оптического распознавания и компьютерного зрения.
Решение распознает вид документа по его заголовку, ищет типовые разделы, извлекает из них данные, которые заносятся в базу для дальнейшего использования.
Даты выполнения обязательств фиксируются в памяти системы. Напоминания приходят ответственным сотрудникам по выбранным каналам связи. Если срок наступил, а договор не закрыт, сотрудник разрешает системе формировать претензионные документы.
Заключение. Перспективы использования ИИ в Ведомстве
Поскольку одна из основных задач ИИ – автоматизация рутинных процессов, в Роскомнадзоре и ФГУП «ГРЧЦ» могут быть применены следующие технологии: сервис по генерации ответов службы поддержки; автоматизированная работа с обращениями граждан; автоматизированная система закупок (проверка закупочной документации) и работы с документами.
В части мониторинга СМИ и сети «Интернет» ИИ может быть применен для автоматического выявления запрещенного контента, распознавания образов на фото и видео, семантического анализа контента, анализа информационного пространства социальных сетей. ИИ может быть успешно применен для выявления всех видов fake news: фото, видео, аудио, текста.
Решения ИИ могут значительно упростить работу лицам, принимающим решения, предоставляя рекомендации, основанные на получаемых системой данных. ИСППР могут быть применены для решения задач распределения ресурсов.
Вследствие последних тенденций в области цифровизации аналитики информационной безопасности отмечают неуклонный рост как объема, так и сложности данных, которые генерируются в информационном пространстве, что неизбежно привело к росту количества кибератак, совершаемых не только против физических лиц, но и крупных компаний. Киберпреступники серьезно трансформировали свои методы и техники проведения атак, прибегая к технологиям ИИ. Традиционные технологии обеспечения информационной безопасности становятся малоэффективными либо вовсе неэффективными и убыточными. Поэтому специалисты все чаще прибегают к предиктивной аналитике, компьютерному зрению и профилированию пользователей с помощью ИИ в качестве инструментария для борьбы с киберпреступлениями.
В проекте «Интеллектуальный сканер протоколов обмена данными используемыми в сети «Интернет» Роскомнадзора предполагается использование технологий искусственного интеллекта (в частности, искусственных нейронных сетей) для выявления и вскрытия структуры новых протоколов обмена данными и составления сигнатур для работы с данными протоколами. Для обучения должны использоваться данные по известным протоколам передачи данных и алгоритмы байт-блочного моделирования сигнатур протоколов.
Целевыми результатами данного проекта являются:
- Приближение к реальному масштабу времени возможности выявления и блокирования новых протоколов обмена данными используемых для распространения запрещенной информации;
- Значительное сокращение объема распространяемой запрещенной информации в национальном сегменте сети «Интернет».
Программа по созданию аналитической системы прогнозирования рисков в медиаполе предполагает способность системы выявлять и анализировать большие объемы данных в русскоязычном информационном пространстве и формирование прогнозов развития рисков и угроз национальной безопасности РФ (риск возникновения межнациональной и религиозной напряженности, террористической угрозы, распространения fake news, иных информационных вбросов, репутационных рисков интересантов мониторинга и т.п.) в информационном пространстве в привязке к географическим и временным параметрам.
Для создания данной системы необходимо комплексное использование всех описанных ранее технологий ИИ: компьютерного зрения, распознавания речи, обработки естественного языка, системы поддержки принятия решений.
Реализация проекта предполагает формирование единого информационного пространства для всех действующих и разрабатываемых в настоящее время автоматизированных систем ведомства, осуществляющих государственные и контрольно-надзорные функции в отношении СМИ и СМК.
Неотъемлемыми этапами создания данной системы являются: сбор статьей и материалов СМИ, СМК и социальных сетей, содержащих текстовые, аудио- и видеофайлы и изображения, описывающих возникновение и развитие различных угроз и рисковых явлений и маркировка массива данных, используемого для обучения системы, которая позволит определять организаторов и каналы распространения информации, целевую аудиторию, конкретные текстовые, аудио- и видеоматериалы с признаками запрещенной информации, тональность контента, признаки нарушений конкретных НПА, а также тип риска/угрозы, его географическую привязку, прогнозируемые сроки развития и т.п.
- 1Natural Language Processing, обработка естественного языка
Похожие записи:
 Подходы и методы регулирования применения искусственного интеллекта и ответственности за эти действия
Подходы и методы регулирования применения искусственного интеллекта и ответственности за эти действия
 Стандартизация искусственного интеллекта в ЕС
Стандартизация искусственного интеллекта в ЕС
 Отчет о мониторинге правоприменения регулирования информационного пространства в странах мира в 2020 году
Отчет о мониторинге правоприменения регулирования информационного пространства в странах мира в 2020 году
 Объяснимый искусственный интеллект
Объяснимый искусственный интеллект
 Республика Индия
Республика Индия